 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenCoder: The Open Cookbook for Top-Tier Code Large Language Models
Nov 07, 2024



Large language models (LLMs) for code have become indispensable in various domains, including code generation, reasoning tasks and agent systems.While open-access code LLMs are increasingly approaching the performance levels of proprietary models, high-quality code LLMs suitable for rigorous scientific investigation, particularly those with reproducible data processing pipelines and transparent training protocols, remain limited. The scarcity is due to various challenges, including resource constraints, ethical considerations, and the competitive advantages of keeping models advanced. To address the gap, we introduce OpenCoder, a top-tier code LLM that not only achieves performance comparable to leading models but also serves as an ``open cookbook'' for the research community. Unlike most prior efforts, we release not only model weights and inference code, but also the reproducible training data, complete data processing pipeline, rigorous experimental ablation results, and detailed training protocols for open scientific research. Through this comprehensive release, we identify the key ingredients for building a top-tier code LLM: (1) code optimized heuristic rules for data cleaning and methods for data deduplication, (2) recall of text corpus related to code and (3) high-quality synthetic data in both annealing and supervised fine-tuning stages. By offering this level of openness, we aim to broaden access to all aspects of a top-tier code LLM, with OpenCoder serving as both a powerful model and an open foundation to accelerate research, and enable reproducible advancements in code AI.
Cross-Lingual Text-to-Speech Using Multi-Task Learning and Speaker Classifier Joint Training
Jan 20, 2022



In cross-lingual speech synthesis, the speech in various languages can be synthesized for a monoglot speaker. Normally, only the data of monoglot speakers are available for model training, thus the speaker similarity is relatively low between the synthesized cross-lingual speech and the native language recordings. Based on the multilingual transformer text-to-speech model, this paper studies a multi-task learning framework to improve the cross-lingual speaker similarity. To further improve the speaker similarity, joint training with a speaker classifier is proposed. Here, a scheme similar to parallel scheduled sampling is proposed to train the transformer model efficiently to avoid breaking the parallel training mechanism when introducing joint training. By using multi-task learning and speaker classifier joint training, in subjective and objective evaluations, the cross-lingual speaker similarity can be consistently improved for both the seen and unseen speakers in the training set.
PLIT: An alignment-free computational tool for identification of long non-coding RNAs in plant transcriptomic datasets
Feb 12, 2019
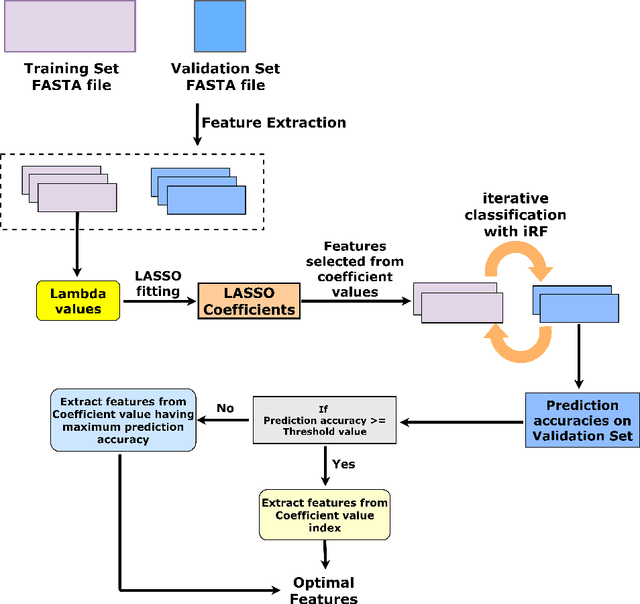

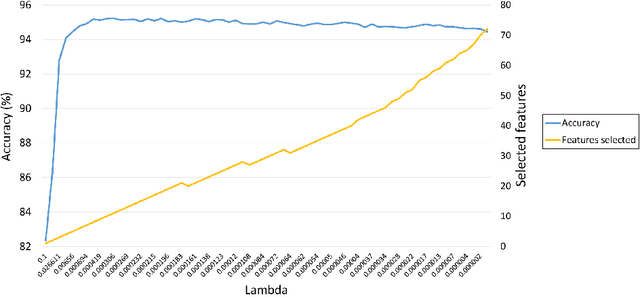
Long non-coding RNAs (lncRNAs) are a class of non-coding RNAs which play a significant role in several biological processes. RNA-seq based transcriptome sequencing has been extensively used for identification of lncRNAs. However, accurate identification of lncRNAs in RNA-seq datasets is crucial for exploring their characteristic functions in the genome as most coding potential computation (CPC) tools fail to accurately identify them in transcriptomic data. Well-known CPC tools such as CPC2, lncScore, CPAT are primarily designed for prediction of lncRNAs based on the GENCODE, NONCODE and CANTATAdb databases. The prediction accuracy of these tools often drops when tested on transcriptomic datasets. This leads to higher false positive results and inaccuracy in the function annotation process. In this study, we present a novel tool, PLIT, for the identification of lncRNAs in plants RNA-seq datasets. PLIT implements a feature selection method based on L1 regularization and iterative Random Forests (iRF) classification for selection of optimal features. Based on sequence and codon-bias features, it classifies the RNA-seq derived FASTA sequences into coding or long non-coding transcripts. Using L1 regularization, 31 optimal features were obtained based on lncRNA and protein-coding transcripts from 8 plant species. The performance of the tool was evaluated on 7 plant RNA-seq datasets using 10-fold cross-validation. The analysis exhibited superior accuracy when evaluated against currently available state-of-the-art CPC tools.
* 36 pages. Author's accepted version (Green OA)