 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel-efficient Single Photon Images Classification via Active Learning
May 07, 2025Single-photon LiDAR achieves high-precision 3D imaging in extreme environments through quantum-level photon detection technology. Current research primarily focuses on reconstructing 3D scenes from sparse photon events, whereas the semantic interpretation of single-photon images remains underexplored, due to high annotation costs and inefficient labeling strategies. This paper presents the first active learning framework for single-photon image classification. The core contribution is an imaging condition-aware sampling strategy that integrates synthetic augmentation to model variability across imaging conditions. By identifying samples where the model is both uncertain and sensitive to these conditions, the proposed method selectively annotates only the most informative examples. Experiments on both synthetic and real-world datasets show that our approach outperforms all baselines and achieves high classification accuracy with significantly fewer labeled samples. Specifically, our approach achieves 97% accuracy on synthetic single-photon data using only 1.5% labeled samples. On real-world data, we maintain 90.63% accuracy with just 8% labeled samples, which is 4.51% higher than the best-performing baseline. This illustrates that active learning enables the same level of classification performance on single-photon images as on classical images, opening doors to large-scale integration of single-photon data in real-world applications.
TERL: Large-Scale Multi-Target Encirclement Using Transformer-Enhanced Reinforcement Learning
Mar 16, 2025



Pursuit-evasion (PE) problem is a critical challenge in multi-robot systems (MRS). While reinforcement learning (RL) has shown its promise in addressing PE tasks, research has primarily focused on single-target pursuit, with limited exploration of multi-target encirclement, particularly in large-scale settings. This paper proposes a Transformer-Enhanced Reinforcement Learning (TERL) framework for large-scale multi-target encirclement. By integrating a transformer-based policy network with target selection, TERL enables robots to adaptively prioritize targets and safely coordinate robots. Results show that TERL outperforms existing RL-based methods in terms of encirclement success rate and task completion time, while maintaining good performance in large-scale scenarios. Notably, TERL, trained on small-scale scenarios (15 pursuers, 4 targets), generalizes effectively to large-scale settings (80 pursuers, 20 targets) without retraining, achieving a 100% success rate.
Fast Estimation of Relative Transformation Based on Fusion of Odometry and UWB Ranging Data
May 21, 2024
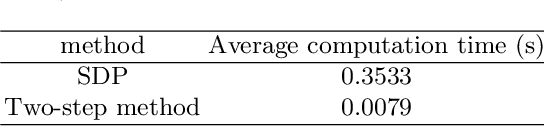
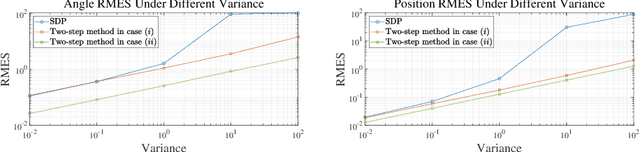

In this paper, we investigate the problem of estimating the 4-DOF (three-dimensional position and orientation) robot-robot relative frame transformation using odometers and distance measurements between robots. Firstly, we apply a two-step estimation method based on maximum likelihood estimation. Specifically, a good initial value is obtained through unconstrained least squares and projection, followed by a more accurate estimate achieved through one-step Gauss-Newton iteration. Additionally, the optimal installation positions of Ultra-Wideband (UWB) are provided, and the minimum operating time under different quantities of UWB devices is determined. Simulation demonstrates that the two-step approach offers faster computation with guaranteed accuracy while effectively addressing the relative transformation estimation problem within limited space constraints. Furthermore, this method can be applied to real-time relative transformation estimation when a specific number of UWB devices are installed.
