 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Modalities: Joint Synthesis and Registration Framework for Aligning Diffusion MRI with T1-Weighted Images
Jan 16, 2026Multimodal image registration between diffusion MRI (dMRI) and T1-weighted (T1w) MRI images is a critical step for aligning diffusion-weighted imaging (DWI) data with structural anatomical space. Traditional registration methods often struggle to ensure accuracy due to the large intensity differences between diffusion data and high-resolution anatomical structures. This paper proposes an unsupervised registration framework based on a generative registration network, which transforms the original multimodal registration problem between b0 and T1w images into a unimodal registration task between a generated image and the real T1w image. This effectively reduces the complexity of cross-modal registration. The framework first employs an image synthesis model to generate images with T1w-like contrast, and then learns a deformation field from the generated image to the fixed T1w image. The registration network jointly optimizes local structural similarity and cross-modal statistical dependency to improve deformation estimation accuracy. Experiments conducted on two independent datasets demonstrate that the proposed method outperforms several state-of-the-art approaches in multimodal registration tasks.
BrainSegNet: A Novel Framework for Whole-Brain MRI Parcellation Enhanced by Large Models
Jan 14, 2026Whole-brain parcellation from MRI is a critical yet challenging task due to the complexity of subdividing the brain into numerous small, irregular shaped regions. Traditionally, template-registration methods were used, but recent advances have shifted to deep learning for faster workflows. While large models like the Segment Anything Model (SAM) offer transferable feature representations, they are not tailored for the high precision required in brain parcellation. To address this, we propose BrainSegNet, a novel framework that adapts SAM for accurate whole-brain parcellation into 95 regions. We enhance SAM by integrating U-Net skip connections and specialized modules into its encoder and decoder, enabling fine-grained anatomical precision. Key components include a hybrid encoder combining U-Net skip connections with SAM's transformer blocks, a multi-scale attention decoder with pyramid pooling for varying-sized structures, and a boundary refinement module to sharpen edges. Experimental results on the Human Connectome Project (HCP) dataset demonstrate that BrainSegNet outperforms several state-of-the-art methods, achieving higher accuracy and robustness in complex, multi-label parcellation.
LoLA: Long Horizon Latent Action Learning for General Robot Manipulation
Dec 23, 2025The capability of performing long-horizon, language-guided robotic manipulation tasks critically relies on leveraging historical information and generating coherent action sequences. However, such capabilities are often overlooked by existing Vision-Language-Action (VLA) models. To solve this challenge, we propose LoLA (Long Horizon Latent Action Learning), a framework designed for robot manipulation that integrates long-term multi-view observations and robot proprioception to enable multi-step reasoning and action generation. We first employ Vision-Language Models to encode rich contextual features from historical sequences and multi-view observations. We further introduces a key module, State-Aware Latent Re-representation, which transforms visual inputs and language commands into actionable robot motion space. Unlike existing VLA approaches that merely concatenate robot proprioception (e.g., joint angles) with VL embeddings, this module leverages such robot states to explicitly ground VL representations in physical scale through a learnable "embodiment-anchored" latent space. We trained LoLA on diverse robotic pre-training datasets and conducted extensive evaluations on simulation benchmarks (SIMPLER and LIBERO), as well as two real-world tasks on Franka and Bi-Manual Aloha robots. Results show that LoLA significantly outperforms prior state-of-the-art methods (e.g., pi0), particularly in long-horizon manipulation tasks.
Label-efficient Single Photon Images Classification via Active Learning
May 07, 2025Single-photon LiDAR achieves high-precision 3D imaging in extreme environments through quantum-level photon detection technology. Current research primarily focuses on reconstructing 3D scenes from sparse photon events, whereas the semantic interpretation of single-photon images remains underexplored, due to high annotation costs and inefficient labeling strategies. This paper presents the first active learning framework for single-photon image classification. The core contribution is an imaging condition-aware sampling strategy that integrates synthetic augmentation to model variability across imaging conditions. By identifying samples where the model is both uncertain and sensitive to these conditions, the proposed method selectively annotates only the most informative examples. Experiments on both synthetic and real-world datasets show that our approach outperforms all baselines and achieves high classification accuracy with significantly fewer labeled samples. Specifically, our approach achieves 97% accuracy on synthetic single-photon data using only 1.5% labeled samples. On real-world data, we maintain 90.63% accuracy with just 8% labeled samples, which is 4.51% higher than the best-performing baseline. This illustrates that active learning enables the same level of classification performance on single-photon images as on classical images, opening doors to large-scale integration of single-photon data in real-world applications.
