 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Melody-to-Lyric Generation
May 30, 2023



Automatic melody-to-lyric generation is a task in which song lyrics are generated to go with a given melody. It is of significant practical interest and more challenging than unconstrained lyric generation as the music imposes additional constraints onto the lyrics. The training data is limited as most songs are copyrighted, resulting in models that underfit the complicated cross-modal relationship between melody and lyrics. In this work, we propose a method for generating high-quality lyrics without training on any aligned melody-lyric data. Specifically, we design a hierarchical lyric generation framework that first generates a song outline and second the complete lyrics. The framework enables disentanglement of training (based purely on text) from inference (melody-guided text generation) to circumvent the shortage of parallel data. We leverage the segmentation and rhythm alignment between melody and lyrics to compile the given melody into decoding constraints as guidance during inference. The two-step hierarchical design also enables content control via the lyric outline, a much-desired feature for democratizing collaborative song creation. Experimental results show that our model can generate high-quality lyrics that are more on-topic, singable, intelligible, and coherent than strong baselines, for example SongMASS, a SOTA model trained on a parallel dataset, with a 24% relative overall quality improvement based on human ratings. O
Unsupervised Melody-Guided Lyrics Generation
May 26, 2023



Automatic song writing is a topic of significant practical interest. However, its research is largely hindered by the lack of training data due to copyright concerns and challenged by its creative nature. Most noticeably, prior works often fall short of modeling the cross-modal correlation between melody and lyrics due to limited parallel data, hence generating lyrics that are less singable. Existing works also lack effective mechanisms for content control, a much desired feature for democratizing song creation for people with limited music background. In this work, we propose to generate pleasantly listenable lyrics without training on melody-lyric aligned data. Instead, we design a hierarchical lyric generation framework that disentangles training (based purely on text) from inference (melody-guided text generation). At inference time, we leverage the crucial alignments between melody and lyrics and compile the given melody into constraints to guide the generation process. Evaluation results show that our model can generate high-quality lyrics that are more singable, intelligible, coherent, and in rhyme than strong baselines including those supervised on parallel data.