Structured Deep Neural Networks-Based Backstepping Trajectory Tracking Control for Lagrangian Systems
Mar 01, 2024Deep neural networks (DNN) are increasingly being used to learn controllers due to their excellent approximation capabilities. However, their black-box nature poses significant challenges to closed-loop stability guarantees and performance analysis. In this paper, we introduce a structured DNN-based controller for the trajectory tracking control of Lagrangian systems using backing techniques. By properly designing neural network structures, the proposed controller can ensure closed-loop stability for any compatible neural network parameters. In addition, improved control performance can be achieved by further optimizing neural network parameters. Besides, we provide explicit upper bounds on tracking errors in terms of controller parameters, which allows us to achieve the desired tracking performance by properly selecting the controller parameters. Furthermore, when system models are unknown, we propose an improved Lagrangian neural network (LNN) structure to learn the system dynamics and design the controller. We show that in the presence of model approximation errors and external disturbances, the closed-loop stability and tracking control performance can still be guaranteed. The effectiveness of the proposed approach is demonstrated through simulations.
Efficient Invariant Kalman Filter for Inertial-based Odometry with Large-sample Environmental Measurements
Feb 07, 2024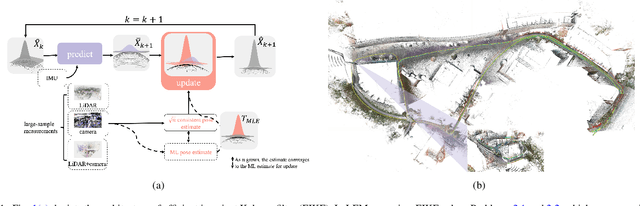
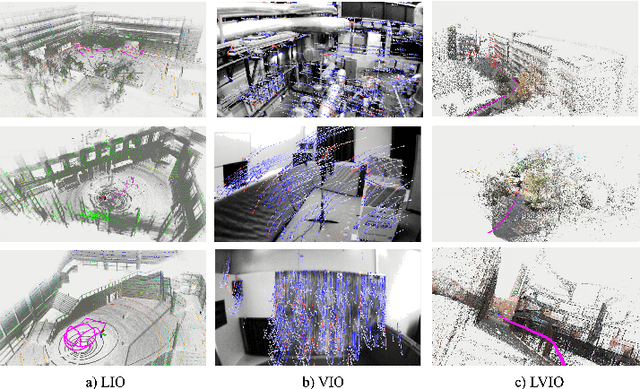
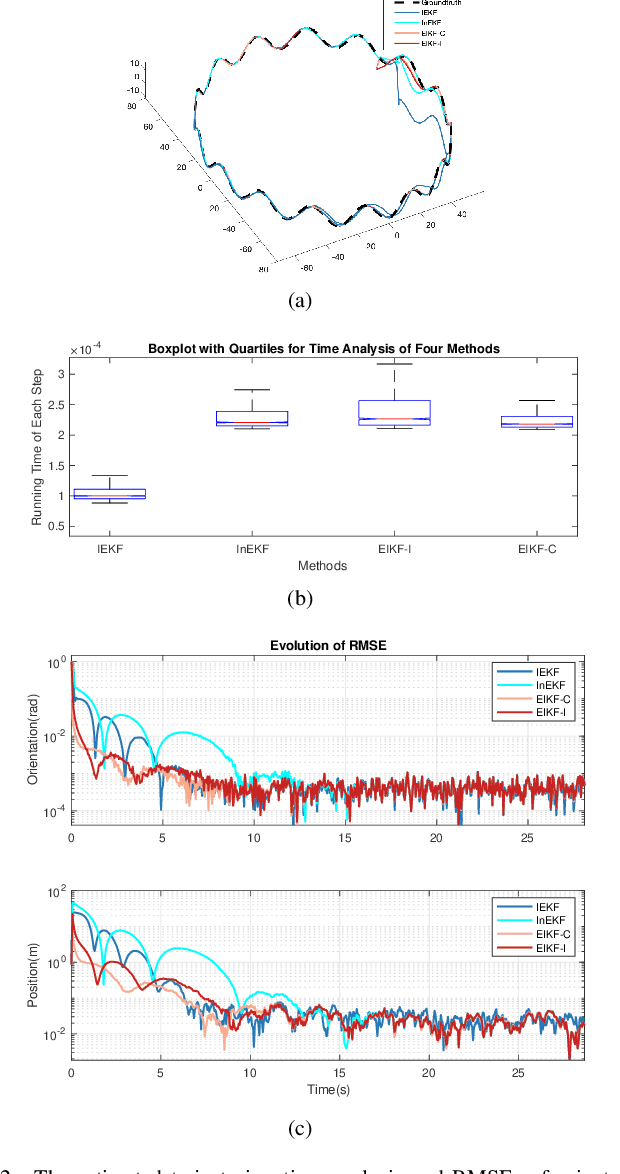
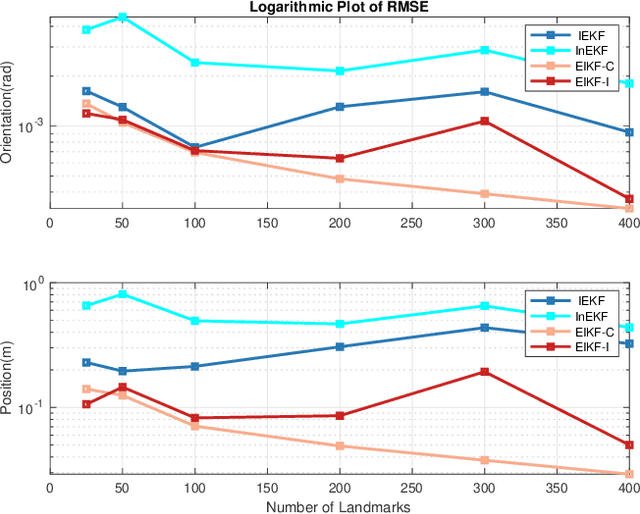
