 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeRM: A Generative Rendering Model From Physically Realistic to Photorealistic
Apr 10, 2026For decades, Physically-Based Rendering (PBR) is the fundation of synthesizing photorealisitic images, and therefore sometimes roughly referred as Photorealistic Rendering (PRR). While PBR is indeed a mathematical simulation of light transport that guarantees physical reality, photorealism has additional reliance on the realistic digital model of geometry and appearance of the real world, leaving a barely explored gap from PBR to PRR (P2P). Consequently, the path toward photorealism faces a critical dilemma: the explicit simulation of PRR encumbered by unreachable realistic digital models for real-world existence, while implicit generation models sacrifice controllability and geometric consistency. Based on this insight, this paper presents the problem, data, and approach of mitigating P2P gap, followed by the first multi-modal generative rendering model, dubbed GeRM, to unify PBR and PRR. GeRM integrates physical attributes like G-buffers with text prompts, and progressive incremental injection to generate controllable photorealistic images, allowing users to fluidly navigate the continuum between strict physical fidelity and perceptual photorealism. Technically, we model the transition between PBR and PRR images as a distribution transfer and aim to learn a distribution transfer vector field (DTV Field) to guide this process. To define the learning objective, we first leverage a multi-agent VLM framework to construct an expert-guided pairwise P2P transfer dataset, named P2P-50K, where each paired sample in the dataset corresponds to a transfer vector in the DTV Field. Subsequently, we propose a multi-condition ControlNet to learn the DTV Field, which synthesizes PBR images and progressively transitions them into PRR images, guided by G-buffers, text prompts, and cues for enhanced regions.
Adaptive Depth-converted-Scale Convolution for Self-supervised Monocular Depth Estimation
Apr 09, 2026Self-supervised monocular depth estimation (MDE) has received increasing interests in the last few years. The objects in the scene, including the object size and relationship among different objects, are the main clues to extract the scene structure. However, previous works lack the explicit handling of the changing sizes of the object due to the change of its depth. Especially in a monocular video, the size of the same object is continuously changed, resulting in size and depth ambiguity. To address this problem, we propose a Depth-converted-Scale Convolution (DcSConv) enhanced monocular depth estimation framework, by incorporating the prior relationship between the object depth and object scale to extract features from appropriate scales of the convolution receptive field. The proposed DcSConv focuses on the adaptive scale of the convolution filter instead of the local deformation of its shape. It establishes that the scale of the convolution filter matters no less (or even more in the evaluated task) than its local deformation. Moreover, a Depth-converted-Scale aware Fusion (DcS-F) is developed to adaptively fuse the DcSConv features and the conventional convolution features. Our DcSConv enhanced monocular depth estimation framework can be applied on top of existing CNN based methods as a plug-and-play module to enhance the conventional convolution block. Extensive experiments with different baselines have been conducted on the KITTI benchmark and our method achieves the best results with an improvement up to 11.6% in terms of SqRel reduction. Ablation study also validates the effectiveness of each proposed module.
LiftFormer: Lifting and Frame Theory Based Monocular Depth Estimation Using Depth and Edge Oriented Subspace Representation
Apr 08, 2026Monocular depth estimation (MDE) has attracted increasing interest in the past few years, owing to its important role in 3D vision. MDE is the estimation of a depth map from a monocular image/video to represent the 3D structure of a scene, which is a highly ill-posed problem. To solve this problem, in this paper, we propose a LiftFormer based on lifting theory topology, for constructing an intermediate subspace that bridges the image color features and depth values, and a subspace that enhances the depth prediction around edges. MDE is formulated by transforming the depth value prediction problem into depth-oriented geometric representation (DGR) subspace feature representation, thus bridging the learning from color values to geometric depth values. A DGR subspace is constructed based on frame theory by using linearly dependent vectors in accordance with depth bins to provide a redundant and robust representation. The image spatial features are transformed into the DGR subspace, where these features correspond directly to the depth values. Moreover, considering that edges usually present sharp changes in a depth map and tend to be erroneously predicted, an edge-aware representation (ER) subspace is constructed, where depth features are transformed and further used to enhance the local features around edges. The experimental results demonstrate that our LiftFormer achieves state-of-the-art performance on widely used datasets, and an ablation study validates the effectiveness of both proposed lifting modules in our LiftFormer.
