 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchically Encapsulated Representation for Protocol Design in Self-Driving Labs
Apr 04, 2025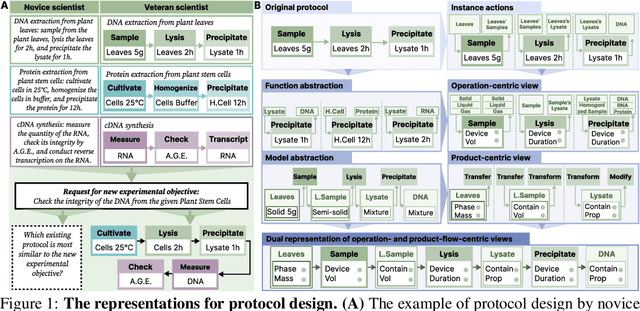

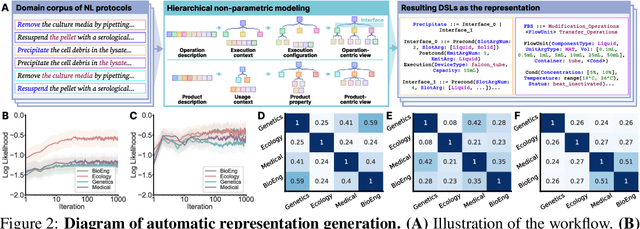
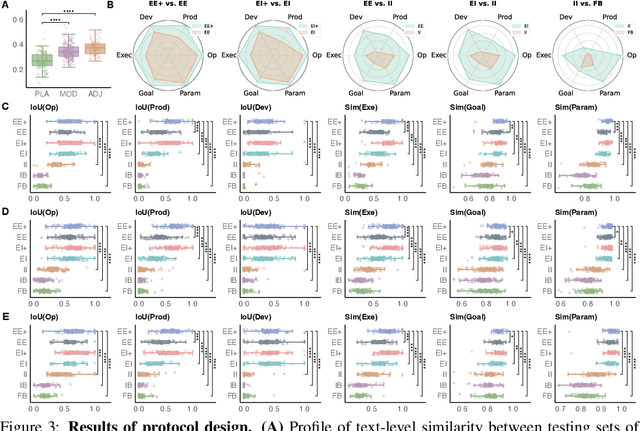
Self-driving laboratories have begun to replace human experimenters in performing single experimental skills or predetermined experimental protocols. However, as the pace of idea iteration in scientific research has been intensified by Artificial Intelligence, the demand for rapid design of new protocols for new discoveries become evident. Efforts to automate protocol design have been initiated, but the capabilities of knowledge-based machine designers, such as Large Language Models, have not been fully elicited, probably for the absence of a systematic representation of experimental knowledge, as opposed to isolated, flatten pieces of information. To tackle this issue, we propose a multi-faceted, multi-scale representation, where instance actions, generalized operations, and product flow models are hierarchically encapsulated using Domain-Specific Languages. We further develop a data-driven algorithm based on non-parametric modeling that autonomously customizes these representations for specific domains. The proposed representation is equipped with various machine designers to manage protocol design tasks, including planning, modification, and adjustment. The results demonstrate that the proposed method could effectively complement Large Language Models in the protocol design process, serving as an auxiliary module in the realm of machine-assisted scientific exploration.