A filter for inertial-based odometry is a recursive method used to estimate the pose from measurements of ego-motion and relative pose. Currently, there is no known filter that guarantees the computation of a globally optimal solution for the non-linear measurement model. In this paper, we demonstrate that an innovative filter, with the state being $SE_2(3)$ and the $\sqrt{n}$-\textit{consistent} pose as the initialization, efficiently achieves \textit{asymptotic optimality} in terms of minimum mean square error. This approach is tailored for real-time SLAM and inertial-based odometry applications. Our first contribution is that we propose an iterative filtering method based on the Gauss-Newton method on Lie groups which is numerically to solve the estimation of states from a priori and non-linear measurements. The filtering stands out due to its iterative mechanism and adaptive initialization. Second, when dealing with environmental measurements of the surroundings, we utilize a $\sqrt{n}$-consistent pose as the initial value for the update step in a single iteration. The solution is closed in form and has computational complexity $O(n)$. Third, we theoretically show that the approach can achieve asymptotic optimality in the sense of minimum mean square error from the a priori and virtual relative pose measurements (see Problem~\ref{prob:new update problem}). Finally, to validate our method, we carry out extensive numerical and experimental evaluations. Our results consistently demonstrate that our approach outperforms other state-of-the-art filter-based methods, including the iterated extended Kalman filter and the invariant extended Kalman filter, in terms of accuracy and running time.