ExPUNations: Augmenting Puns with Keywords and Explanations
Oct 24, 2022The tasks of humor understanding and generation are challenging and subjective even for humans, requiring commonsense and real-world knowledge to master. Puns, in particular, add the challenge of fusing that knowledge with the ability to interpret lexical-semantic ambiguity. In this paper, we present the ExPUNations (ExPUN) dataset, in which we augment an existing dataset of puns with detailed crowdsourced annotations of keywords denoting the most distinctive words that make the text funny, pun explanations describing why the text is funny, and fine-grained funniness ratings. This is the first humor dataset with such extensive and fine-grained annotations specifically for puns. Based on these annotations, we propose two tasks: explanation generation to aid with pun classification and keyword-conditioned pun generation, to challenge the current state-of-the-art natural language understanding and generation models' ability to understand and generate humor. We showcase that the annotated keywords we collect are helpful for generating better novel humorous texts in human evaluation, and that our natural language explanations can be leveraged to improve both the accuracy and robustness of humor classifiers.
Towards Large-Scale Interpretable Knowledge Graph Reasoning for Dialogue Systems
Mar 20, 2022
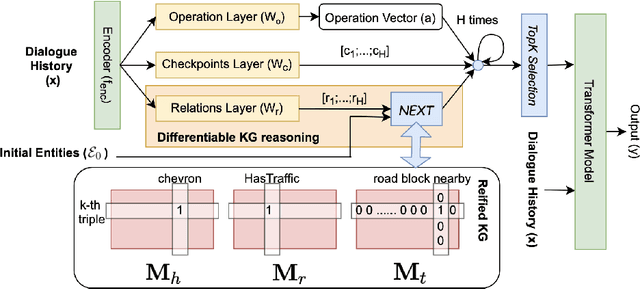
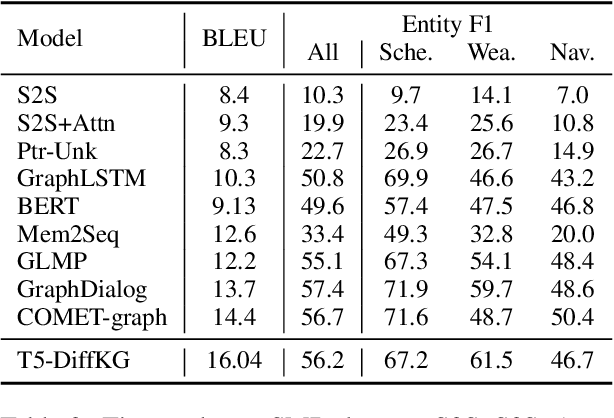
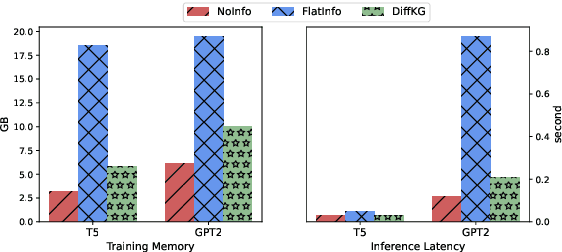
Users interacting with voice assistants today need to phrase their requests in a very specific manner to elicit an appropriate response. This limits the user experience, and is partly due to the lack of reasoning capabilities of dialogue platforms and the hand-crafted rules that require extensive labor. One possible way to improve user experience and relieve the manual efforts of designers is to build an end-to-end dialogue system that can do reasoning itself while perceiving user's utterances. In this work, we propose a novel method to incorporate the knowledge reasoning capability into dialogue systems in a more scalable and generalizable manner. Our proposed method allows a single transformer model to directly walk on a large-scale knowledge graph to generate responses. To the best of our knowledge, this is the first work to have transformer models generate responses by reasoning over differentiable knowledge graphs. We investigate the reasoning abilities of the proposed method on both task-oriented and domain-specific chit-chat dialogues. Empirical results show that this method can effectively and efficiently incorporate a knowledge graph into a dialogue system with fully-interpretable reasoning paths.
Logical Reasoning for Task Oriented Dialogue Systems
Feb 08, 2022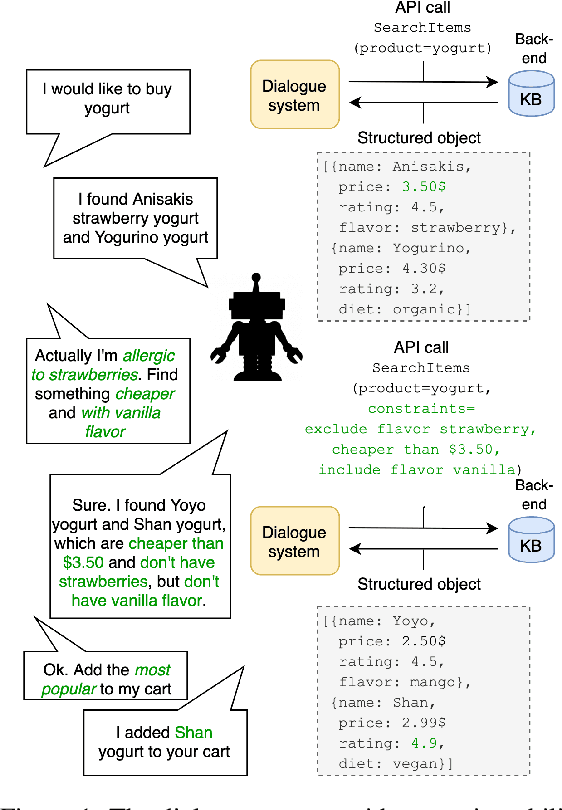

