 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre We on the Right Way to Assessing LLM-as-a-Judge?
Dec 17, 2025LLM-as-a-Judge has been widely adopted as an evaluation method and served as supervised rewards in model training. However, existing benchmarks for LLM-as-a-Judge are mainly relying on human-annotated ground truth, which introduces human bias that undermines the assessment of reliability and imposes scalability constraints. To overcome these limitations, we introduce Sage, a novel evaluation suite that assesses the quality of LLM judges without necessitating any human annotation. Inspired by axioms of rational choice theory, Sage introduces two new lenses for measuring LLM-as-a-Judge: local self-consistency (pair-wise preference stability) and global logical consistency (transitivity across a full set of preferences). We curate a dataset of 650 questions by combining structured benchmark problems with real-world user queries. Our experiments demonstrate both the stability of our metrics and their high correlation with supervised benchmarks like LLMBar and RewardBench2, confirming Sage's reliability as an evaluation suite for the robustness and accuracy of LLM-as-a-Judge. Based on Sage, we reveal that current state-of-the-art LLMs exhibit significant reliability problems when acting as judges in both scoring and pairwise settings; even the top-performing models, Gemini-2.5-Pro and GPT-5, fail to maintain consistent preferences in nearly a quarter of difficult cases. We attribute this to a new phenomenon called situational preference, which explains why explicit rubrics or criteria can help the model judge consistently across answer pairs. Our further analysis shows that finetuned LLM-as-a-Judge is a feasible method to boost performance, and the panel-based judge as well as deep reasoning can enhance the judging consistency. We also find substantial inconsistency in human judgments, which indicates that human annotation may not be a reliable gold standard.
Bridging Code Graphs and Large Language Models for Better Code Understanding
Dec 08, 2025



