 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIQuest-Coder-V1 Technical Report
Mar 17, 2026In this report, we introduce the IQuest-Coder-V1 series-(7B/14B/40B/40B-Loop), a new family of code large language models (LLMs). Moving beyond static code representations, we propose the code-flow multi-stage training paradigm, which captures the dynamic evolution of software logic through different phases of the pipeline. Our models are developed through the evolutionary pipeline, starting with the initial pre-training consisting of code facts, repository, and completion data. Following that, we implement a specialized mid-training stage that integrates reasoning and agentic trajectories in 32k-context and repository-scale in 128k-context to forge deep logical foundations. The models are then finalized with post-training of specialized coding capabilities, which is bifurcated into two specialized paths: the thinking path (utilizing reasoning-driven RL) and the instruct path (optimized for general assistance). IQuest-Coder-V1 achieves state-of-the-art performance among competitive models across critical dimensions of code intelligence: agentic software engineering, competitive programming, and complex tool use. To address deployment constraints, the IQuest-Coder-V1-Loop variant introduces a recurrent mechanism designed to optimize the trade-off between model capacity and deployment footprint, offering an architecturally enhanced path for efficacy-efficiency trade-off. We believe the release of the IQuest-Coder-V1 series, including the complete white-box chain of checkpoints from pre-training bases to the final thinking and instruction models, will advance research in autonomous code intelligence and real-world agentic systems.
Controlled LLM Training on Spectral Sphere
Jan 13, 2026Scaling large models requires optimization strategies that ensure rapid convergence grounded in stability. Maximal Update Parametrization ($\boldsymbolμ$P) provides a theoretical safeguard for width-invariant $Θ(1)$ activation control, whereas emerging optimizers like Muon are only ``half-aligned'' with these constraints: they control updates but allow weights to drift. To address this limitation, we introduce the \textbf{Spectral Sphere Optimizer (SSO)}, which enforces strict module-wise spectral constraints on both weights and their updates. By deriving the steepest descent direction on the spectral sphere, SSO realizes a fully $\boldsymbolμ$P-aligned optimization process. To enable large-scale training, we implement SSO as an efficient parallel algorithm within Megatron. Through extensive pretraining on diverse architectures, including Dense 1.7B, MoE 8B-A1B, and 200-layer DeepNet models, SSO consistently outperforms AdamW and Muon. Furthermore, we observe significant practical stability benefits, including improved MoE router load balancing, suppressed outliers, and strictly bounded activations.
Rethinking KL Regularization in RLHF: From Value Estimation to Gradient Optimization
Oct 02, 2025Reinforcement Learning from Human Feedback (RLHF) leverages a Kullback-Leibler (KL) divergence loss to stabilize training and prevent overfitting. However, in methods such as GRPO, its implementation may be guided by principles from numerical value estimation-a practice that overlooks the term's functional role as an optimization loss. To analyze this issue, we establish a unified framework that connects two seemingly distinct implementation styles: using the mathematical term $k_n$ as a detached coefficient for the policy's score function ('$k_n$ in reward') or as a direct loss function through which gradients are propagated ('$k_n$ as loss'). We show that the latter can always be analyzed via an equivalent gradient coefficient in the former, unifying the two perspectives. Through this framework, we prove that the conventional '$k_1$ in reward' (like in PPO) is the principled loss for Reverse KL (RKL) regularization. We further establish a key finding: under on-policy conditions, the '$k_2$ as loss' formulation is, in fact, gradient-equivalent to '$k_1$ in reward'. This equivalence, first proven in our work, identifies both as the theoretically sound implementations of the RKL objective. In contrast, we show that the recently adopted '$k_3$ as loss' (like in GRPO) is merely a first-order, biased approximation of the principled loss. Furthermore, we argue that common off-policy implementations of '$k_n$ as loss' methods are biased due to neglected importance sampling, and we propose a principled correction. Our findings provide a comprehensive, gradient-based rationale for choosing and correctly implementing KL regularization, paving the way for more robust and effective RLHF systems.
