 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing How Scalable Table Data Enhances General Long-Context Reasoning
Mar 23, 2026As real-world tasks grow increasingly complex, long-context reasoning has become a core capability for Large Language Models (LLMs). However, few studies explore which data types are effective for long-context reasoning and why. We find that structured table data with periodic structures shows strong potential for long-context reasoning. Motivated by this observation, we mathematically analyze tabular dependency structures using mutual information, revealing periodic non-vanishing dependencies in table data. Furthermore, we systematically analyze the capabilities of structured table data, conduct relevant scaling experiments, and validate its underlying mechanisms for enhancing long-context reasoning, yielding several meaningful insights. Leveraging these insights, we propose a simple yet scalable pipeline(TableLong) for synthesizing high-quality, diverse, and verifiable structured table data to boost long-context reasoning via RL. Extensive experimental results demonstrate that table data significantly enhances the long-context reasoning capability of LLMs across multiple long-context benchmarks (+8.24\% on average), and even improves performance on out-of-domain benchmarks (+8.06\% on average). We hope that our insights provide practical guidance for effective post-training data to enhance long-context reasoning in LLMs.
code_transformed: The Influence of Large Language Models on Code
Jun 13, 2025Coding remains one of the most fundamental modes of interaction between humans and machines. With the rapid advancement of Large Language Models (LLMs), code generation capabilities have begun to significantly reshape programming practices. This development prompts a central question: Have LLMs transformed code style, and how can such transformation be characterized? In this paper, we present a pioneering study that investigates the impact of LLMs on code style, with a focus on naming conventions, complexity, maintainability, and similarity. By analyzing code from over 19,000 GitHub repositories linked to arXiv papers published between 2020 and 2025, we identify measurable trends in the evolution of coding style that align with characteristics of LLM-generated code. For instance, the proportion of snake\_case variable names in Python code increased from 47% in Q1 2023 to 51% in Q1 2025. Furthermore, we investigate how LLMs approach algorithmic problems by examining their reasoning processes. Given the diversity of LLMs and usage scenarios, among other factors, it is difficult or even impossible to precisely estimate the proportion of code generated or assisted by LLMs. Our experimental results provide the first large-scale empirical evidence that LLMs affect real-world programming style.
Is Compression Really Linear with Code Intelligence?
May 16, 2025



Understanding the relationship between data compression and the capabilities of Large Language Models (LLMs) is crucial, especially in specialized domains like code intelligence. Prior work posited a linear relationship between compression and general intelligence. However, it overlooked the multifaceted nature of code that encompasses diverse programming languages and tasks, and struggled with fair evaluation of modern Code LLMs. We address this by evaluating a diverse array of open-source Code LLMs on comprehensive multi-language, multi-task code benchmarks. To address the challenge of efficient and fair evaluation of pre-trained LLMs' code intelligence, we introduce \textit{Format Annealing}, a lightweight, transparent training methodology designed to assess the intrinsic capabilities of these pre-trained models equitably. Compression efficacy, measured as bits-per-character (BPC), is determined using a novel, large-scale, and previously unseen code validation set derived from GitHub. Our empirical results reveal a fundamental logarithmic relationship between measured code intelligence and BPC. This finding refines prior hypotheses of linearity, which we suggest are likely observations of the logarithmic curve's tail under specific, limited conditions. Our work provides a more nuanced understanding of compression's role in developing code intelligence and contributes a robust evaluation framework in the code domain.
