 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Bifunctional Push-grasping Synergistic Strategy for Goal-agnostic and Goal-oriented Tasks
Dec 04, 2022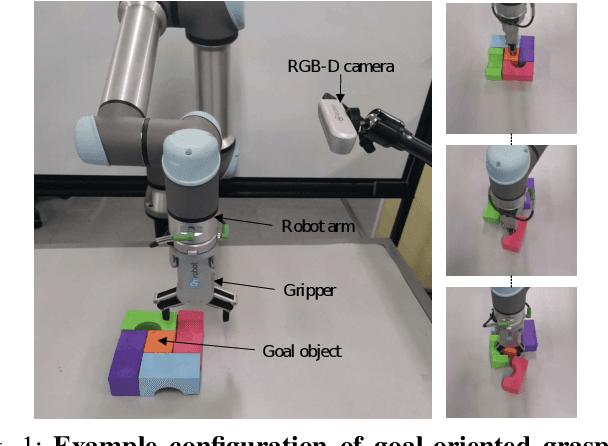
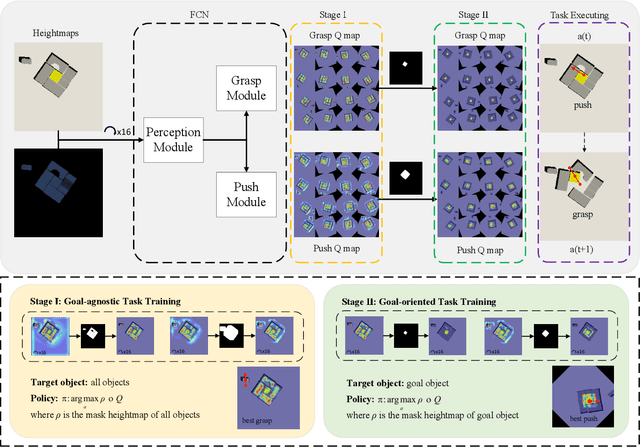
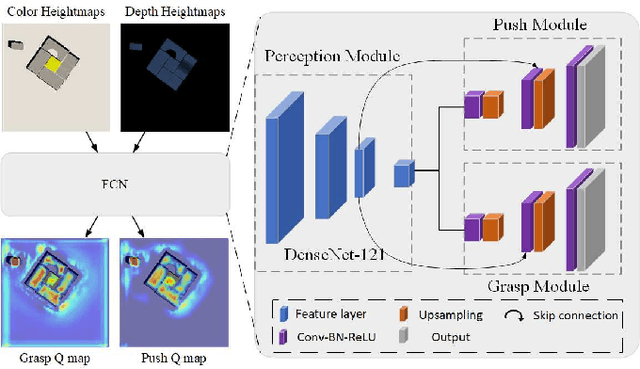

Both goal-agnostic and goal-oriented tasks have practical value for robotic grasping: goal-agnostic tasks target all objects in the workspace, while goal-oriented tasks aim at grasping pre-assigned goal objects. However, most current grasping methods are only better at coping with one task. In this work, we propose a bifunctional push-grasping synergistic strategy for goal-agnostic and goal-oriented grasping tasks. Our method integrates pushing along with grasping to pick up all objects or pre-assigned goal objects with high action efficiency depending on the task requirement. We introduce a bifunctional network, which takes in visual observations and outputs dense pixel-wise maps of Q values for pushing and grasping primitive actions, to increase the available samples in the action space. Then we propose a hierarchical reinforcement learning framework to coordinate the two tasks by considering the goal-agnostic task as a combination of multiple goal-oriented tasks. To reduce the training difficulty of the hierarchical framework, we design a two-stage training method to train the two types of tasks separately. We perform pre-training of the model in simulation, and then transfer the learned model to the real world without any additional real-world fine-tuning. Experimental results show that the proposed approach outperforms existing methods in task completion rate and grasp success rate with less motion number. Supplementary material is available at https: //github.com/DafaRen/Learning_Bifunctional_Push-grasping_Synergistic_Strategy_for_Goal-agnostic_and_Goal-oriented_Tasks
Fast-Learning Grasping and Pre-Grasping via Clutter Quantization and Q-map Masking
Jul 06, 2021
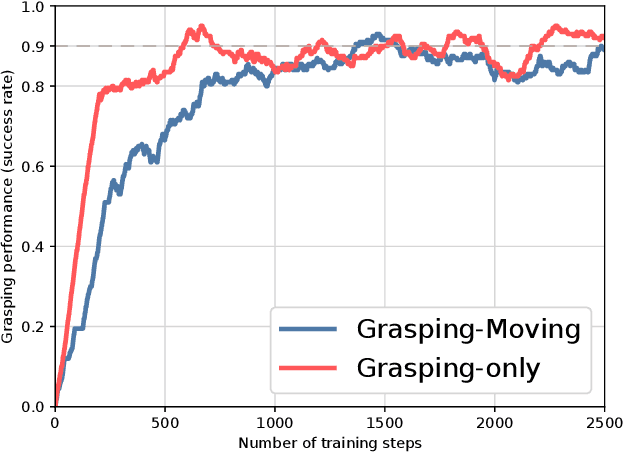

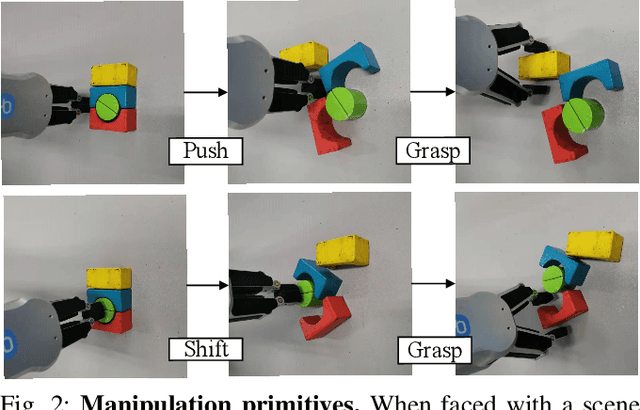
Grasping objects in cluttered scenarios is a challenging task in robotics. Performing pre-grasp actions such as pushing and shifting to scatter objects is a way to reduce clutter. Based on deep reinforcement learning, we propose a Fast-Learning Grasping (FLG) framework, that can integrate pre-grasping actions along with grasping to pick up objects from cluttered scenarios with reduced real-world training time. We associate rewards for performing moving actions with the change of environmental clutter and utilize a hybrid triggering method, leading to data-efficient learning and synergy. Then we use the output of an extended fully convolutional network as the value function of each pixel point of the workspace and establish an accurate estimation of the grasp probability for each action. We also introduce a mask function as prior knowledge to enable the agents to focus on the accurate pose adjustment to improve the effectiveness of collecting training data and, hence, to learn efficiently. We carry out pre-training of the FLG over simulated environment, and then the learnt model is transferred to the real world with minimal fine-tuning for further learning during actions. Experimental results demonstrate a 94% grasp success rate and the ability to generalize to novel objects. Compared to state-of-the-art approaches in the literature, the proposed FLG framework can achieve similar or higher grasp success rate with lesser amount of training in the real world. Supplementary video is available at https://youtu.be/e04uDLsxfDg.