Learning Bifunctional Push-grasping Synergistic Strategy for Goal-agnostic and Goal-oriented Tasks
Dec 04, 2022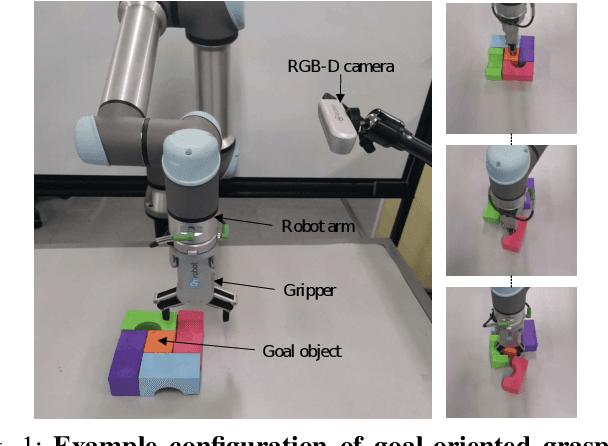
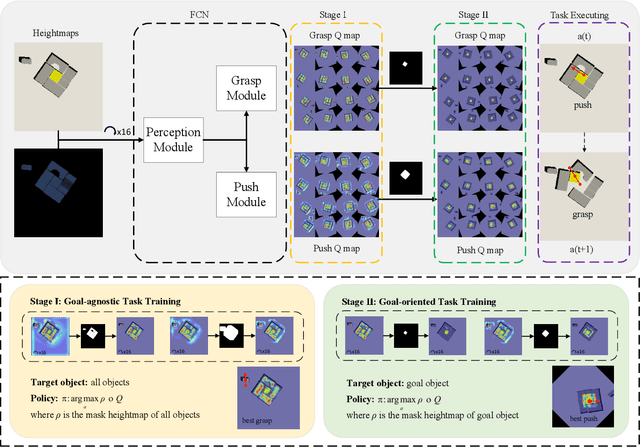
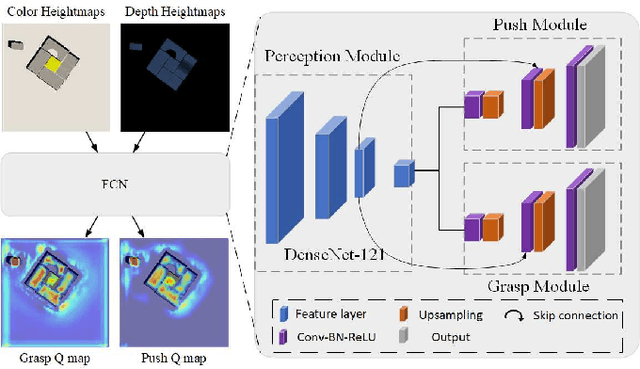

Both goal-agnostic and goal-oriented tasks have practical value for robotic grasping: goal-agnostic tasks target all objects in the workspace, while goal-oriented tasks aim at grasping pre-assigned goal objects. However, most current grasping methods are only better at coping with one task. In this work, we propose a bifunctional push-grasping synergistic strategy for goal-agnostic and goal-oriented grasping tasks. Our method integrates pushing along with grasping to pick up all objects or pre-assigned goal objects with high action efficiency depending on the task requirement. We introduce a bifunctional network, which takes in visual observations and outputs dense pixel-wise maps of Q values for pushing and grasping primitive actions, to increase the available samples in the action space. Then we propose a hierarchical reinforcement learning framework to coordinate the two tasks by considering the goal-agnostic task as a combination of multiple goal-oriented tasks. To reduce the training difficulty of the hierarchical framework, we design a two-stage training method to train the two types of tasks separately. We perform pre-training of the model in simulation, and then transfer the learned model to the real world without any additional real-world