Wikipedia in the Era of LLMs: Evolution and Risks
Mar 04, 2025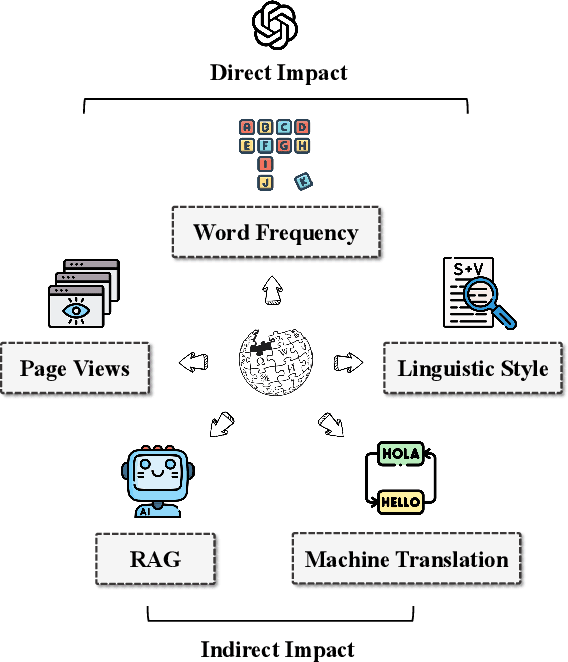

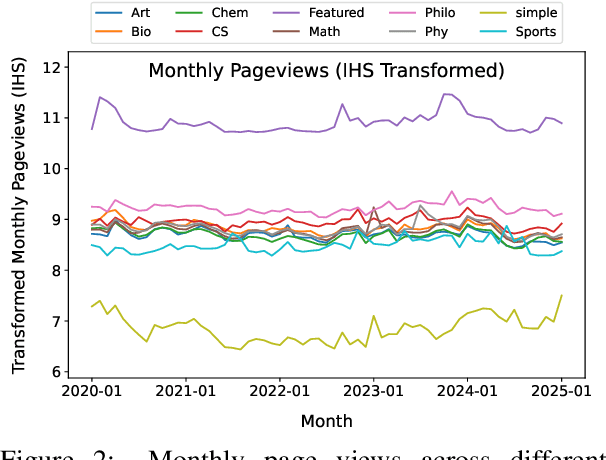

In this paper, we present a thorough analysis of the impact of Large Language Models (LLMs) on Wikipedia, examining the evolution of Wikipedia through existing data and using simulations to explore potential risks. We begin by analyzing page views and article content to study Wikipedia's recent changes and assess the impact of LLMs. Subsequently, we evaluate how LLMs affect various Natural Language Processing (NLP) tasks related to Wikipedia, including machine translation and retrieval-augmented generation (RAG). Our findings and simulation results reveal that Wikipedia articles have been influenced by LLMs, with an impact of approximately 1%-2% in certain categories. If the machine translation benchmark based on Wikipedia is influenced by LLMs, the scores of the models may become inflated, and the comparative results among models might shift as well. Moreover, the effectiveness of RAG might decrease if the knowledge base becomes polluted by LLM-generated content. While LLMs have not yet fully changed Wikipedia's language and knowledge structures, we believe that our empirical findings signal the need for careful consideration of potential future risks.
SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines
Feb 20, 2025Large language models (LLMs) have demonstrated remarkable proficiency in mainstream academic disciplines such as mathematics, physics, and computer science. However, human knowledge encompasses over 200 specialized disciplines, far exceeding the scope of existing benchmarks. The capabilities of LLMs in many of these specialized fields-particularly in light industry, agriculture, and service-oriented disciplines-remain inadequately evaluated. To address this gap, we present SuperGPQA, a comprehensive benchmark that evaluates graduate-level knowledge and reasoning capabilities across 285 disciplines. Our benchmark employs a novel Human-LLM collaborative filtering mechanism to eliminate trivial or ambiguous questions through iterative refinement based on both LLM responses and expert feedback. Our experimental results reveal significant room for improvement in the performance of current state-of-the-art LLMs across diverse knowledge domains (e.g., the reasoning-focused model DeepSeek-R1 achieved the highest accuracy of 61.82% on SuperGPQA), highlighting the considerable gap between current model capabilities and artificial general intelligence. Additionally, we present comprehensive insights from our management of a large-scale annotation process, involving over 80 expert annotators and an interactive Human-LLM collaborative system, offering valuable methodological guidance for future research initiatives of comparable scope.
OpenCoder: The Open Cookbook for Top-Tier Code Large Language Models
Nov 07, 2024



Large language models (LLMs) for code have become indispensable in various domains, including code generation, reasoning tasks and agent systems.While open-access code LLMs are increasingly approaching the performance levels of proprietary models, high-quality code LLMs suitable for rigorous scientific investigation, particularly those with reproducible data processing pipelines and transparent training protocols, remain limited. The scarcity is due to various challenges, including resource constraints, ethical considerations, and the competitive advantages of keeping models advanced. To address the gap, we introduce OpenCoder, a top-tier code LLM that not only achieves performance comparable to leading models but also serves as an ``open cookbook'' for the research community. Unlike most prior efforts, we release not only model weights and inference code, but also the reproducible training data, complete data processing pipeline, rigorous experimental ablation results, and detailed training protocols for open scientific research. Through this comprehensive release, we identify the key ingredients for building a top-tier code LLM: (1) code optimized heuristic rules for data cleaning and methods for data deduplication, (2) recall of text corpus related to code and (3) high-quality synthetic data in both annealing and supervised fine-tuning stages. By offering this level of openness, we aim to broaden access to all aspects of a top-tier code LLM, with OpenCoder serving as both a powerful model and an open foundation to accelerate research, and enable reproducible advancements in code AI.
