 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenCoder: The Open Cookbook for Top-Tier Code Large Language Models
Nov 07, 2024



Large language models (LLMs) for code have become indispensable in various domains, including code generation, reasoning tasks and agent systems.While open-access code LLMs are increasingly approaching the performance levels of proprietary models, high-quality code LLMs suitable for rigorous scientific investigation, particularly those with reproducible data processing pipelines and transparent training protocols, remain limited. The scarcity is due to various challenges, including resource constraints, ethical considerations, and the competitive advantages of keeping models advanced. To address the gap, we introduce OpenCoder, a top-tier code LLM that not only achieves performance comparable to leading models but also serves as an ``open cookbook'' for the research community. Unlike most prior efforts, we release not only model weights and inference code, but also the reproducible training data, complete data processing pipeline, rigorous experimental ablation results, and detailed training protocols for open scientific research. Through this comprehensive release, we identify the key ingredients for building a top-tier code LLM: (1) code optimized heuristic rules for data cleaning and methods for data deduplication, (2) recall of text corpus related to code and (3) high-quality synthetic data in both annealing and supervised fine-tuning stages. By offering this level of openness, we aim to broaden access to all aspects of a top-tier code LLM, with OpenCoder serving as both a powerful model and an open foundation to accelerate research, and enable reproducible advancements in code AI.
A Comparative Study on Reasoning Patterns of OpenAI's o1 Model
Oct 17, 2024



Enabling Large Language Models (LLMs) to handle a wider range of complex tasks (e.g., coding, math) has drawn great attention from many researchers. As LLMs continue to evolve, merely increasing the number of model parameters yields diminishing performance improvements and heavy computational costs. Recently, OpenAI's o1 model has shown that inference strategies (i.e., Test-time Compute methods) can also significantly enhance the reasoning capabilities of LLMs. However, the mechanisms behind these methods are still unexplored. In our work, to investigate the reasoning patterns of o1, we compare o1 with existing Test-time Compute methods (BoN, Step-wise BoN, Agent Workflow, and Self-Refine) by using OpenAI's GPT-4o as a backbone on general reasoning benchmarks in three domains (i.e., math, coding, commonsense reasoning). Specifically, first, our experiments show that the o1 model has achieved the best performance on most datasets. Second, as for the methods of searching diverse responses (e.g., BoN), we find the reward models' capability and the search space both limit the upper boundary of these methods. Third, as for the methods that break the problem into many sub-problems, the Agent Workflow has achieved better performance than Step-wise BoN due to the domain-specific system prompt for planning better reasoning processes. Fourth, it is worth mentioning that we have summarized six reasoning patterns of o1, and provided a detailed analysis on several reasoning benchmarks.
LIME-M: Less Is More for Evaluation of MLLMs
Sep 10, 2024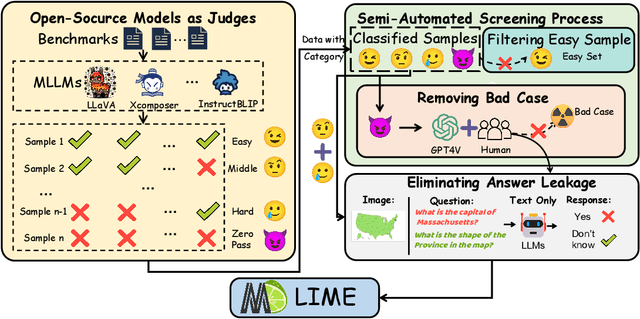
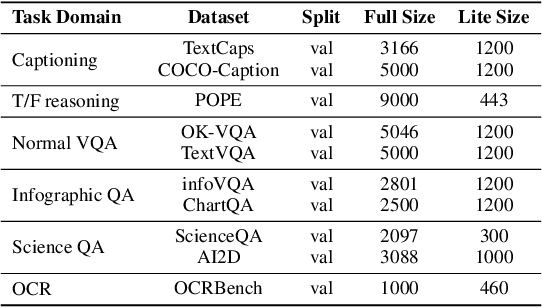
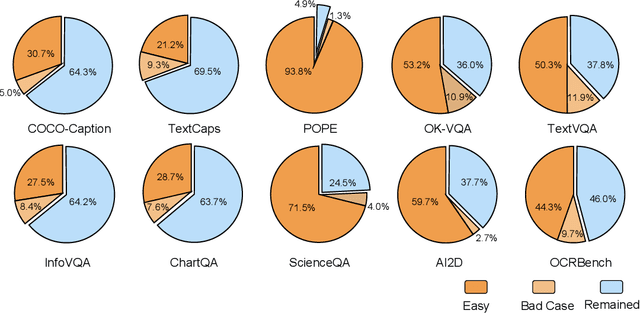
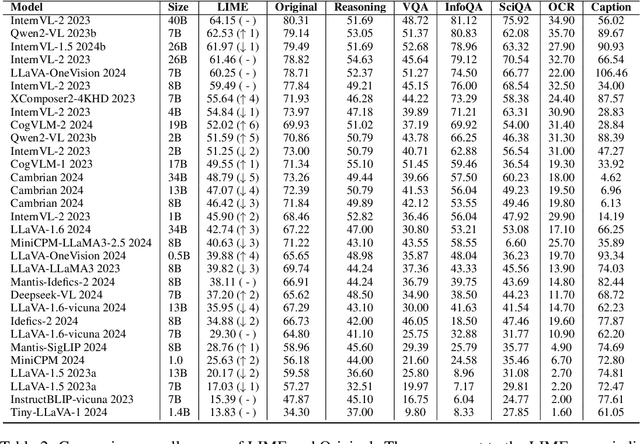
With the remarkable success achieved by Multimodal Large Language Models (MLLMs), numerous benchmarks have been designed to assess MLLMs' ability to guide their development in image perception tasks (e.g., image captioning and visual question answering). However, the existence of numerous benchmarks results in a substantial computational burden when evaluating model performance across all of them. Moreover, these benchmarks contain many overly simple problems or challenging samples, which do not effectively differentiate the capabilities among various MLLMs. To address these challenges, we propose a pipeline to process the existing benchmarks, which consists of two modules: (1) Semi-Automated Screening Process and (2) Eliminating Answer Leakage. The Semi-Automated Screening Process filters out samples that cannot distinguish the model's capabilities by synthesizing various MLLMs and manually evaluating them. The Eliminate Answer Leakage module filters samples whose answers can be inferred without images. Finally, we curate the LIME-M: Less Is More for Evaluation of Multimodal LLMs, a lightweight Multimodal benchmark that can more effectively evaluate the performance of different models. Our experiments demonstrate that: LIME-M can better distinguish the performance of different MLLMs with fewer samples (24% of the original) and reduced time (23% of the original); LIME-M eliminates answer leakage, focusing mainly on the information within images; The current automatic metric (i.e., CIDEr) is insufficient for evaluating MLLMs' capabilities in captioning. Moreover, removing the caption task score when calculating the overall score provides a more accurate reflection of model performance differences. All our codes and data are released at https://github.com/kangreen0210/LIME-M.
MMRA: A Benchmark for Evaluating Multi-Granularity and Multi-Image Relational Association Capabilities in Large Visual Language Models
Aug 06, 2024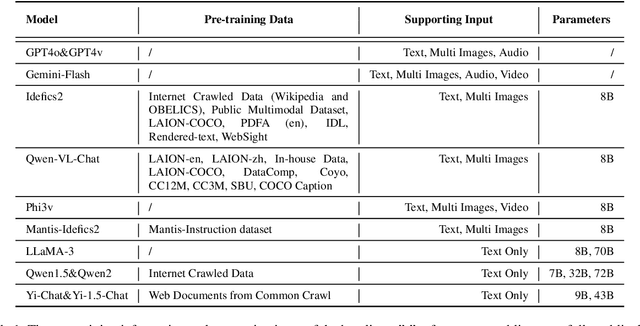