CogACT: A Foundational Vision-Language-Action Model for Synergizing Cognition and Action in Robotic Manipulation
Nov 29, 2024



The advancement of large Vision-Language-Action (VLA) models has significantly improved robotic manipulation in terms of language-guided task execution and generalization to unseen scenarios. While existing VLAs adapted from pretrained large Vision-Language-Models (VLM) have demonstrated promising generalizability, their task performance is still unsatisfactory as indicated by the low tasks success rates in different environments. In this paper, we present a new advanced VLA architecture derived from VLM. Unlike previous works that directly repurpose VLM for action prediction by simple action quantization, we propose a omponentized VLA architecture that has a specialized action module conditioned on VLM output. We systematically study the design of the action module and demonstrates the strong performance enhancement with diffusion action transformers for action sequence modeling, as well as their favorable scaling behaviors. We also conduct comprehensive experiments and ablation studies to evaluate the efficacy of our models with varied designs. The evaluation on 5 robot embodiments in simulation and real work shows that our model not only significantly surpasses existing VLAs in task performance and but also exhibits remarkable adaptation to new robots and generalization to unseen objects and backgrounds. It exceeds the average success rates of OpenVLA which has similar model size (7B) with ours by over 35% in simulated evaluation and 55% in real robot experiments. It also outperforms the large RT-2-X model (55B) by 18% absolute success rates in simulation. Code and models can be found on our project page (https://cogact.github.io/).
DiffRoad: Realistic and Diverse Road Scenario Generation for Autonomous Vehicle Testing
Nov 14, 2024


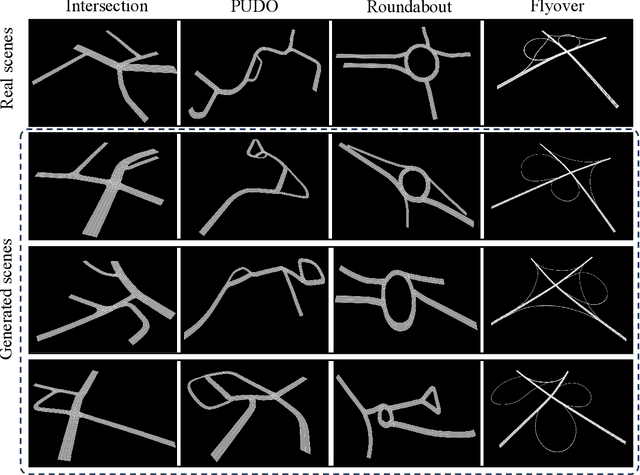
Generating realistic and diverse road scenarios is essential for autonomous vehicle testing and validation. Nevertheless, owing to the complexity and variability of real-world road environments, creating authentic and varied scenarios for intelligent driving testing is challenging. In this paper, we propose DiffRoad, a novel diffusion model designed to produce controllable and high-fidelity 3D road scenarios. DiffRoad leverages the generative capabilities of diffusion models to synthesize road layouts from white noise through an inverse denoising process, preserving real-world spatial features. To enhance the quality of generated scenarios, we design the Road-UNet architecture, optimizing the balance between backbone and skip connections for high-realism scenario generation. Furthermore, we introduce a road scenario evaluation module that screens adequate and reasonable scenarios for intelligent driving testing using two critical metrics: road continuity and road reasonableness. Experimental results on multiple real-world datasets demonstrate DiffRoad's ability to generate realistic and smooth road structures while maintaining the original distribution. Additionally, the generated scenarios can be fully automated into the OpenDRIVE format, facilitating generalized autonomous vehicle simulation testing. DiffRoad provides a rich and diverse scenario library for large-scale autonomous vehicle testing and offers valuable insights for future infrastructure designs that are better suited for autonomous vehicles.