fine-tuning. Experimental results show that the proposed approach outperforms existing methods in task completion rate and grasp success rate with less motion number. Supplementary material is available at https: //github.com/DafaRen/Learning_Bifunctional_Push-grasping_Synergistic_Strategy_for_Goal-agnostic_and_Goal-oriented_Tasks
Efficient Planar Pose Estimation via UWB Measurements
Sep 15, 2022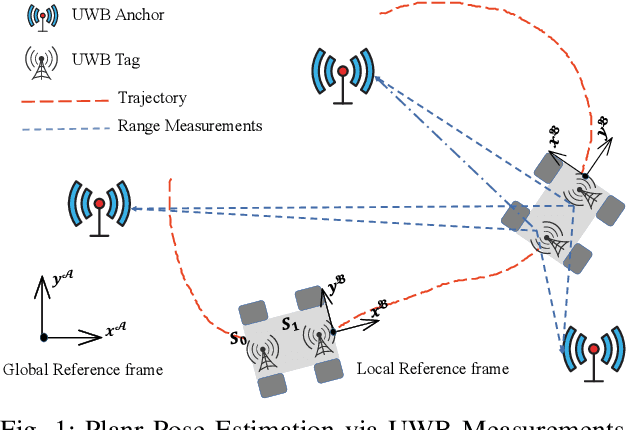
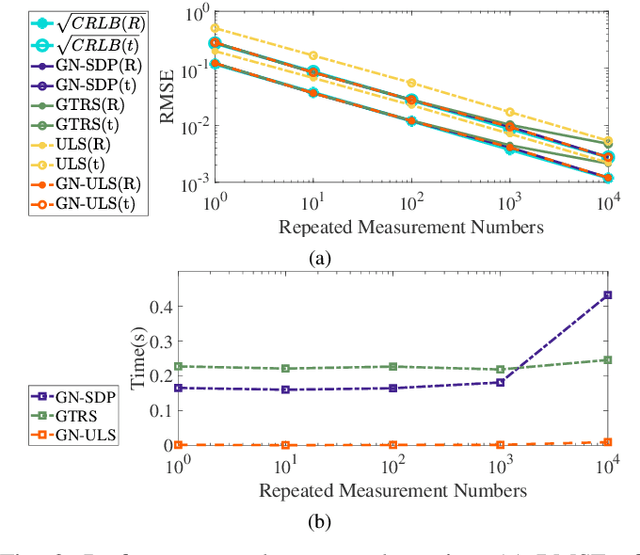
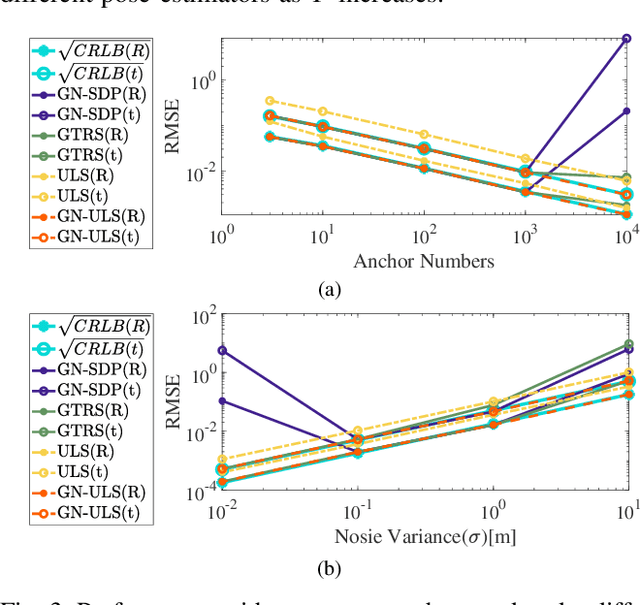

State estimation is an essential part of autonomous systems. Integrating the Ultra-Wideband(UWB) technique has been shown to correct the long-term estimation drift and bypass the complexity of loop closure detection. However, few works on robotics adopt UWB as a stand-alone state estimation solution. The primary purpose of this work is to investigate planar pose estimation using only UWB range measurements and study the estimator's statistical efficiency. We prove the excellent property of a two-step scheme, which says that we can refine a consistent estimator to be asymptotically efficient by one step of Gauss-Newton iteration. Grounded on this result, we design the GN-ULS estimator and evaluate it through simulations and collected datasets. GN-ULS attains millimeter and sub-degree level accuracy on our static datasets and attains centimeter and degree level accuracy on our dynamic datasets, presenting the possibility of using only UWB for real-time state estimation.