Given the remarkable success that large visual language models (LVLMs) have achieved in image perception tasks, the endeavor to make LVLMs perceive the world like humans is drawing increasing attention. Current multi-modal benchmarks primarily focus on facts or specific topic-related knowledge contained within individual images. However, they often overlook the associative relations between multiple images, which require the identification and analysis of similarities among entities or content present in different images. Therefore, we propose the multi-image relation association task and a meticulously curated Multi-granularity Multi-image Relational Association (MMRA) benchmark, comprising 1,024 samples. In order to systematically and comprehensively evaluate current LVLMs, we establish an associational relation system among images that contain 11 subtasks (e.g, UsageSimilarity, SubEvent) at two granularity levels (i.e., image and entity) according to the relations in ConceptNet. Our experiments reveal that on the MMRA benchmark, current multi-image LVLMs exhibit distinct advantages and disadvantages across various subtasks. Notably, fine-grained, entity-level multi-image perception tasks pose a greater challenge for LVLMs compared to image-level tasks. Moreover, LVLMs perform poorly on spatial-related tasks, indicating that LVLMs still have limited spatial awareness. Additionally, our findings indicate that while LVLMs demonstrate a strong capability to perceive image details, enhancing their ability to associate information across multiple images hinges on improving the reasoning capabilities of their language model component. Moreover, we explored the ability of LVLMs to perceive image sequences within the context of our multi-image association task. Our experiments show that the majority of current LVLMs do not adequately model image sequences during the pre-training process.