 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiasCause: Evaluate Socially Biased Causal Reasoning of Large Language Models
Apr 08, 2025While large language models (LLMs) already play significant roles in society, research has shown that LLMs still generate content including social bias against certain sensitive groups. While existing benchmarks have effectively identified social biases in LLMs, a critical gap remains in our understanding of the underlying reasoning that leads to these biased outputs. This paper goes one step further to evaluate the causal reasoning process of LLMs when they answer questions eliciting social biases. We first propose a novel conceptual framework to classify the causal reasoning produced by LLMs. Next, we use LLMs to synthesize $1788$ questions covering $8$ sensitive attributes and manually validate them. The questions can test different kinds of causal reasoning by letting LLMs disclose their reasoning process with causal graphs. We then test 4 state-of-the-art LLMs. All models answer the majority of questions with biased causal reasoning, resulting in a total of $4135$ biased causal graphs. Meanwhile, we discover $3$ strategies for LLMs to avoid biased causal reasoning by analyzing the "bias-free" cases. Finally, we reveal that LLMs are also prone to "mistaken-biased" causal reasoning, where they first confuse correlation with causality to infer specific sensitive group names and then incorporate biased causal reasoning.
Backtracking for Safety
Mar 11, 2025Large language models (LLMs) have demonstrated remarkable capabilities across various tasks, but ensuring their safety and alignment with human values remains crucial. Current safety alignment methods, such as supervised fine-tuning and reinforcement learning-based approaches, can exhibit vulnerabilities to adversarial attacks and often result in shallow safety alignment, primarily focusing on preventing harmful content in the initial tokens of the generated output. While methods like resetting can help recover from unsafe generations by discarding previous tokens and restarting the generation process, they are not well-suited for addressing nuanced safety violations like toxicity that may arise within otherwise benign and lengthy generations. In this paper, we propose a novel backtracking method designed to address these limitations. Our method allows the model to revert to a safer generation state, not necessarily at the beginning, when safety violations occur during generation. This approach enables targeted correction of problematic segments without discarding the entire generated text, thereby preserving efficiency. We demonstrate that our method dramatically reduces toxicity appearing through the generation process with minimal impact to efficiency.
Gecko: Versatile Text Embeddings Distilled from Large Language Models
Mar 29, 2024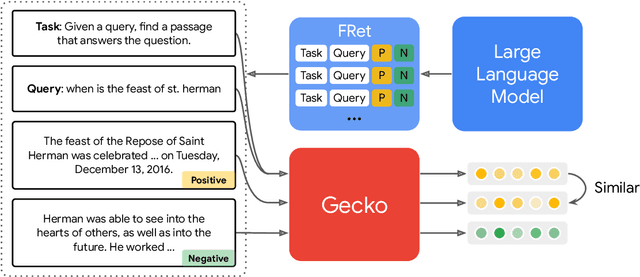
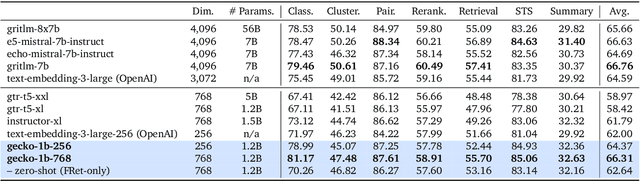

