 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWavelet-based Decoupling Framework for low-light Stereo Image Enhancement
Jul 16, 2025



Low-light images suffer from complex degradation, and existing enhancement methods often encode all degradation factors within a single latent space. This leads to highly entangled features and strong black-box characteristics, making the model prone to shortcut learning. To mitigate the above issues, this paper proposes a wavelet-based low-light stereo image enhancement method with feature space decoupling. Our insight comes from the following findings: (1) Wavelet transform enables the independent processing of low-frequency and high-frequency information. (2) Illumination adjustment can be achieved by adjusting the low-frequency component of a low-light image, extracted through multi-level wavelet decomposition. Thus, by using wavelet transform the feature space is decomposed into a low-frequency branch for illumination adjustment and multiple high-frequency branches for texture enhancement. Additionally, stereo low-light image enhancement can extract useful cues from another view to improve enhancement. To this end, we propose a novel high-frequency guided cross-view interaction module (HF-CIM) that operates within high-frequency branches rather than across the entire feature space, effectively extracting valuable image details from the other view. Furthermore, to enhance the high-frequency information, a detail and texture enhancement module (DTEM) is proposed based on cross-attention mechanism. The model is trained on a dataset consisting of images with uniform illumination and images with non-uniform illumination. Experimental results on both real and synthetic images indicate that our algorithm offers significant advantages in light adjustment while effectively recovering high-frequency information. The code and dataset are publicly available at: https://github.com/Cherisherr/WDCI-Net.git.
Mirror contrastive loss based sliding window transformer for subject-independent motor imagery based EEG signal recognition
Aug 29, 2024



While deep learning models have been extensively utilized in motor imagery based EEG signal recognition, they often operate as black boxes. Motivated by neurological findings indicating that the mental imagery of left or right-hand movement induces event-related desynchronization (ERD) in the contralateral sensorimotor area of the brain, we propose a Mirror Contrastive Loss based Sliding Window Transformer (MCL-SWT) to enhance subject-independent motor imagery-based EEG signal recognition. Specifically, our proposed mirror contrastive loss enhances sensitivity to the spatial location of ERD by contrasting the original EEG signals with their mirror counterparts-mirror EEG signals generated by interchanging the channels of the left and right hemispheres of the EEG signals. Moreover, we introduce a temporal sliding window transformer that computes self-attention scores from high temporal resolution features, thereby improving model performance with manageable computational complexity. We evaluate the performance of MCL-SWT on subject-independent motor imagery EEG signal recognition tasks, and our experimental results demonstrate that MCL-SWT achieved accuracies of 66.48% and 75.62%, surpassing the state-of-the-art (SOTA) model by 2.82% and 2.17%, respectively. Furthermore, ablation experiments confirm the effectiveness of the proposed mirror contrastive loss. A code demo of MCL-SWT is available at https://github.com/roniusLuo/MCL_SWT.
CGGAN: A Context Guided Generative Adversarial Network For Single Image Dehazing
May 28, 2020
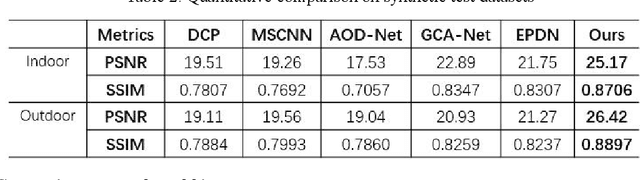
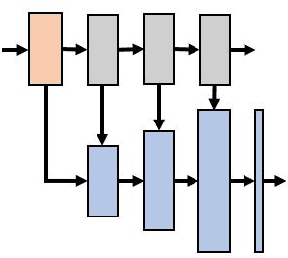
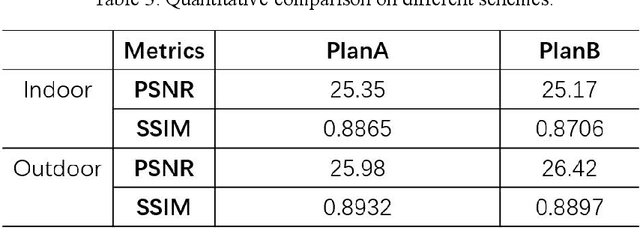
Image haze removal is highly desired for the application of computer vision. This paper proposes a novel Context Guided Generative Adversarial Network (CGGAN) for single image dehazing. Of which, an novel new encoder-decoder is employed as the generator. And it consists of a feature-extraction-net, a context-extractionnet, and a fusion-net in sequence. The feature extraction-net acts as a encoder, and is used for extracting haze features. The context-extraction net is a multi-scale parallel pyramid decoder, and is used for extracting the deep features of the encoder and generating coarse dehazing image. The fusion-net is a decoder, and is used for obtaining the final haze-free image. To obtain more better results, multi-scale information obtained during the decoding process of the context extraction decoder is used for guiding the fusion decoder. By introducing an extra coarse decoder to the original encoder-decoder, the CGGAN can make better use of the deep feature information extracted by the encoder. To ensure our CGGAN work effectively for different haze scenarios, different loss functions are employed for the two decoders. Experiments results show the advantage and the effectiveness of our proposed CGGAN, evidential improvements over existing state-of-the-art methods are obtained.
How to improve the interpretability of kernel learning
Nov 21, 2018In recent years, machine learning researchers have focused on methods to construct flexible and interpretable prediction models. However, the interpretability evaluation, the relationship between the generalization performance and the interpretability of the model and the method for improving the interpretability are very important factors to consider. In this paper, the quantitative index of the interpretability is proposed and its rationality is given, and the relationship between the interpretability and the generalization performance is analyzed. For traditional supervised kernel machine learning problem, a universal learning framework is put forward to solve the equilibrium problem between the two performances. The uniqueness of solution of the problem is proved and condition of unique solution is obtained. Probability upper bound of the sum of the two performances is analyzed.