 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltraEP: Unleash MoE Training and Inference on Rack-Scale Nodes with Near-Optimal Load Balancing
Jun 02, 2026Large-scale expert parallelism (EP) is becoming pivotal for training and serving frontier MoE models, but it also amplifies device-level expert load imbalance into compute stragglers, token all-to-all bottlenecks, and activation-memory spikes. Existing balancers redistribute experts periodically based on historical load, which becomes unreliable for production deployments with non-stationary load patterns. We present UltraEP, the first exact-load, real-time balancer for large-EP MoE training and serving prefill on rack-scale nodes (RSNs). Built upon the extended scale-up connectivity of RSNs, UltraEP rebalances every microbatch and layer on critical paths, which requires nontrivial co-design of plan solving and expert replication communication to minimize exposed overhead. To this end, UltraEP eagerly reacts to post-gating load with efficient quota-driven planning, and executes the resulting irregular expert-state transfers with RSN-native persistent tile streaming and relay-based fan-out mitigation. Averaged across MoE models from 106B to 671B parameters in training and prefill, UltraEP achieves 94.3% of the force-balanced ideal throughput, delivering 1.49$\times$ improvement over non-balancing, while reducing the final inter-rank imbalance from 1.30$-$4.01 to 1.01$-$1.04. Additionally, we validate UltraEP's scalability and robustness in production MoE training with 2560 GPUs.
BigMac: Breaking the Pareto Frontier of Compute and Memory in Multimodal LLM Training
May 25, 2026Training multimodal large language models (MLLMs) is challenged by both model and data heterogeneity. Existing systems redesign the training pipeline to address these challenges, but remain bound by a Pareto frontier between compute and memory efficiency, improving one only at the expense of the other. We present BigMac, a new training pipeline for multimodal LLMs. The core idea of BigMac is to elegantly nest the encoder and generator computation into the original LLM pipeline, forming a dependency-safe nested pipeline structure. With this design, BigMac reduces the activation memory complexity of the encoder and generator to O(1) while keeping the activation memory complexity of the LLM unchanged. At the same time, it achieves the same computational efficiency as the idealized setting with unlimited memory. As a result, BigMac breaks the Pareto frontier between computational efficiency and memory usage, enabling simultaneous optimization of both computation and memory in MLLM training. We evaluate BigMac on multiple MLLMs and training workloads. Experimental results show that BigMac achieves a 1.08$\times$-1.9$\times$ training speedup over baseline systems while maintaining stable memory usage as batch size increases.
Heddle: A Distributed Orchestration System for Agentic RL Rollout
Mar 30, 2026Agentic Reinforcement Learning (RL) enables LLMs to solve complex tasks by alternating between a data-collection rollout phase and a policy training phase. During rollout, the agent generates trajectories, i.e., multi-step interactions between LLMs and external tools. Yet, frequent tool calls induce long-tailed trajectory generation that bottlenecks rollouts. This stems from step-centric designs that ignore trajectory context, triggering three system problems for long-tail trajectory generation: queueing delays, interference overhead, and inflated per-token time. We propose Heddle, a trajectory-centric system to optimize the when, where, and how of agentic rollout execution. Heddle integrates three core mechanisms: trajectory-level scheduling using runtime prediction and progressive priority to minimize cumulative queueing; trajectory-aware placement via presorted dynamic programming and opportunistic migration during idle tool call intervals to minimize interference; and trajectory-adaptive resource manager that dynamically tunes model parallelism to accelerate the per-token time of long-tail trajectories while maintaining high throughput for short trajectories. Evaluations across diverse agentic RL workloads demonstrate that Heddle effectively neutralizes the long-tail bottleneck, achieving up to 2.5$\times$ higher end-to-end rollout throughput compared to state-of-the-art baselines.