Large Language Models (LLMs) have demonstrated remarkable performance in code intelligence tasks such as code generation, summarization, and translation. However, their reliance on linearized token sequences limits their ability to understand the structural semantics of programs. While prior studies have explored graphaugmented prompting and structure-aware pretraining, they either suffer from prompt length constraints or require task-specific architectural changes that are incompatible with large-scale instructionfollowing LLMs. To address these limitations, this paper proposes CGBridge, a novel plug-and-play method that enhances LLMs with Code Graph information through an external, trainable Bridge module. CGBridge first pre-trains a code graph encoder via selfsupervised learning on a large-scale dataset of 270K code graphs to learn structural code semantics. It then trains an external module to bridge the modality gap among code, graph, and text by aligning their semantics through cross-modal attention mechanisms. Finally, the bridge module generates structure-informed prompts, which are injected into a frozen LLM, and is fine-tuned for downstream code intelligence tasks. Experiments show that CGBridge achieves notable improvements over both the original model and the graphaugmented prompting method. Specifically, it yields a 16.19% and 9.12% relative gain in LLM-as-a-Judge on code summarization, and a 9.84% and 38.87% relative gain in Execution Accuracy on code translation. Moreover, CGBridge achieves over 4x faster inference than LoRA-tuned models, demonstrating both effectiveness and efficiency in structure-aware code understanding.
WAR-Re: Web API Recommendation with Semantic Reasoning
Nov 08, 2025With the development of cloud computing, the number of Web APIs has increased dramatically, further intensifying the demand for efficient Web API recommendation. Despite the demonstrated success of previous Web API recommendation solutions, two critical challenges persist: 1) a fixed top-N recommendation that cannot accommodate the varying API cardinality requirements of different mashups, and 2) these methods output only ranked API lists without accompanying reasons, depriving users of understanding the recommendation. To address these challenges, we propose WAR-Re, an LLM-based model for Web API recommendation with semantic reasoning for justification. WAR-Re leverages special start and stop tokens to handle the first challenge and uses two-stage training: supervised fine-tuning and reinforcement learning via Group Relative Policy Optimization (GRPO) to enhance the model's ability in both tasks. Comprehensive experimental evaluations on the ProgrammableWeb dataset demonstrate that WAR-Re achieves a gain of up to 21.59\% over the state-of-the-art baseline model in recommendation accuracy, while consistently producing high-quality semantic reasons for recommendations.
MultiRef: Controllable Image Generation with Multiple Visual References
Aug 09, 2025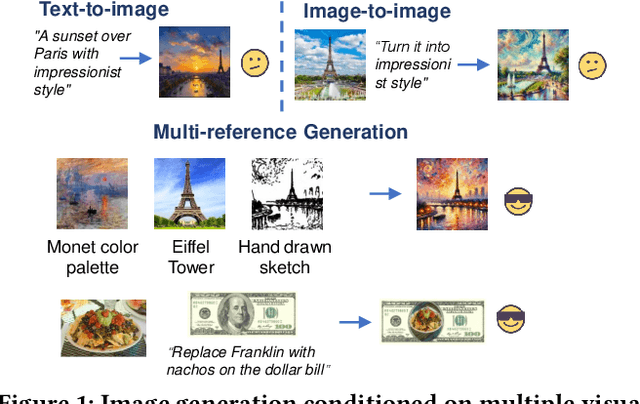
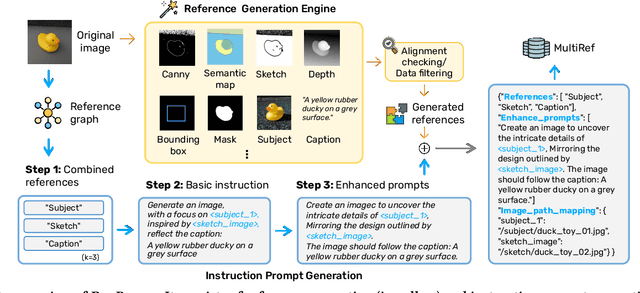
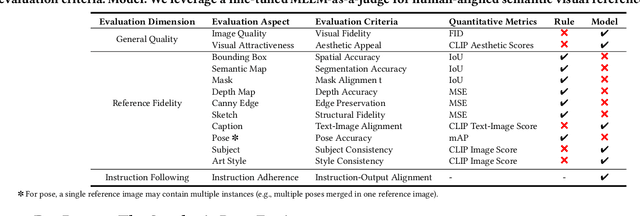
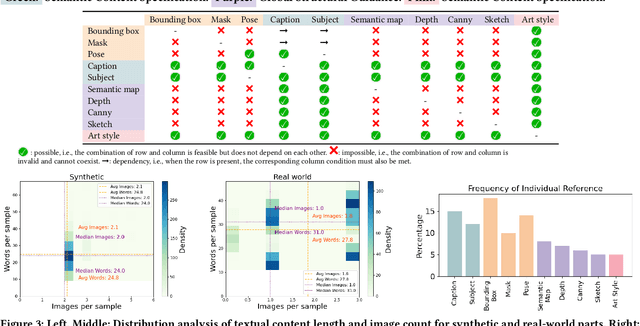
Visual designers naturally draw inspiration from multiple visual references, combining diverse elements and aesthetic principles to create artwork. However, current image generative frameworks predominantly rely on single-source inputs -- either text prompts or individual reference images. In this paper, we focus on the task of controllable image generation using multiple visual references. We introduce MultiRef-bench, a rigorous evaluation framework comprising 990 synthetic and 1,000 real-world samples that require incorporating visual content from multiple reference images. The synthetic samples are synthetically generated through our data engine RefBlend, with 10 reference types and 33 reference combinations. Based on RefBlend, we further construct a dataset MultiRef containing 38k high-quality images to facilitate further research. Our experiments across three interleaved image-text models (i.e., OmniGen, ACE, and Show-o) and six agentic frameworks (e.g., ChatDiT and LLM + SD) reveal that even state-of-the-art systems struggle with multi-reference conditioning, with the best model OmniGen achieving only 66.6% in synthetic samples and 79.0% in real-world cases on average compared to the golden answer. These findings provide valuable directions for developing more flexible and human-like creative tools that can effectively integrate multiple sources of visual inspiration. The dataset is publicly available at: https://multiref.github.io/.
code_transformed: The Influence of Large Language Models on Code
Jun 13, 2025Coding remains one of the most fundamental modes of interaction between humans and machines. With the rapid advancement of Large Language Models (LLMs), code generation capabilities have begun to significantly reshape programming practices. This development prompts a central question: Have LLMs transformed code style, and how can such transformation be characterized? In this paper, we present a pioneering study that investigates the impact of LLMs on code style, with a focus on naming conventions, complexity, maintainability, and similarity. By analyzing code from over 19,000 GitHub repositories linked to arXiv papers published between 2020 and 2025, we identify measurable trends in the evolution of coding style that align with characteristics of LLM-generated code. For instance, the proportion of snake\_case variable names in Python code increased from 47% in Q1 2023 to 51% in Q1 2025. Furthermore, we investigate how LLMs approach algorithmic problems by examining their reasoning processes. Given the diversity of LLMs and usage scenarios, among other factors, it is difficult or even impossible to precisely estimate the proportion of code generated or assisted by LLMs. Our experimental results provide the first large-scale empirical evidence that LLMs affect real-world programming style.
LiveVQA: Live Visual Knowledge Seeking
Apr 07, 2025



We introduce LiveVQA, an automatically collected dataset of latest visual knowledge from the Internet with synthesized VQA problems. LiveVQA consists of 3,602 single- and multi-hop visual questions from 6 news websites across 14 news categories, featuring high-quality image-text coherence and authentic information. Our evaluation across 15 MLLMs (e.g., GPT-4o, Gemma-3, and Qwen-2.5-VL family) demonstrates that stronger models perform better overall, with advanced visual reasoning capabilities proving crucial for complex multi-hop questions. Despite excellent performance on textual problems, models with tools like search engines still show significant gaps when addressing visual questions requiring latest visual knowledge, highlighting important areas for future research.
Wikipedia in the Era of LLMs: Evolution and Risks
Mar 04, 2025