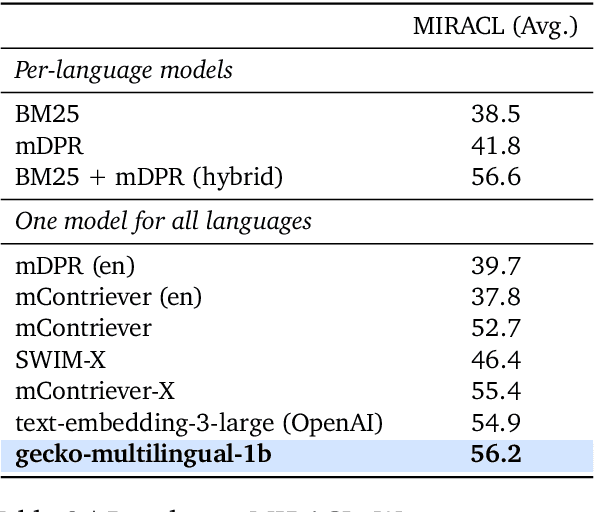
We present Gecko, a compact and versatile text embedding model. Gecko achieves strong retrieval performance by leveraging a key idea: distilling knowledge from large language models (LLMs) into a retriever. Our two-step distillation process begins with generating diverse, synthetic paired data using an LLM. Next, we further refine the data quality by retrieving a set of candidate passages for each query, and relabeling the positive and hard negative passages using the same LLM. The effectiveness of our approach is demonstrated by the compactness of the Gecko. On the Massive Text Embedding Benchmark (MTEB), Gecko with 256 embedding dimensions outperforms all existing entries with 768 embedding size. Gecko with 768 embedding dimensions achieves an average score of 66.31, competing with 7x larger models and 5x higher dimensional embeddings.
Logical Reasoning for Task Oriented Dialogue Systems
Feb 08, 2022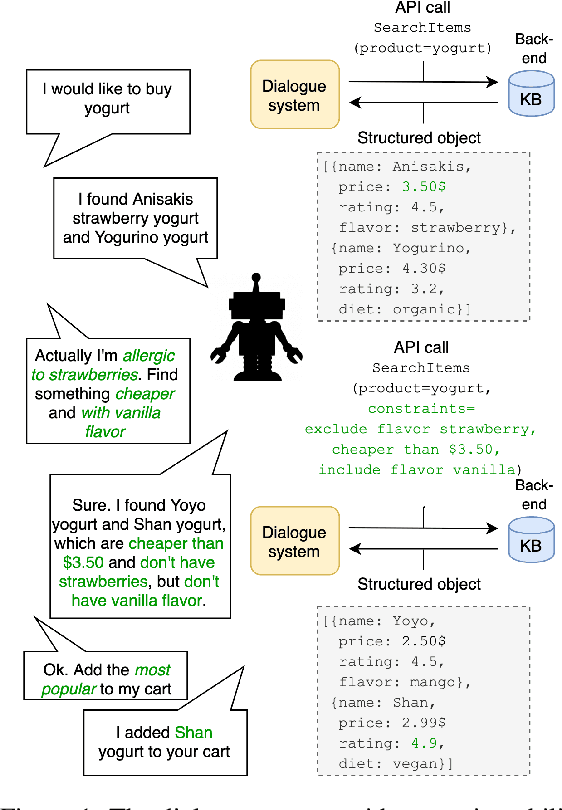

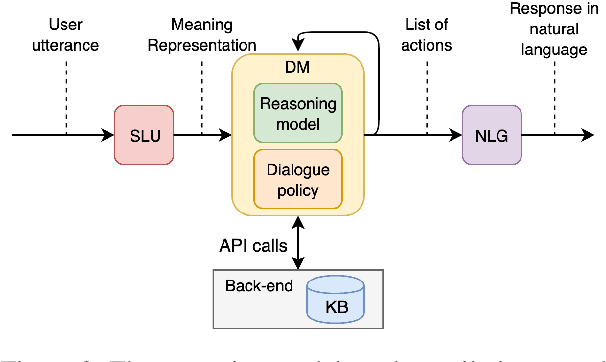

In recent years, large pretrained models have been used in dialogue systems to improve successful task completion rates. However, lack of reasoning capabilities of dialogue platforms make it difficult to provide relevant and fluent responses, unless the designers of a conversational experience spend a considerable amount of time implementing these capabilities in external rule based modules. In this work, we propose a novel method to fine-tune pretrained transformer models such as Roberta and T5. to reason over a set of facts in a given dialogue context. Our method includes a synthetic data generation mechanism which helps the model learn logical relations, such as comparison between list of numerical values, inverse relations (and negation), inclusion and exclusion for categorical attributes, and application of a combination of attributes over both numerical and categorical values, and spoken form for numerical values, without need for additional training dataset. We show that the transformer based model can perform logical reasoning to answer questions when the dialogue context contains all the required information, otherwise it is able to extract appropriate constraints to pass to downstream components (e.g. a knowledge base) when partial information is available. We observe that transformer based models such as UnifiedQA-T5 can be fine-tuned to perform logical reasoning (such as numerical and categorical attributes' comparison) over attributes that been seen in training time (e.g., accuracy of 90\%+ for comparison of smaller than $k_{\max}$=5 values over heldout test dataset).