TokenLake: A Unified Segment-level Prefix Cache Pool for Fine-grained Elastic Long-Context LLM Serving
Aug 24, 2025



Prefix caching is crucial to accelerate multi-turn interactions and requests with shared prefixes. At the cluster level, existing prefix caching systems are tightly coupled with request scheduling to optimize cache efficiency and computation performance together, leading to load imbalance, data redundancy, and memory fragmentation of caching systems across instances. To address these issues, memory pooling is promising to shield the scheduler from the underlying cache management so that it can focus on the computation optimization. However, because existing prefix caching systems only transfer increasingly longer prefix caches between instances, they cannot achieve low-latency memory pooling. To address these problems, we propose a unified segment-level prefix cache pool, TokenLake. It uses a declarative cache interface to expose requests' query tensors, prefix caches, and cache-aware operations to TokenLake for efficient pooling. Powered by this abstraction, TokenLake can manage prefix cache at the segment level with a heavy-hitter-aware load balancing algorithm to achieve better cache load balance, deduplication, and defragmentation. TokenLake also transparently minimizes the communication volume of query tensors and new caches. Based on TokenLake, the scheduler can schedule requests elastically by using existing techniques without considering prefix cache management. Evaluations on real-world workloads show that TokenLake can improve throughput by up to 2.6$\times$ and 2.0$\times$ and boost hit rate by 2.0$\times$ and 2.1$\times$, compared to state-of-the-art cache-aware routing and cache-centric PD-disaggregation solutions, respectively.
Step-Audio-AQAA: a Fully End-to-End Expressive Large Audio Language Model
Jun 10, 2025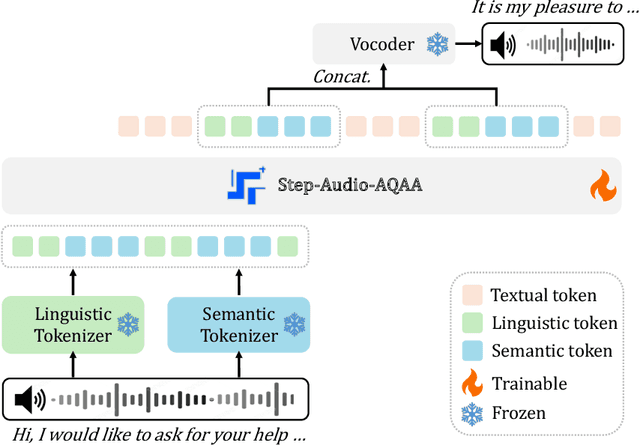
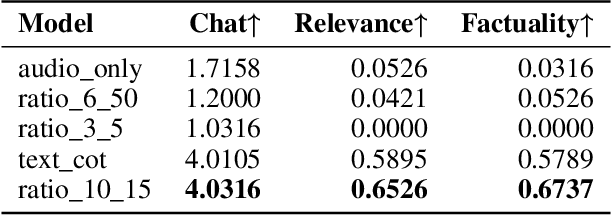
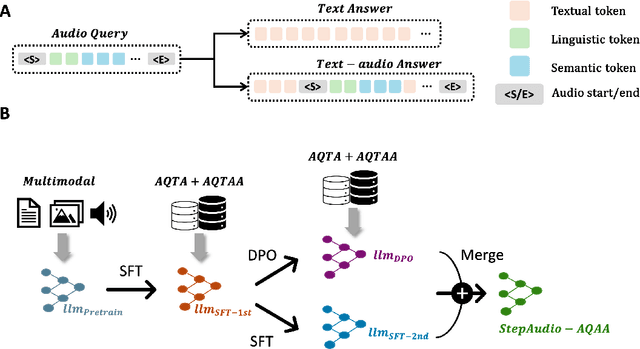

Large Audio-Language Models (LALMs) have significantly advanced intelligent human-computer interaction, yet their reliance on text-based outputs limits their ability to generate natural speech responses directly, hindering seamless audio interactions. To address this, we introduce Step-Audio-AQAA, a fully end-to-end LALM designed for Audio Query-Audio Answer (AQAA) tasks. The model integrates a dual-codebook audio tokenizer for linguistic and semantic feature extraction, a 130-billion-parameter backbone LLM and a neural vocoder for high-fidelity speech synthesis. Our post-training approach employs interleaved token-output of text and audio to enhance semantic coherence and combines Direct Preference Optimization (DPO) with model merge to improve performance. Evaluations on the StepEval-Audio-360 benchmark demonstrate that Step-Audio-AQAA excels especially in speech control, outperforming the state-of-art LALMs in key areas. This work contributes a promising solution for end-to-end LALMs and highlights the critical role of token-based vocoder in enhancing overall performance for AQAA tasks.