How to Select Pre-Trained Code Models for Reuse? A Learning Perspective
Jan 07, 2025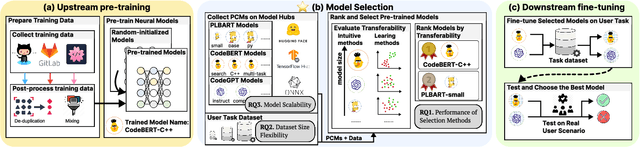


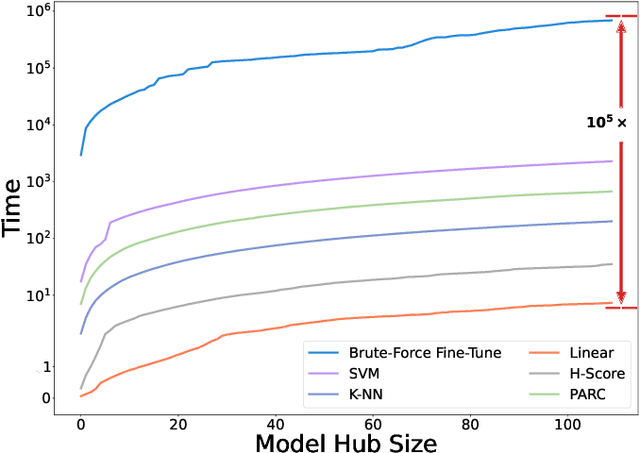
Pre-training a language model and then fine-tuning it has shown to be an efficient and effective technique for a wide range of code intelligence tasks, such as code generation, code summarization, and vulnerability detection. However, pretraining language models on a large-scale code corpus is computationally expensive. Fortunately, many off-the-shelf Pre-trained Code Models (PCMs), such as CodeBERT, CodeT5, CodeGen, and Code Llama, have been released publicly. These models acquire general code understanding and generation capability during pretraining, which enhances their performance on downstream code intelligence tasks. With an increasing number of these public pre-trained models, selecting the most suitable one to reuse for a specific task is essential. In this paper, we systematically investigate the reusability of PCMs. We first explore three intuitive model selection methods that select by size, training data, or brute-force fine-tuning. Experimental results show that these straightforward techniques either perform poorly or suffer high costs. Motivated by these findings, we explore learning-based model selection strategies that utilize pre-trained models without altering their parameters. Specifically, we train proxy models to gauge the performance of pre-trained models, and measure the distribution deviation between a model's latent features and the task's labels, using their closeness as an indicator of model transferability. We conduct experiments on 100 widely-used opensource PCMs for code intelligence tasks, with sizes ranging from 42.5 million to 3 billion parameters. The results demonstrate that learning-based selection methods reduce selection time to 100 seconds, compared to 2,700 hours with brute-force fine-tuning, with less than 6% performance degradation across related tasks.
Expert-level protocol translation for self-driving labs
Nov 01, 2024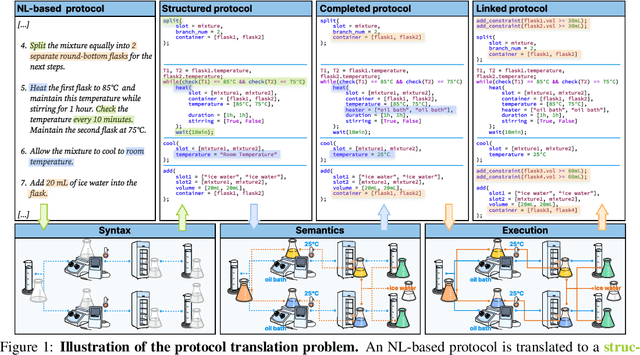
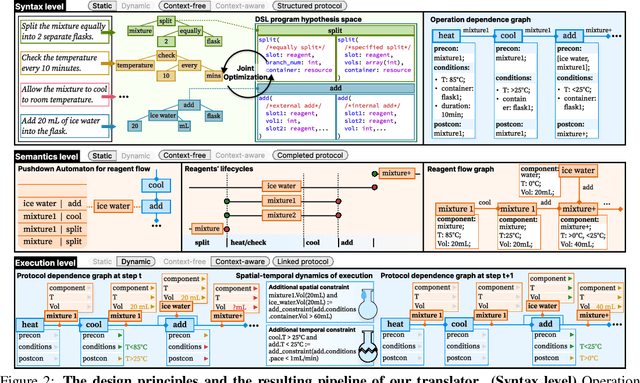
Recent development in Artificial Intelligence (AI) models has propelled their application in scientific discovery, but the validation and exploration of these discoveries require subsequent empirical experimentation. The concept of self-driving laboratories promises to automate and thus boost the experimental process following AI-driven discoveries. However, the transition of experimental protocols, originally crafted for human comprehension, into formats interpretable by machines presents significant challenges, which, within the context of specific expert domain, encompass the necessity for structured as opposed to natural language, the imperative for explicit rather than tacit knowledge, and the preservation of causality and consistency throughout protocol steps. Presently, the task of protocol translation predominantly requires the manual and labor-intensive involvement of domain experts and information technology specialists, rendering the process time-intensive. To address these issues, we propose a framework that automates the protocol translation process through a three-stage workflow, which incrementally constructs Protocol Dependence Graphs (PDGs) that approach structured on the syntax level, completed on the semantics level, and linked on the execution level. Quantitative and qualitative evaluations have demonstrated its performance at par with that of human experts, underscoring its potential to significantly expedite and democratize the process of scientific discovery by elevating the automation capabilities within self-driving laboratories.