SDPose: Tokenized Pose Estimation via Circulation-Guide Self-Distillation
Apr 04, 2024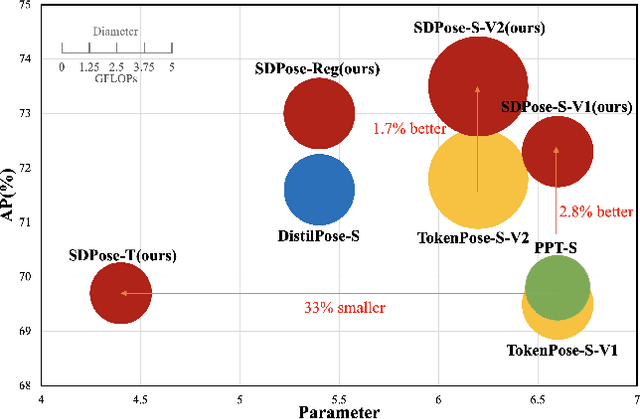
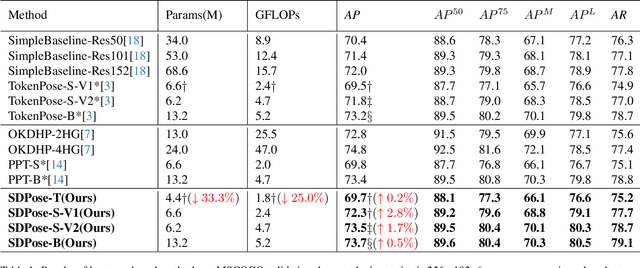
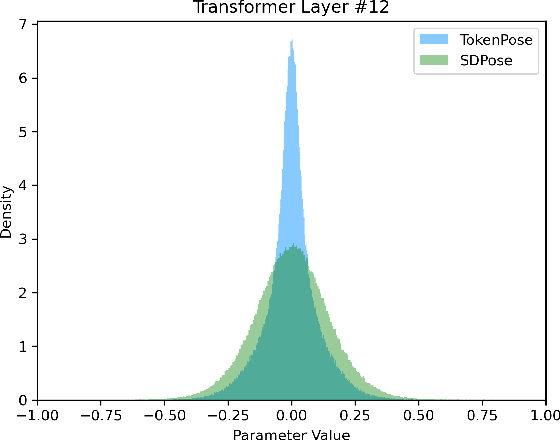
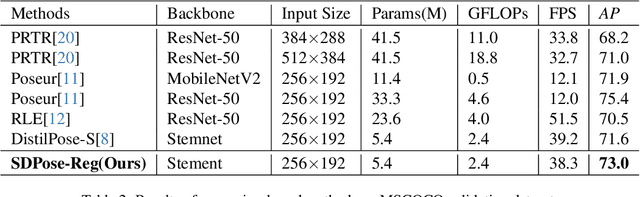
Recently, transformer-based methods have achieved state-of-the-art prediction quality on human pose estimation(HPE). Nonetheless, most of these top-performing transformer-based models are too computation-consuming and storage-demanding to deploy on edge computing platforms. Those transformer-based models that require fewer resources are prone to under-fitting due to their smaller scale and thus perform notably worse than their larger counterparts. Given this conundrum, we introduce SDPose, a new self-distillation method for improving the performance of small transformer-based models. To mitigate the problem of under-fitting, we design a transformer module named Multi-Cycled Transformer(MCT) based on multiple-cycled forwards to more fully exploit the potential of small model parameters. Further, in order to prevent the additional inference compute-consuming brought by MCT, we introduce a self-distillation scheme, extracting the knowledge from the MCT module to a naive forward model. Specifically, on the MSCOCO validation dataset, SDPose-T obtains 69.7% mAP with 4.4M parameters and 1.8 GFLOPs. Furthermore, SDPose-S-V2 obtains 73.5% mAP on the MSCOCO validation dataset with 6.2M parameters and 4.7 GFLOPs, achieving a new state-of-the-art among predominant tiny neural network methods. Our code is available at https://github.com/MartyrPenink/SDPose.