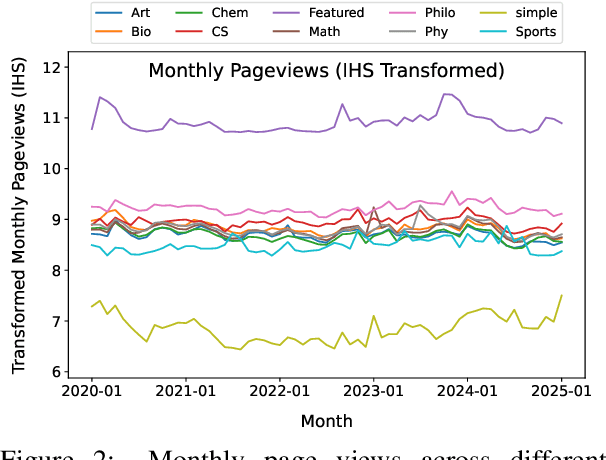

In this paper, we present a thorough analysis of the impact of Large Language Models (LLMs) on Wikipedia, examining the evolution of Wikipedia through existing data and using simulations to explore potential risks. We begin by analyzing page views and article content to study Wikipedia's recent changes and assess the impact of LLMs. Subsequently, we evaluate how LLMs affect various Natural Language Processing (NLP) tasks related to Wikipedia, including machine translation and retrieval-augmented generation (RAG). Our findings and simulation results reveal that Wikipedia articles have been influenced by LLMs, with an impact of approximately 1%-2% in certain categories. If the machine translation benchmark based on Wikipedia is influenced by LLMs, the scores of the models may become inflated, and the comparative results among models might shift as well. Moreover, the effectiveness of RAG might decrease if the knowledge base becomes polluted by LLM-generated content. While LLMs have not yet fully changed Wikipedia's language and knowledge structures, we believe that our empirical findings signal the need for careful consideration of potential future risks.
CrowdSelect: Synthetic Instruction Data Selection with Multi-LLM Wisdom
Mar 03, 2025



Distilling advanced Large Language Models' instruction-following capabilities into smaller models using a selected subset has become a mainstream approach in model training. While existing synthetic instruction data selection strategies rely mainly on single-dimensional signals (i.e., reward scores, model perplexity), they fail to capture the complexity of instruction-following across diverse fields. Therefore, we investigate more diverse signals to capture comprehensive instruction-response pair characteristics and propose three foundational metrics that leverage Multi-LLM wisdom, informed by (1) diverse LLM responses and (2) reward model assessment. Building upon base metrics, we propose CrowdSelect, an integrated metric incorporating a clustering-based approach to maintain response diversity. Our comprehensive experiments demonstrate that our foundation metrics consistently improve performance across 4 base models on MT-bench and Arena-Hard. CrowdSelect, efficiently incorporating all metrics, achieves state-of-the-art performance in both Full and LoRA fine-tuning, showing improvements of 4.81% on Arena-Hard and 11.1% on MT-bench with Llama-3.2-3b-instruct. We hope our findings will bring valuable insights for future research in this direction. Code are available at https://github.com/listentm/crowdselect.
CODESYNC: Synchronizing Large Language Models with Dynamic Code Evolution at Scale
Feb 23, 2025Large Language Models (LLMs) have exhibited exceptional performance in software engineering yet face challenges in adapting to continually evolving code knowledge, particularly regarding the frequent updates of third-party library APIs. This limitation, stemming from static pre-training datasets, often results in non-executable code or implementations with suboptimal safety and efficiency. To this end, this paper introduces CODESYNC, a data engine for identifying outdated code patterns and collecting real-time code knowledge updates from Python third-party libraries. Building upon CODESYNC, we develop CODESYNCBENCH, a comprehensive benchmark for assessing LLMs' ability to stay synchronized with code evolution, which covers real-world updates for 220 APIs from six Python libraries. Our benchmark offers 3,300 test cases across three evaluation tasks and an update-aware instruction tuning dataset consisting of 2,200 training samples. Extensive experiments on 14 state-of-the-art LLMs reveal that they struggle with dynamic code evolution, even with the support of advanced knowledge updating methods (e.g., DPO, ORPO, and SimPO). We believe that our benchmark can offer a strong foundation for the development of more effective methods for real-time code knowledge updating in the future. The experimental code and dataset are publicly available at: https://github.com/Lucky-voyage/Code-Sync.
Can Large Language Models Understand Intermediate Representations?
Feb 07, 2025Intermediate Representations (IRs) are essential in compiler design and program analysis, yet their comprehension by Large Language Models (LLMs) remains underexplored. This paper presents a pioneering empirical study to investigate the capabilities of LLMs, including GPT-4, GPT-3, Gemma 2, LLaMA 3.1, and Code Llama, in understanding IRs. We analyze their performance across four tasks: Control Flow Graph (CFG) reconstruction, decompilation, code summarization, and execution reasoning. Our results indicate that while LLMs demonstrate competence in parsing IR syntax and recognizing high-level structures, they struggle with control flow reasoning, execution semantics, and loop handling. Specifically, they often misinterpret branching instructions, omit critical IR operations, and rely on heuristic-based reasoning, leading to errors in CFG reconstruction, IR decompilation, and execution reasoning. The study underscores the necessity for IR-specific enhancements in LLMs, recommending fine-tuning on structured IR datasets and integration of explicit control flow models to augment their comprehension and handling of IR-related tasks.