Controlled LLM Training on Spectral Sphere
Jan 13, 2026Scaling large models requires optimization strategies that ensure rapid convergence grounded in stability. Maximal Update Parametrization ($\boldsymbolμ$P) provides a theoretical safeguard for width-invariant $Θ(1)$ activation control, whereas emerging optimizers like Muon are only ``half-aligned'' with these constraints: they control updates but allow weights to drift. To address this limitation, we introduce the \textbf{Spectral Sphere Optimizer (SSO)}, which enforces strict module-wise spectral constraints on both weights and their updates. By deriving the steepest descent direction on the spectral sphere, SSO realizes a fully $\boldsymbolμ$P-aligned optimization process. To enable large-scale training, we implement SSO as an efficient parallel algorithm within Megatron. Through extensive pretraining on diverse architectures, including Dense 1.7B, MoE 8B-A1B, and 200-layer DeepNet models, SSO consistently outperforms AdamW and Muon. Furthermore, we observe significant practical stability benefits, including improved MoE router load balancing, suppressed outliers, and strictly bounded activations.
OneStory: Coherent Multi-Shot Video Generation with Adaptive Memory
Dec 08, 2025
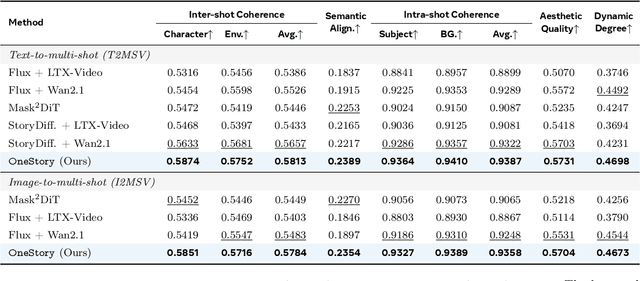
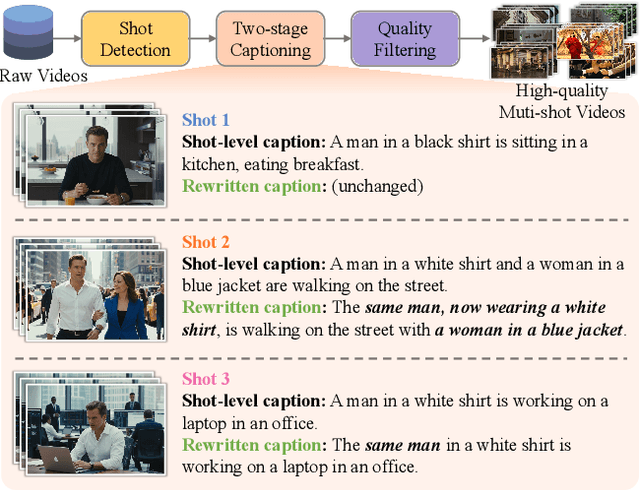

Storytelling in real-world videos often unfolds through multiple shots -- discontinuous yet semantically connected clips that together convey a coherent narrative. However, existing multi-shot video generation (MSV) methods struggle to effectively model long-range cross-shot context, as they rely on limited temporal windows or single keyframe conditioning, leading to degraded performance under complex narratives. In this work, we propose OneStory, enabling global yet compact cross-shot context modeling for consistent and scalable narrative generation. OneStory reformulates MSV as a next-shot generation task, enabling autoregressive shot synthesis while leveraging pretrained image-to-video (I2V) models for strong visual conditioning. We introduce two key modules: a Frame Selection module that constructs a semantically-relevant global memory based on informative frames from prior shots, and an Adaptive Conditioner that performs importance-guided patchification to generate compact context for direct conditioning. We further curate a high-quality multi-shot dataset with referential captions to mirror real-world storytelling patterns, and design effective training strategies under the next-shot paradigm. Finetuned from a pretrained I2V model on our curated 60K dataset, OneStory achieves state-of-the-art narrative coherence across diverse and complex scenes in both text- and image-conditioned settings, enabling controllable and immersive long-form video storytelling.