Autonomous Highway Merging in Mixed Traffic Using Reinforcement Learning and Motion Predictive Safety Controller
Apr 03, 2022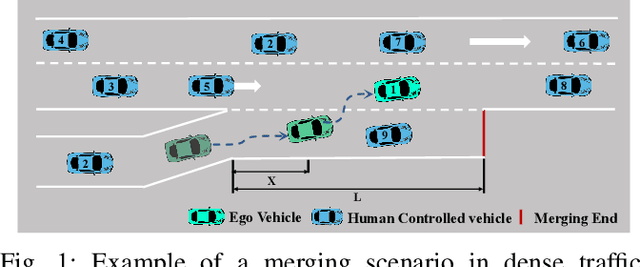
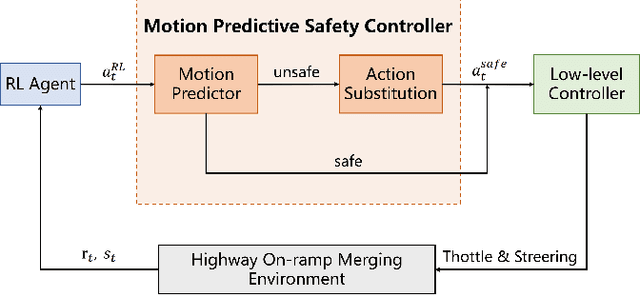
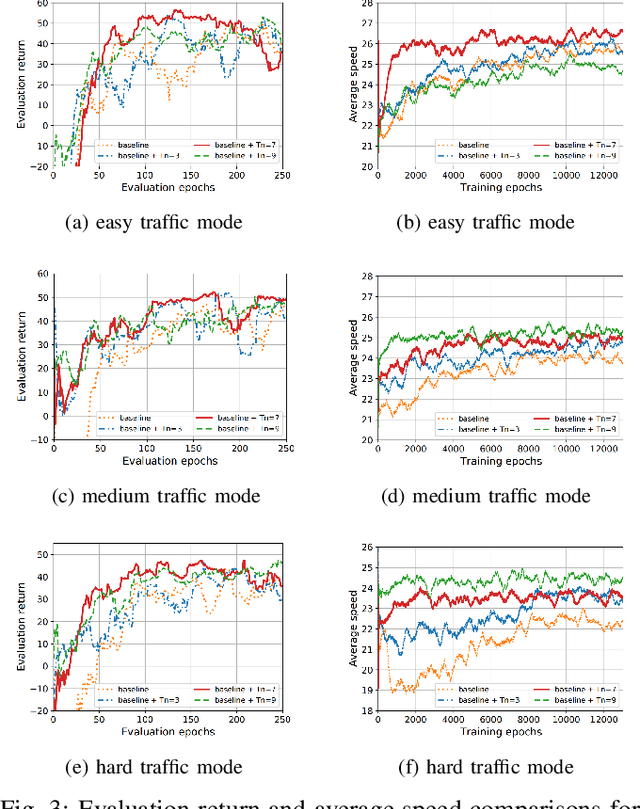
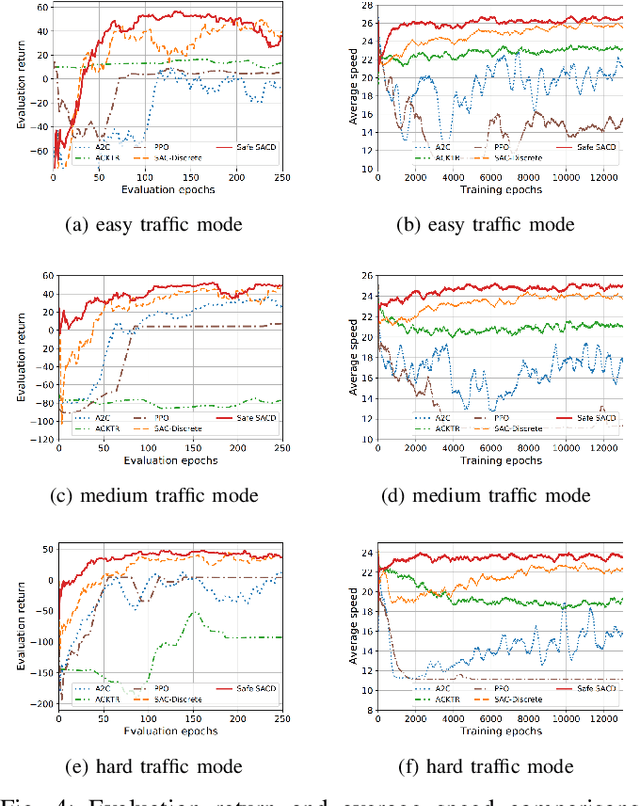
Deep reinforcement learning (DRL) has a great potential for solving complex decision-making problems in autonomous driving, especially in mixed-traffic scenarios where autonomous vehicles and human-driven vehicles (HDVs) drive together. Safety is a key during both the learning and deploying reinforcement learning (RL) algorithms process. In this paper, we formulate the on-ramp merging as a Markov Decision Process (MDP) problem and solve it with an off-policy RL algorithm, i.e., Soft Actor-Critic for Discrete Action Settings (SAC-Discrete). In addition, a motion predictive safety controller including a motion predictor and an action substitution module, is proposed to ensure driving safety during both training and testing. The motion predictor estimates the trajectories of the ego vehicle and surrounding vehicles from kinematic models, and predicts potential collisions. The action substitution module updates the actions based on safety distance and replaces risky actions, before sending them to the low-level controller. We train, evaluate and test our approach on a gym-like highway simulation with three different levels of traffic modes. The simulation results show that even in harder traffic densities, our proposed method still significantly