Label-efficient Single Photon Images Classification via Active Learning
May 07, 2025Single-photon LiDAR achieves high-precision 3D imaging in extreme environments through quantum-level photon detection technology. Current research primarily focuses on reconstructing 3D scenes from sparse photon events, whereas the semantic interpretation of single-photon images remains underexplored, due to high annotation costs and inefficient labeling strategies. This paper presents the first active learning framework for single-photon image classification. The core contribution is an imaging condition-aware sampling strategy that integrates synthetic augmentation to model variability across imaging conditions. By identifying samples where the model is both uncertain and sensitive to these conditions, the proposed method selectively annotates only the most informative examples. Experiments on both synthetic and real-world datasets show that our approach outperforms all baselines and achieves high classification accuracy with significantly fewer labeled samples. Specifically, our approach achieves 97% accuracy on synthetic single-photon data using only 1.5% labeled samples. On real-world data, we maintain 90.63% accuracy with just 8% labeled samples, which is 4.51% higher than the best-performing baseline. This illustrates that active learning enables the same level of classification performance on single-photon images as on classical images, opening doors to large-scale integration of single-photon data in real-world applications.
StreamRL: Scalable, Heterogeneous, and Elastic RL for LLMs with Disaggregated Stream Generation
Apr 22, 2025Reinforcement learning (RL) has become the core post-training technique for large language models (LLMs). RL for LLMs involves two stages: generation and training. The LLM first generates samples online, which are then used to derive rewards for training. The conventional view holds that the colocated architecture, where the two stages share resources via temporal multiplexing, outperforms the disaggregated architecture, in which dedicated resources are assigned to each stage. However, in real-world deployments, we observe that the colocated architecture suffers from resource coupling, where the two stages are constrained to use the same resources. This coupling compromises the scalability and cost-efficiency of colocated RL in large-scale training. In contrast, the disaggregated architecture allows for flexible resource allocation, supports heterogeneous training setups, and facilitates cross-datacenter deployment. StreamRL is designed with disaggregation from first principles and fully unlocks its potential by addressing two types of performance bottlenecks in existing disaggregated RL frameworks: pipeline bubbles, caused by stage dependencies, and skewness bubbles, resulting from long-tail output length distributions. To address pipeline bubbles, StreamRL breaks the traditional stage boundary in synchronous RL algorithms through stream generation and achieves full overlapping in asynchronous RL. To address skewness bubbles, StreamRL employs an output-length ranker model to identify long-tail samples and reduces generation time via skewness-aware dispatching and scheduling. Experiments show that StreamRL improves throughput by up to 2.66x compared to existing state-of-the-art systems, and improves cost-effectiveness by up to 1.33x in a heterogeneous, cross-datacenter setting.
Step-Audio: Unified Understanding and Generation in Intelligent Speech Interaction
Feb 18, 2025Real-time speech interaction, serving as a fundamental interface for human-machine collaboration, holds immense potential. However, current open-source models face limitations such as high costs in voice data collection, weakness in dynamic control, and limited intelligence. To address these challenges, this paper introduces Step-Audio, the first production-ready open-source solution. Key contributions include: 1) a 130B-parameter unified speech-text multi-modal model that achieves unified understanding and generation, with the Step-Audio-Chat version open-sourced; 2) a generative speech data engine that establishes an affordable voice cloning framework and produces the open-sourced lightweight Step-Audio-TTS-3B model through distillation; 3) an instruction-driven fine control system enabling dynamic adjustments across dialects, emotions, singing, and RAP; 4) an enhanced cognitive architecture augmented with tool calling and role-playing abilities to manage complex tasks effectively. Based on our new StepEval-Audio-360 evaluation benchmark, Step-Audio achieves state-of-the-art performance in human evaluations, especially in terms of instruction following. On open-source benchmarks like LLaMA Question, shows 9.3% average performance improvement, demonstrating our commitment to advancing the development of open-source multi-modal language technologies. Our code and models are available at https://github.com/stepfun-ai/Step-Audio.