Mirror contrastive loss based sliding window transformer for subject-independent motor imagery based EEG signal recognition
Aug 29, 2024



While deep learning models have been extensively utilized in motor imagery based EEG signal recognition, they often operate as black boxes. Motivated by neurological findings indicating that the mental imagery of left or right-hand movement induces event-related desynchronization (ERD) in the contralateral sensorimotor area of the brain, we propose a Mirror Contrastive Loss based Sliding Window Transformer (MCL-SWT) to enhance subject-independent motor imagery-based EEG signal recognition. Specifically, our proposed mirror contrastive loss enhances sensitivity to the spatial location of ERD by contrasting the original EEG signals with their mirror counterparts-mirror EEG signals generated by interchanging the channels of the left and right hemispheres of the EEG signals. Moreover, we introduce a temporal sliding window transformer that computes self-attention scores from high temporal resolution features, thereby improving model performance with manageable computational complexity. We evaluate the performance of MCL-SWT on subject-independent motor imagery EEG signal recognition tasks, and our experimental results demonstrate that MCL-SWT achieved accuracies of 66.48% and 75.62%, surpassing the state-of-the-art (SOTA) model by 2.82% and 2.17%, respectively. Furthermore, ablation experiments confirm the effectiveness of the proposed mirror contrastive loss. A code demo of MCL-SWT is available at https://github.com/roniusLuo/MCL_SWT.
Structured Deep Neural Networks-Based Backstepping Trajectory Tracking Control for Lagrangian Systems
Mar 01, 2024Deep neural networks (DNN) are increasingly being used to learn controllers due to their excellent approximation capabilities. However, their black-box nature poses significant challenges to closed-loop stability guarantees and performance analysis. In this paper, we introduce a structured DNN-based controller for the trajectory tracking control of Lagrangian systems using backing techniques. By properly designing neural network structures, the proposed controller can ensure closed-loop stability for any compatible neural network parameters. In addition, improved control performance can be achieved by further optimizing neural network parameters. Besides, we provide explicit upper bounds on tracking errors in terms of controller parameters, which allows us to achieve the desired tracking performance by properly selecting the controller parameters. Furthermore, when system models are unknown, we propose an improved Lagrangian neural network (LNN) structure to learn the system dynamics and design the controller. We show that in the presence of model approximation errors and external disturbances, the closed-loop stability and tracking control performance can still be guaranteed. The effectiveness of the proposed approach is demonstrated through simulations.
Learning Bifunctional Push-grasping Synergistic Strategy for Goal-agnostic and Goal-oriented Tasks
Dec 04, 2022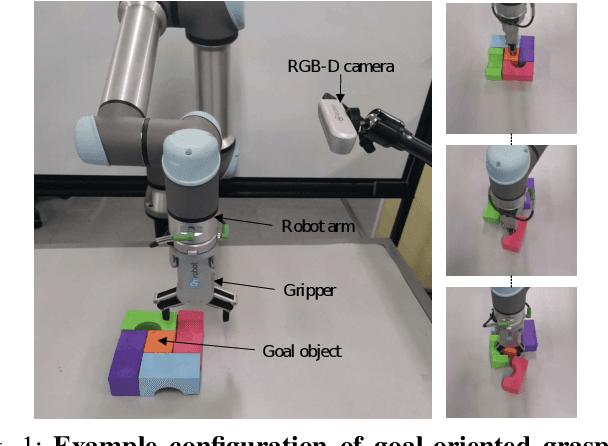
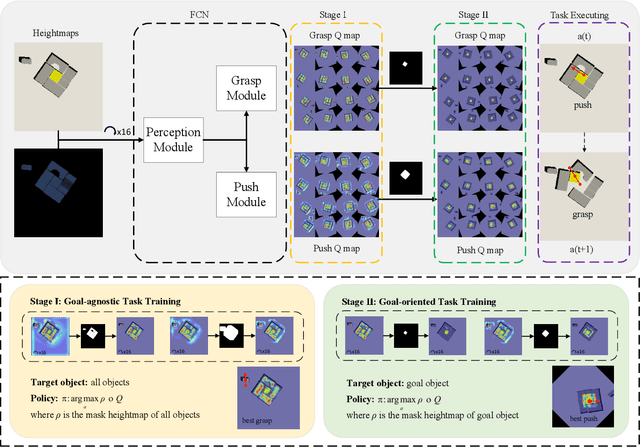
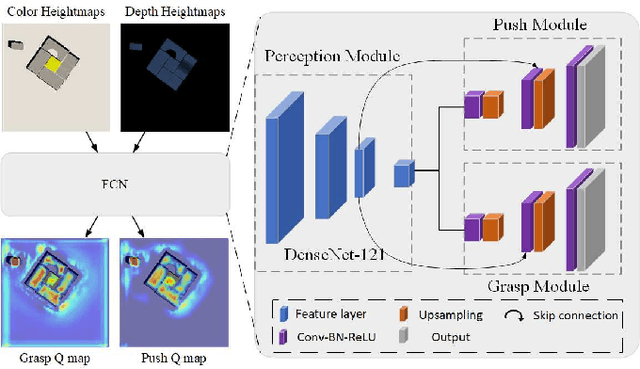