reduces collision rate while maintaining high efficiency, outperforming several state-of-the-art baselines in the considered on-ramp merging scenarios. The video demo of the evaluation process can be found at: https://www.youtube.com/watch?v=7FvjbAM4oFw
Aggressive Racecar Drifting Control Using Onboard Cameras and Inertial Measurement Unit
Feb 28, 2022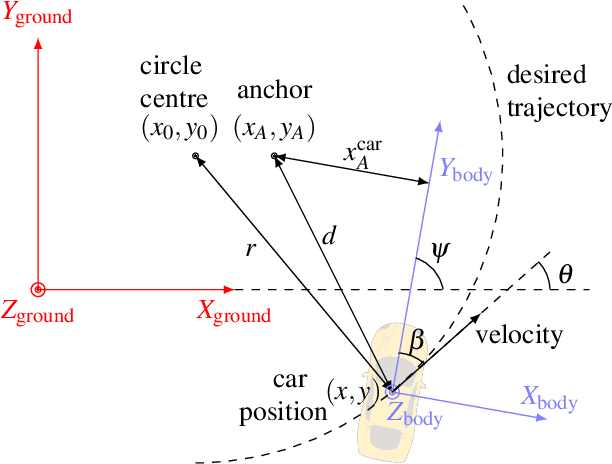
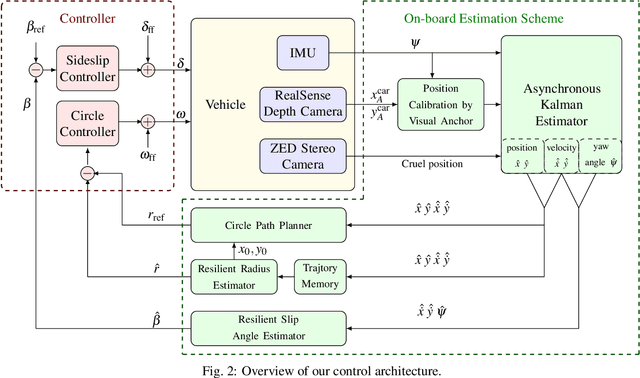
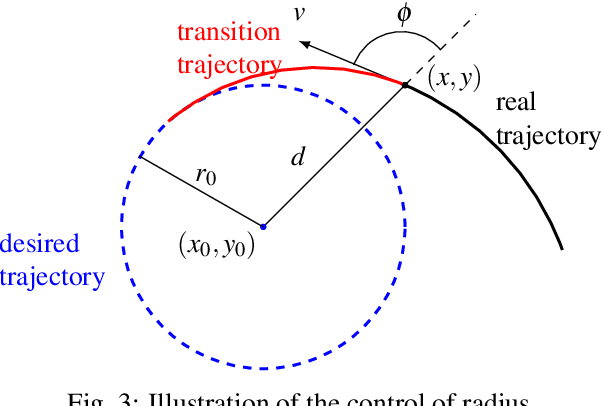

Complex autonomous driving, such as drifting, requires high-precision and high-frequency pose information to ensure accuracy and safety, which is notably difficult when using only onboard sensors. In this paper, we propose a drift controller with two feedback control loops: sideslip controller that stabilizes the sideslip angle by tuning the front wheel steering angle, and circle controller that maintains a stable trajectory radius and circle center by controlling the wheel rotational speed. We use an extended Kalman filter to estimate the state. A robustified KASA algorithm is further proposed to accurately estimate the parameters of the circle (i.e., the center and radius) that best fits into the current trajectory. On the premise of the uniform circular motion of the vehicle in the process of stable drift, we use angle information instead of acceleration to describe the dynamic of the vehicle. We implement our method on a 1/10 scale race car. The car drifts stably with a given center and radius, which illustrates the effectiveness of our method.