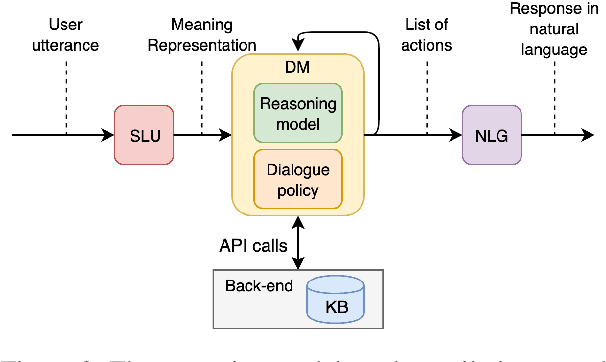

In recent years, large pretrained models have been used in dialogue systems to improve successful task completion rates. However, lack of reasoning capabilities of dialogue platforms make it difficult to provide relevant and fluent responses, unless the designers of a conversational experience spend a considerable amount of time implementing these capabilities in external rule based modules. In this work, we propose a novel method to fine-tune pretrained transformer models such as Roberta and T5. to reason over a set of facts in a given dialogue context. Our method includes a synthetic data generation mechanism which helps the model learn logical relations, such as comparison between list of numerical values, inverse relations (and negation), inclusion and exclusion for categorical attributes, and application of a combination of attributes over both numerical and categorical values, and spoken form for numerical values, without need for additional training dataset. We show that the transformer based model can perform logical reasoning to answer questions when the dialogue context contains all the required information, otherwise it is able to extract appropriate constraints to pass to downstream components (e.g. a knowledge base) when partial information is available. We observe that transformer based models such as UnifiedQA-T5 can be fine-tuned to perform logical reasoning (such as numerical and categorical attributes' comparison) over attributes that been seen in training time (e.g., accuracy of 90\%+ for comparison of smaller than $k_{\max}$=5 values over heldout test dataset).
Emotion Carrier Recognition from Personal Narratives
Aug 17, 2020

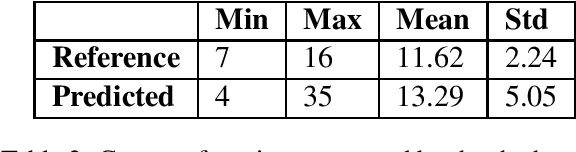

Personal Narratives (PN) - recollections of facts, events, and thoughts from one's own experience - are often used in everyday conversations. So far, PNs have mainly been explored for tasks such as valence prediction or emotion classification (i.e. happy, sad). However, these tasks might overlook more fine-grained information that could nevertheless prove relevant for understanding PNs. In this work, we propose a novel task for Narrative Understanding: Emotion Carrier Recognition (ECR). We argue that automatic recognition of emotion carriers, the text fragments that carry the emotions of the narrator (i.e. 'loss of a grandpa', 'high school reunion'), from PNs, provides a deeper level of emotion analysis needed, for instance, in the mental healthcare domain. In this work, we explore the task of ECR using a corpus of PNs manually annotated with emotion carriers and investigate different baseline models for the task. Furthermore, we propose several evaluation strategies for the task. Based on the inter-annotator agreement, the task in itself was found to be complex and subjective for humans. Nevertheless, we discuss evaluation metrics that could be suitable for applications based on ECR.
Is this Dialogue Coherent? Learning from Dialogue Acts and Entities
Jun 17, 2020
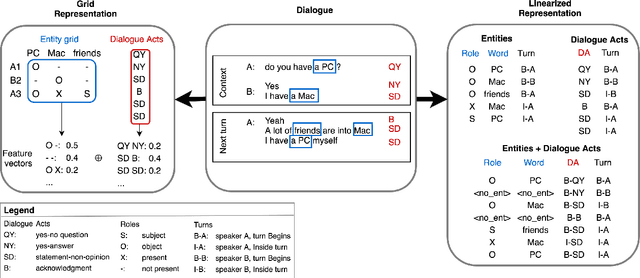