AutoDSL: Automated domain-specific language design for structural representation of procedures with constraints
Jun 18, 2024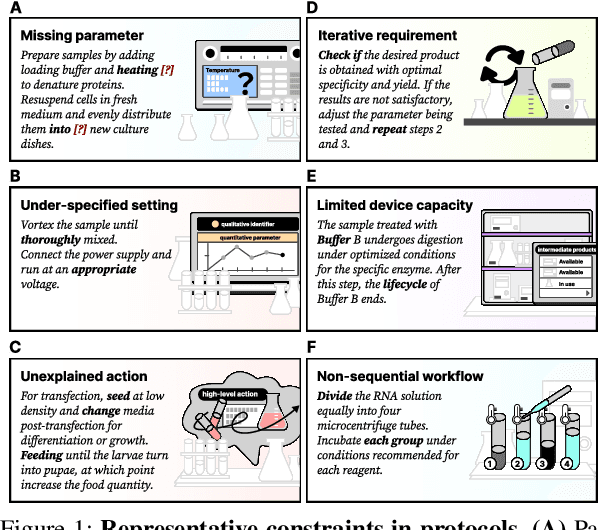



Accurate representation of procedures in restricted scenarios, such as non-standardized scientific experiments, requires precise depiction of constraints. Unfortunately, Domain-specific Language (DSL), as an effective tool to express constraints structurally, often requires case-by-case hand-crafting, necessitating customized, labor-intensive efforts. To overcome this challenge, we introduce the AutoDSL framework to automate DSL-based constraint design across various domains. Utilizing domain specified experimental protocol corpora, AutoDSL optimizes syntactic constraints and abstracts semantic constraints. Quantitative and qualitative analyses of the DSLs designed by AutoDSL across five distinct domains highlight its potential as an auxiliary module for language models, aiming to improve procedural planning and execution.
CodeIP: A Grammar-Guided Multi-Bit Watermark for Large Language Models of Code
Apr 24, 2024



As Large Language Models (LLMs) are increasingly used to automate code generation, it is often desired to know if the code is AI-generated and by which model, especially for purposes like protecting intellectual property (IP) in industry and preventing academic misconduct in education. Incorporating watermarks into machine-generated content is one way to provide code provenance, but existing solutions are restricted to a single bit or lack flexibility. We present CodeIP, a new watermarking technique for LLM-based code generation. CodeIP enables the insertion of multi-bit information while preserving the semantics of the generated code, improving the strength and diversity of the inerseted watermark. This is achieved by training a type predictor to predict the subsequent grammar type of the next token to enhance the syntactical and semantic correctness of the generated code. Experiments on a real-world dataset across five programming languages showcase the effectiveness of CodeIP.