RAGCache: Efficient Knowledge Caching for Retrieval-Augmented Generation
Apr 18, 2024



Retrieval-Augmented Generation (RAG) has shown significant improvements in various natural language processing tasks by integrating the strengths of large language models (LLMs) and external knowledge databases. However, RAG introduces long sequence generation and leads to high computation and memory costs. We propose Thoth, a novel multilevel dynamic caching system tailored for RAG. Our analysis benchmarks current RAG systems, pinpointing the performance bottleneck (i.e., long sequence due to knowledge injection) and optimization opportunities (i.e., caching knowledge's intermediate states). Based on these insights, we design Thoth, which organizes the intermediate states of retrieved knowledge in a knowledge tree and caches them in the GPU and host memory hierarchy. Thoth proposes a replacement policy that is aware of LLM inference characteristics and RAG retrieval patterns. It also dynamically overlaps the retrieval and inference steps to minimize the end-to-end latency. We implement Thoth and evaluate it on vLLM, a state-of-the-art LLM inference system and Faiss, a state-of-the-art vector database. The experimental results show that Thoth reduces the time to first token (TTFT) by up to 4x and improves the throughput by up to 2.1x compared to vLLM integrated with Faiss.
Iterative Refinement of Project-Level Code Context for Precise Code Generation with Compiler Feedback
Apr 02, 2024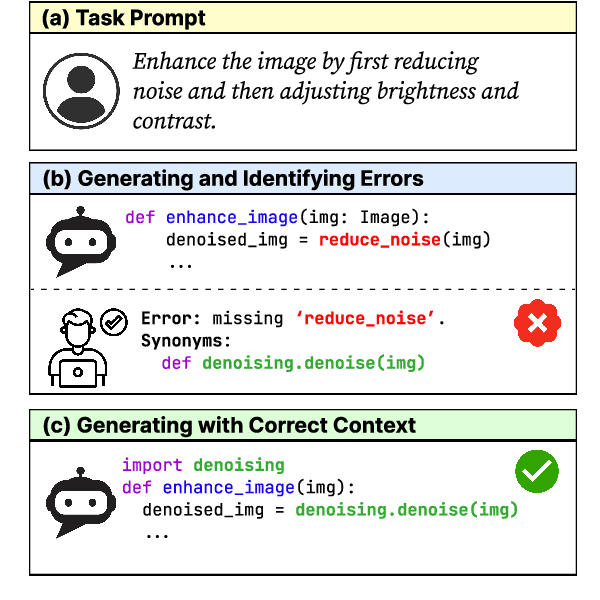

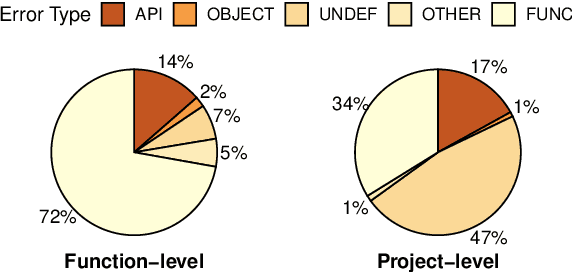
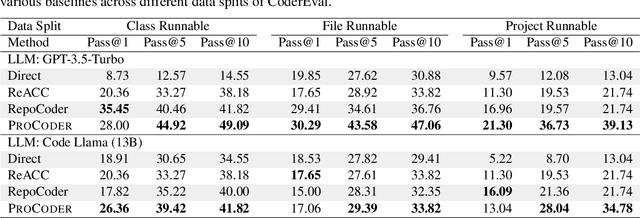
Large language models (LLMs) have shown remarkable progress in automated code generation. Yet, incorporating LLM-based code generation into real-life software projects poses challenges, as the generated code may contain errors in API usage, class, data structure, or missing project-specific information. As much of this project-specific context cannot fit into the prompts of LLMs, we must find ways to allow the model to explore the project-level code context. To this end, this paper puts forward a novel approach, termed ProCoder, which iteratively refines the project-level code context for precise code generation, guided by the compiler feedback. In particular, ProCoder first leverages compiler techniques to identify a mismatch between the generated code and the project's context. It then iteratively aligns and fixes the identified errors using information extracted from the code repository. We integrate ProCoder with two representative LLMs, i.e., GPT-3.5-Turbo and Code Llama (13B), and apply it to Python code generation. Experimental results show that ProCoder significantly improves the vanilla LLMs by over 80% in generating code dependent on project context, and consistently outperforms the existing retrieval-based code generation baselines.