The Choice of Divergence: A Neglected Key to Mitigating Diversity Collapse in Reinforcement Learning with Verifiable Reward
Sep 09, 2025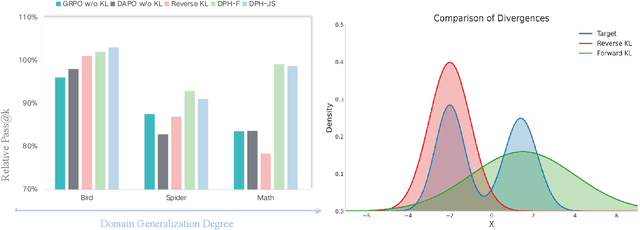

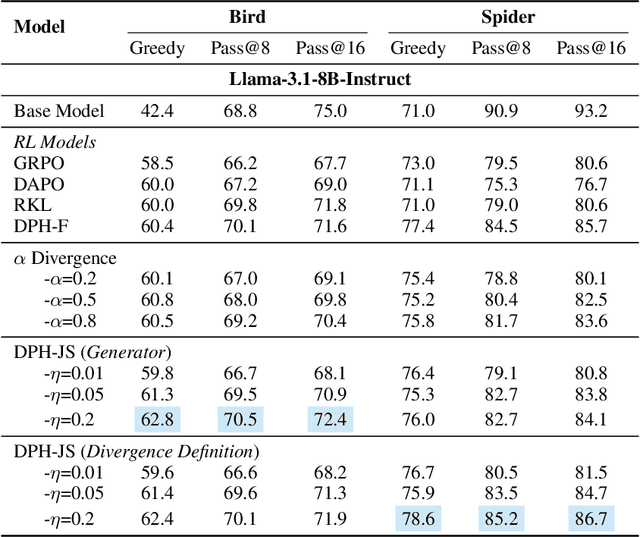
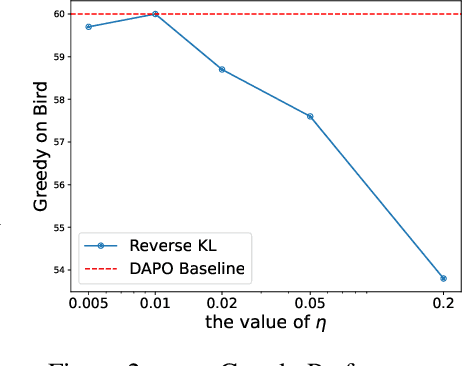
A central paradox in fine-tuning Large Language Models (LLMs) with Reinforcement Learning with Verifiable Reward (RLVR) is the frequent degradation of multi-attempt performance (Pass@k) despite improvements in single-attempt accuracy (Pass@1). This is often accompanied by catastrophic forgetting, where models lose previously acquired skills. While various methods have been proposed, the choice and function of the divergence term have been surprisingly unexamined as a proactive solution. We argue that standard RLVR objectives -- both those using the mode-seeking reverse KL-divergence and those forgoing a divergence term entirely -- lack a crucial mechanism for knowledge retention. The reverse-KL actively accelerates this decay by narrowing the policy, while its absence provides no safeguard against the model drifting from its diverse knowledge base. We propose a fundamental shift in perspective: using the divergence term itself as the solution. Our framework, Diversity-Preserving Hybrid RL (DPH-RL), leverages mass-covering f-divergences (like forward-KL and JS-divergence) to function as a rehearsal mechanism. By continuously referencing the initial policy, this approach forces the model to maintain broad solution coverage. Extensive experiments on math and SQL generation demonstrate that DPH-RL not only resolves the Pass@k degradation but improves both Pass@1 and Pass@k in- and out-of-domain. Additionally, DPH-RL is more training-efficient because it computes f-divergence using generator functions, requiring only sampling from the initial policy and no online reference model. Our work highlights a crucial, overlooked axis for improving RLVR, demonstrating that the proper selection of a divergence measure is a powerful tool for building more general and diverse reasoning models.
