 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeetCodeDataset: A Temporal Dataset for Robust Evaluation and Efficient Training of Code LLMs
Apr 20, 2025
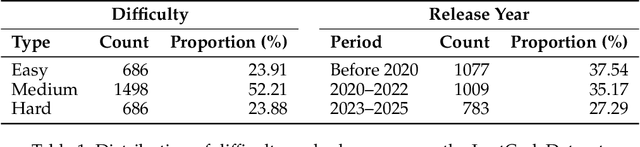
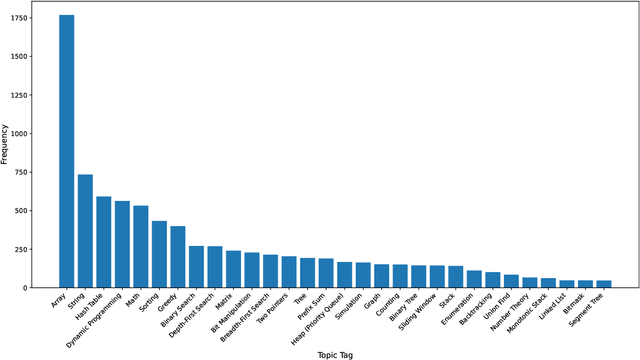
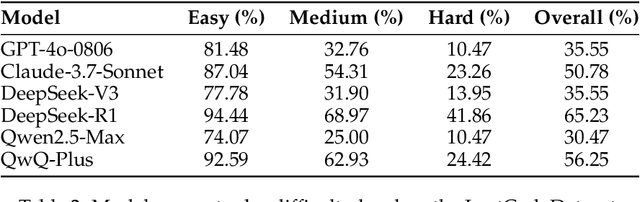
We introduce LeetCodeDataset, a high-quality benchmark for evaluating and training code-generation models, addressing two key challenges in LLM research: the lack of reasoning-focused coding benchmarks and self-contained training testbeds. By curating LeetCode Python problems with rich metadata, broad coverage, 100+ test cases per problem, and temporal splits (pre/post July 2024), our dataset enables contamination-free evaluation and efficient supervised fine-tuning (SFT). Experiments show reasoning models significantly outperform non-reasoning counterparts, while SFT with only 2.6K model-generated solutions achieves performance comparable to 110K-sample counterparts. The dataset and evaluation framework are available on Hugging Face and Github.
MCC-KD: Multi-CoT Consistent Knowledge Distillation
Oct 24, 2023Large language models (LLMs) have showcased remarkable capabilities in complex reasoning through chain of thought (CoT) prompting. Recently, there has been a growing interest in transferring these reasoning abilities from LLMs to smaller models. However, achieving both the diversity and consistency in rationales presents a challenge. In this paper, we focus on enhancing these two aspects and propose Multi-CoT Consistent Knowledge Distillation (MCC-KD) to efficiently distill the reasoning capabilities. In MCC-KD, we generate multiple rationales for each question and enforce consistency among the corresponding predictions by minimizing the bidirectional KL-divergence between the answer distributions. We investigate the effectiveness of MCC-KD with different model architectures (LLaMA/FlanT5) and various model scales (3B/7B/11B/13B) on both mathematical reasoning and commonsense reasoning benchmarks. The empirical results not only confirm MCC-KD's superior performance on in-distribution datasets but also highlight its robust generalization ability on out-of-distribution datasets.
AD-KD: Attribution-Driven Knowledge Distillation for Language Model Compression
May 17, 2023Knowledge distillation has attracted a great deal of interest recently to compress pre-trained language models. However, existing knowledge distillation methods suffer from two limitations. First, the student model simply imitates the teacher's behavior while ignoring the underlying reasoning. Second, these methods usually focus on the transfer of sophisticated model-specific knowledge but overlook data-specific knowledge. In this paper, we present a novel attribution-driven knowledge distillation approach, which explores the token-level rationale behind the teacher model based on Integrated Gradients (IG) and transfers attribution knowledge to the student model. To enhance the knowledge transfer of model reasoning and generalization, we further explore multi-view attribution distillation on all potential decisions of the teacher. Comprehensive experiments are conducted with BERT on the GLUE benchmark. The experimental results demonstrate the superior performance of our approach to several state-of-the-art methods.