Fast-Learning Grasping and Pre-Grasping via Clutter Quantization and Q-map Masking
Jul 06, 2021
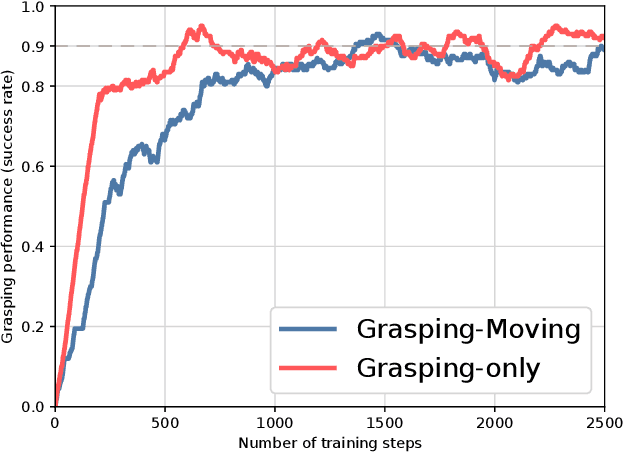

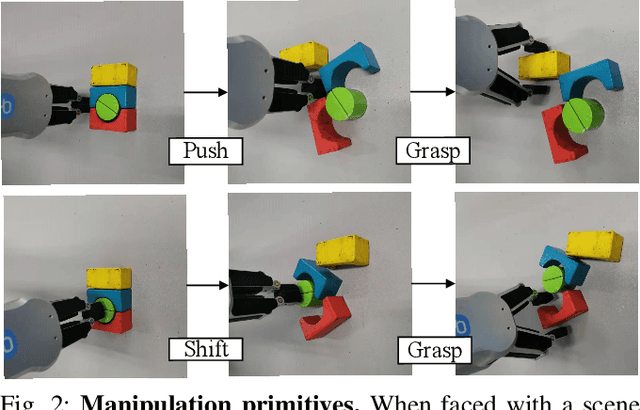
Grasping objects in cluttered scenarios is a challenging task in robotics. Performing pre-grasp actions such as pushing and shifting to scatter objects is a way to reduce clutter. Based on deep reinforcement learning, we propose a Fast-Learning Grasping (FLG) framework, that can integrate pre-grasping actions along with grasping to pick up objects from cluttered scenarios with reduced real-world training time. We associate rewards for performing moving actions with the change of environmental clutter and utilize a hybrid triggering method, leading to data-efficient learning and synergy. Then we use the output of an extended fully convolutional network as the value function of each pixel point of the workspace and establish an accurate estimation of the grasp probability for each action. We also introduce a mask function as prior knowledge to enable the agents to focus on the accurate pose adjustment to improve the effectiveness of collecting training data and, hence, to learn efficiently. We carry out pre-training of the FLG over simulated environment, and then the learnt model is transferred to the real world with minimal fine-tuning for further learning during actions. Experimental results demonstrate a 94% grasp success rate and the ability to generalize to novel objects. Compared to state-of-the-art approaches in the literature, the proposed FLG framework can achieve similar or higher grasp success rate with lesser amount of training in the real world. Supplementary video is available at https://youtu.be/e04uDLsxfDg.