LeetCodeDataset: A Temporal Dataset for Robust Evaluation and Efficient Training of Code LLMs
Apr 20, 2025
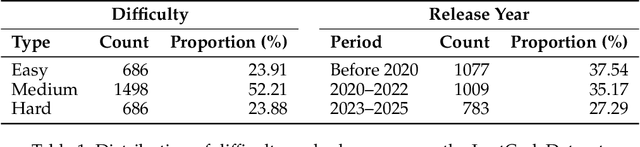
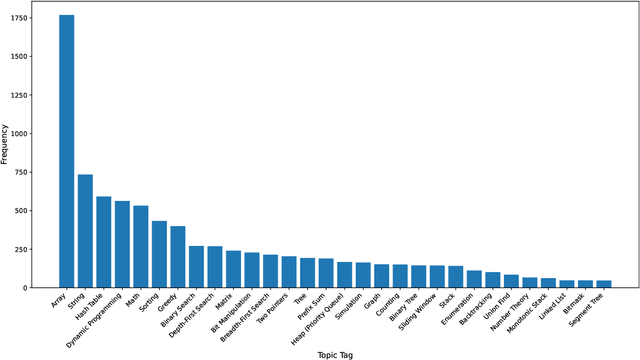
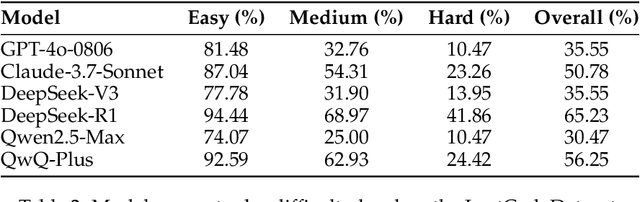
We introduce LeetCodeDataset, a high-quality benchmark for evaluating and training code-generation models, addressing two key challenges in LLM research: the lack of reasoning-focused coding benchmarks and self-contained training testbeds. By curating LeetCode Python problems with rich metadata, broad coverage, 100+ test cases per problem, and temporal splits (pre/post July 2024), our dataset enables contamination-free evaluation and efficient supervised fine-tuning (SFT). Experiments show reasoning models significantly outperform non-reasoning counterparts, while SFT with only 2.6K model-generated solutions achieves performance comparable to 110K-sample counterparts. The dataset and evaluation framework are available on Hugging Face and Github.
AdaptiveStep: Automatically Dividing Reasoning Step through Model Confidence
Feb 19, 2025Current approaches for training Process Reward Models (PRMs) often involve breaking down responses into multiple reasoning steps using rule-based techniques, such as using predefined placeholder tokens or setting the reasoning step's length into a fixed size. These approaches overlook the fact that specific words do not typically mark true decision points in a text. To address this, we propose AdaptiveStep, a method that divides reasoning steps based on the model's confidence in predicting the next word. This division method provides more decision-making information at each step, enhancing downstream tasks, such as reward model learning. Moreover, our method does not require manual annotation. We demonstrate its effectiveness through experiments with AdaptiveStep-trained PRMs in mathematical reasoning and code generation tasks. Experimental results indicate that the outcome PRM achieves state-of-the-art Best-of-N performance, surpassing greedy search strategy with token-level value-guided decoding, while also reducing construction costs by over 30% compared to existing open-source PRMs. In addition, we provide a thorough analysis and case study on the PRM's performance, transferability, and generalization capabilities.
OpenCoder: The Open Cookbook for Top-Tier Code Large Language Models
Nov 07, 2024



Large language models (LLMs) for code have become indispensable in various domains, including code generation, reasoning tasks and agent systems.While open-access code LLMs are increasingly approaching the performance levels of proprietary models, high-quality code LLMs suitable for rigorous scientific investigation, particularly those with reproducible data processing pipelines and transparent training protocols, remain limited. The scarcity is due to various challenges, including resource constraints, ethical considerations, and the competitive advantages of keeping models advanced. To address the gap, we introduce OpenCoder, a top-tier code LLM that not only achieves performance comparable to leading models but also serves as an ``open cookbook'' for the research community. Unlike most prior efforts, we release not only model weights and inference code, but also the reproducible training data, complete data processing pipeline, rigorous experimental ablation results, and detailed training protocols for open scientific research. Through this comprehensive release, we identify the key ingredients for building a top-tier code LLM: (1) code optimized heuristic rules for data cleaning and methods for data deduplication, (2) recall of text corpus related to code and (3) high-quality synthetic data in both annealing and supervised fine-tuning stages. By offering this level of openness, we aim to broaden access to all aspects of a top-tier code LLM, with OpenCoder serving as both a powerful model and an open foundation to accelerate research, and enable reproducible advancements in code AI.