Both goal-agnostic and goal-oriented tasks have practical value for robotic grasping: goal-agnostic tasks target all objects in the workspace, while goal-oriented tasks aim at grasping pre-assigned goal objects. However, most current grasping methods are only better at coping with one task. In this work, we propose a bifunctional push-grasping synergistic strategy for goal-agnostic and goal-oriented grasping tasks. Our method integrates pushing along with grasping to pick up all objects or pre-assigned goal objects with high action efficiency depending on the task requirement. We introduce a bifunctional network, which takes in visual observations and outputs dense pixel-wise maps of Q values for pushing and grasping primitive actions, to increase the available samples in the action space. Then we propose a hierarchical reinforcement learning framework to coordinate the two tasks by considering the goal-agnostic task as a combination of multiple goal-oriented tasks. To reduce the training difficulty of the hierarchical framework, we design a two-stage training method to train the two types of tasks separately. We perform pre-training of the model in simulation, and then transfer the learned model to the real world without any additional real-world fine-tuning. Experimental results show that the proposed approach outperforms existing methods in task completion rate and grasp success rate with less motion number. Supplementary material is available at https: //github.com/DafaRen/Learning_Bifunctional_Push-grasping_Synergistic_Strategy_for_Goal-agnostic_and_Goal-oriented_Tasks
Autoregressive GNN-ODE GRU Model for Network Dynamics
Nov 19, 2022Revealing the continuous dynamics on the networks is essential for understanding, predicting, and even controlling complex systems, but it is hard to learn and model the continuous network dynamics because of complex and unknown governing equations, high dimensions of complex systems, and unsatisfactory observations. Moreover, in real cases, observed time-series data are usually non-uniform and sparse, which also causes serious challenges. In this paper, we propose an Autoregressive GNN-ODE GRU Model (AGOG) to learn and capture the continuous network dynamics and realize predictions of node states at an arbitrary time in a data-driven manner. The GNN module is used to model complicated and nonlinear network dynamics. The hidden state of node states is specified by the ODE system, and the augmented ODE system is utilized to map the GNN into the continuous time domain. The hidden state is updated through GRUCell by observations. As prior knowledge, the true observations at the same timestamp are combined with the hidden states for the next prediction. We use the autoregressive model to make a one-step ahead prediction based on observation history. The prediction is achieved by solving an initial-value problem for ODE. To verify the performance of our model, we visualize the learned dynamics and test them in three tasks: interpolation reconstruction, extrapolation prediction, and regular sequences prediction. The results demonstrate that our model can capture the continuous dynamic process of complex systems accurately and make precise predictions of node states with minimal error. Our model can consistently outperform other baselines or achieve comparable performance.