Mixture of States: Routing Token-Level Dynamics for Multimodal Generation
Nov 15, 2025We introduce MoS (Mixture of States), a novel fusion paradigm for multimodal diffusion models that merges modalities using flexible, state-based interactions. The core of MoS is a learnable, token-wise router that creates denoising timestep- and input-dependent interactions between modalities' hidden states, precisely aligning token-level features with the diffusion trajectory. This router sparsely selects the top-$k$ hidden states and is trained with an $ε$-greedy strategy, efficiently selecting contextual features with minimal learnable parameters and negligible computational overhead. We validate our design with text-to-image generation (MoS-Image) and editing (MoS-Editing), which achieve state-of-the-art results. With only 3B to 5B parameters, our models match or surpass counterparts up to $4\times$ larger. These findings establish MoS as a flexible and compute-efficient paradigm for scaling multimodal diffusion models.
High-Resolution Global Land Surface Temperature Retrieval via a Coupled Mechanism-Machine Learning Framework
Sep 05, 2025Land surface temperature (LST) is vital for land-atmosphere interactions and climate processes. Accurate LST retrieval remains challenging under heterogeneous land cover and extreme atmospheric conditions. Traditional split window (SW) algorithms show biases in humid environments; purely machine learning (ML) methods lack interpretability and generalize poorly with limited data. We propose a coupled mechanism model-ML (MM-ML) framework integrating physical constraints with data-driven learning for robust LST retrieval. Our approach fuses radiative transfer modeling with data components, uses MODTRAN simulations with global atmospheric profiles, and employs physics-constrained optimization. Validation against 4,450 observations from 29 global sites shows MM-ML achieves MAE=1.84K, RMSE=2.55K, and R-squared=0.966, outperforming conventional methods. Under extreme conditions, MM-ML reduces errors by over 50%. Sensitivity analysis indicates LST estimates are most sensitive to sensor radiance, then water vapor, and less to emissivity, with MM-ML showing superior stability. These results demonstrate the effectiveness of our coupled modeling strategy for retrieving geophysical parameters. The MM-ML framework combines physical interpretability with nonlinear modeling capacity, enabling reliable LST retrieval in complex environments and supporting climate monitoring and ecosystem studies.
Can LLMs Generate Reliable Test Case Generators? A Study on Competition-Level Programming Problems
Jun 07, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in code generation, capable of tackling complex tasks during inference. However, the extent to which LLMs can be utilized for code checking or debugging through test case generation remains largely unexplored. We investigate this problem from the perspective of competition-level programming (CP) programs and propose TCGBench, a Benchmark for (LLM generation of) Test Case Generators. This benchmark comprises two tasks, aimed at studying the capabilities of LLMs in (1) generating valid test case generators for a given CP problem, and further (2) generating targeted test case generators that expose bugs in human-written code. Experimental results indicate that while state-of-the-art LLMs can generate valid test case generators in most cases, most LLMs struggle to generate targeted test cases that reveal flaws in human code effectively. Especially, even advanced reasoning models (e.g., o3-mini) fall significantly short of human performance in the task of generating targeted generators. Furthermore, we construct a high-quality, manually curated dataset of instructions for generating targeted generators. Analysis demonstrates that the performance of LLMs can be enhanced with the aid of this dataset, by both prompting and fine-tuning.