Directed Acyclic Graph Network for Conversational Emotion Recognition
May 27, 2021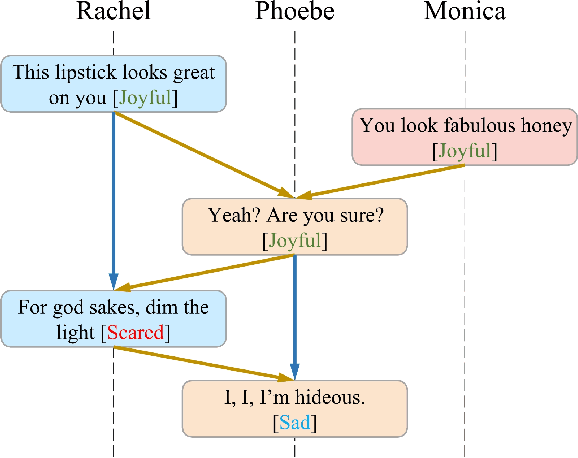
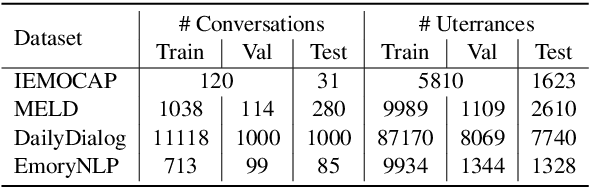
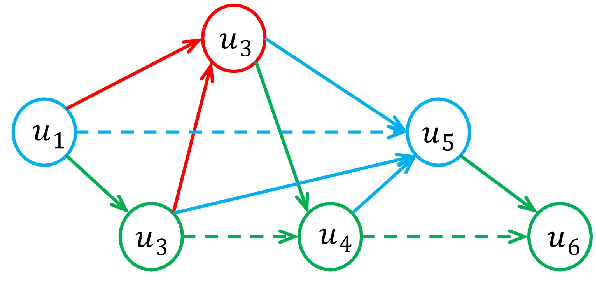
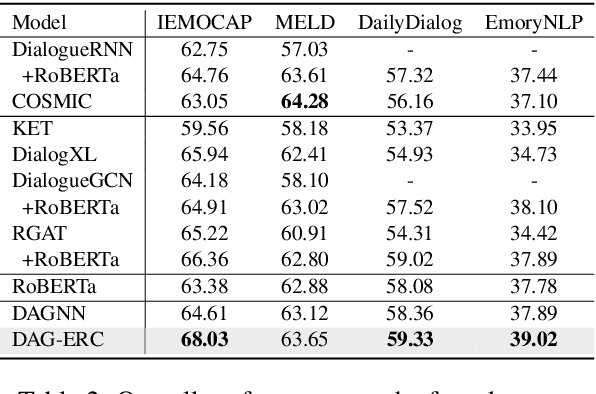
The modeling of conversational context plays a vital role in emotion recognition from conversation (ERC). In this paper, we put forward a novel idea of encoding the utterances with a directed acyclic graph (DAG) to better model the intrinsic structure within a conversation, and design a directed acyclic neural network,~namely DAG-ERC, to implement this idea.~In an attempt to combine the strengths of conventional graph-based neural models and recurrence-based neural models,~DAG-ERC provides a more intuitive way to model the information flow between long-distance conversation background and nearby context.~Extensive experiments are conducted on four ERC benchmarks with state-of-the-art models employed as baselines for comparison.~The empirical results demonstrate the superiority of this new model and confirm the motivation of the directed acyclic graph architecture for ERC.