Iterative Refinement of Project-Level Code Context for Precise Code Generation with Compiler Feedback
Apr 02, 2024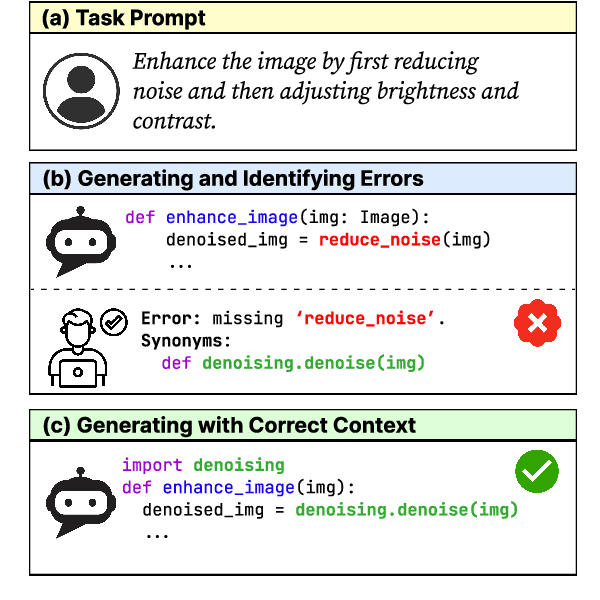

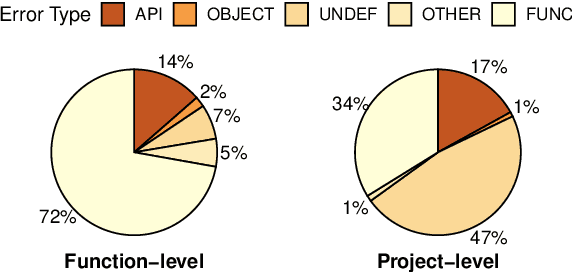
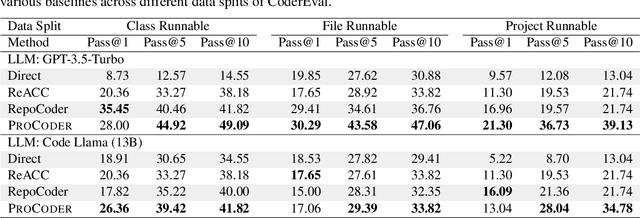
Large language models (LLMs) have shown remarkable progress in automated code generation. Yet, incorporating LLM-based code generation into real-life software projects poses challenges, as the generated code may contain errors in API usage, class, data structure, or missing project-specific information. As much of this project-specific context cannot fit into the prompts of LLMs, we must find ways to allow the model to explore the project-level code context. To this end, this paper puts forward a novel approach, termed ProCoder, which iteratively refines the project-level code context for precise code generation, guided by the compiler feedback. In particular, ProCoder first leverages compiler techniques to identify a mismatch between the generated code and the project's context. It then iteratively aligns and fixes the identified errors using information extracted from the code repository. We integrate ProCoder with two representative LLMs, i.e., GPT-3.5-Turbo and Code Llama (13B), and apply it to Python code generation. Experimental results show that ProCoder significantly improves the vanilla LLMs by over 80% in generating code dependent on project context, and consistently outperforms the existing retrieval-based code generation baselines.
Deep Learning for Code Intelligence: Survey, Benchmark and Toolkit
Dec 30, 2023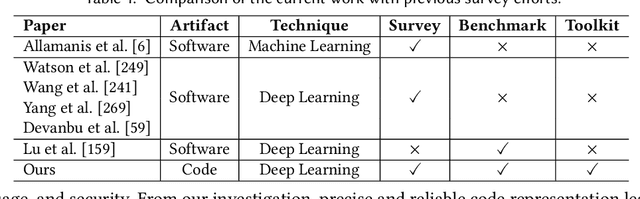


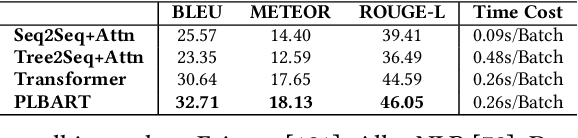
Code intelligence leverages machine learning techniques to extract knowledge from extensive code corpora, with the aim of developing intelligent tools to improve the quality and productivity of computer programming. Currently, there is already a thriving research community focusing on code intelligence, with efforts ranging from software engineering, machine learning, data mining, natural language processing, and programming languages. In this paper, we conduct a comprehensive literature review on deep learning for code intelligence, from the aspects of code representation learning, deep learning techniques, and application tasks. We also benchmark several state-of-the-art neural models for code intelligence, and provide an open-source toolkit tailored for the rapid prototyping of deep-learning-based code intelligence models. In particular, we inspect the existing code intelligence models under the basis of code representation learning, and provide a comprehensive overview to enhance comprehension of the present state of code intelligence. Furthermore, we publicly release the source code and data resources to provide the community with a ready-to-use benchmark, which can facilitate the evaluation and comparison of existing and future code intelligence models (https://xcodemind.github.io). At last, we also point out several challenging and promising directions for future research.