ViaRL: Adaptive Temporal Grounding via Visual Iterated Amplification Reinforcement Learning
May 21, 2025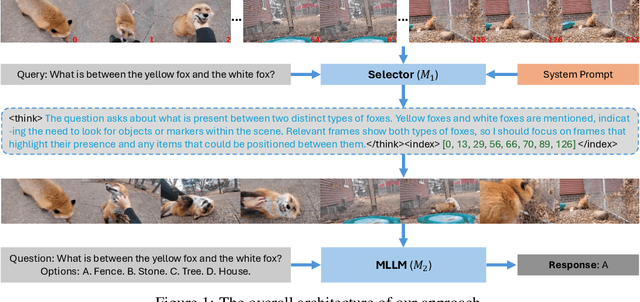
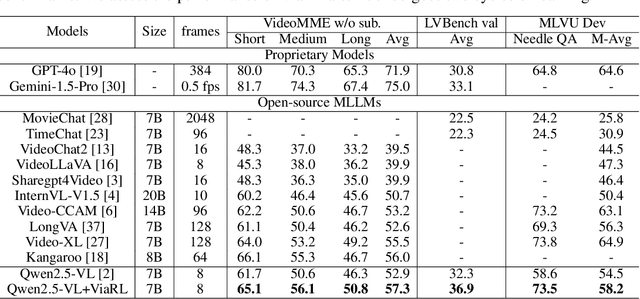
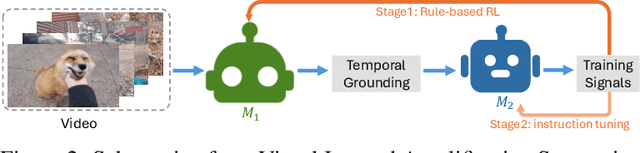

Video understanding is inherently intention-driven-humans naturally focus on relevant frames based on their goals. Recent advancements in multimodal large language models (MLLMs) have enabled flexible query-driven reasoning; however, video-based frameworks like Video Chain-of-Thought lack direct training signals to effectively identify relevant frames. Current approaches often rely on heuristic methods or pseudo-label supervised annotations, which are both costly and limited in scalability across diverse scenarios. To overcome these challenges, we introduce ViaRL, the first framework to leverage rule-based reinforcement learning (RL) for optimizing frame selection in intention-driven video understanding. An iterated amplification strategy is adopted to perform alternating cyclic training in the video CoT system, where each component undergoes iterative cycles of refinement to improve its capabilities. ViaRL utilizes the answer accuracy of a downstream model as a reward signal to train a frame selector through trial-and-error, eliminating the need for expensive annotations while closely aligning with human-like learning processes. Comprehensive experiments across multiple benchmarks, including VideoMME, LVBench, and MLVU, demonstrate that ViaRL consistently delivers superior temporal grounding performance and robust generalization across diverse video understanding tasks, highlighting its effectiveness and scalability. Notably, ViaRL achieves a nearly 15\% improvement on Needle QA, a subset of MLVU, which is required to search a specific needle within a long video and regarded as one of the most suitable benchmarks for evaluating temporal grounding.
Efficient RL Training for Reasoning Models via Length-Aware Optimization
May 18, 2025Large reasoning models, such as OpenAI o1 or DeepSeek R1, have demonstrated remarkable performance on reasoning tasks but often incur a long reasoning path with significant memory and time costs. Existing methods primarily aim to shorten reasoning paths by introducing additional training data and stages. In this paper, we propose three critical reward designs integrated directly into the reinforcement learning process of large reasoning models, which reduce the response length without extra training stages. Experiments on four settings show that our method significantly decreases response length while maintaining or even improving performance. Specifically, in a logic reasoning setting, we achieve a 40% reduction in response length averaged by steps alongside a 14% gain in performance. For math problems, we reduce response length averaged by steps by 33% while preserving performance.