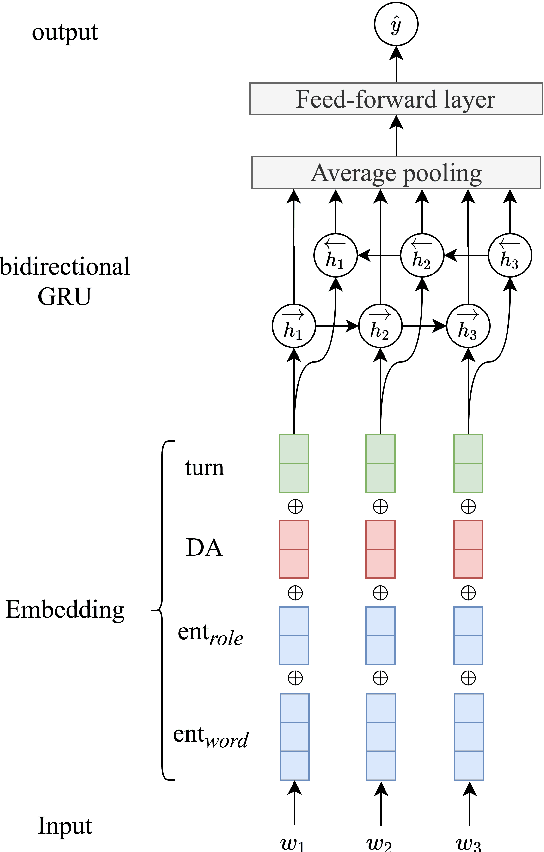
In this work, we investigate the human perception of coherence in open-domain dialogues. In particular, we address the problem of annotating and modeling the coherence of next-turn candidates while considering the entire history of the dialogue. First, we create the Switchboard Coherence (SWBD-Coh) corpus, a dataset of human-human spoken dialogues annotated with turn coherence ratings, where next-turn candidate utterances ratings are provided considering the full dialogue context. Our statistical analysis of the corpus indicates how turn coherence perception is affected by patterns of distribution of entities previously introduced and the Dialogue Acts used. Second, we experiment with different architectures to model entities, Dialogue Acts and their combination and evaluate their performance in predicting human coherence ratings on SWBD-Coh. We find that models combining both DA and entity information yield the best performances both for response selection and turn coherence rating.
Annotation of Emotion Carriers in Personal Narratives
Feb 28, 2020
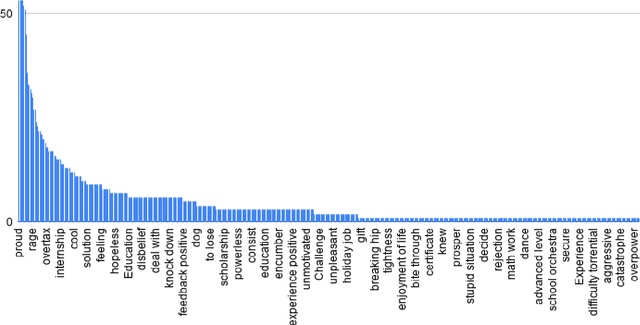
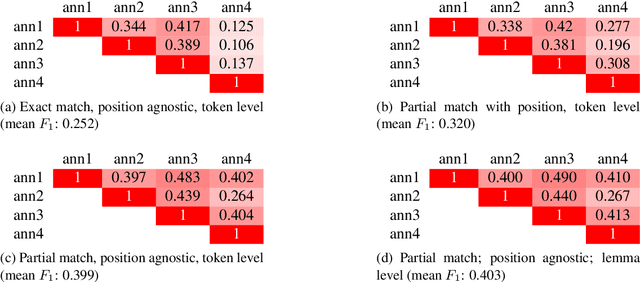
We are interested in the problem of understanding personal narratives (PN) - spoken or written - recollections of facts, events, and thoughts. In PN, emotion carriers are the speech or text segments that best explain the emotional state of the user. Such segments may include entities, verb or noun phrases. Advanced automatic understanding of PNs requires not only the prediction of the user emotional state but also to identify which events (e.g. "the loss of relative" or "the visit of grandpa") or people ( e.g. "the old group of high school mates") carry the emotion manifested during the personal recollection. This work proposes and evaluates an annotation model for identifying emotion carriers in spoken personal narratives. Compared to other text genres such as news and microblogs, spoken PNs are particularly challenging because a narrative is usually unstructured, involving multiple sub-events and characters as well as thoughts and associated emotions perceived by the narrator. In this work, we experiment with annotating emotion carriers from speech transcriptions in the Ulm State-of-Mind in Speech (USoMS) corpus, a dataset of German PNs. We believe this resource could be used for experiments in the automatic extraction of emotion carriers from PN, a task that could provide further advancements in narrative understanding.
Affective Behaviour Analysis of On-line User Interactions: Are On-line Support Groups more Therapeutic than Twitter?
Nov 04, 2019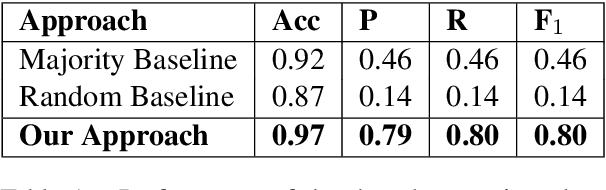
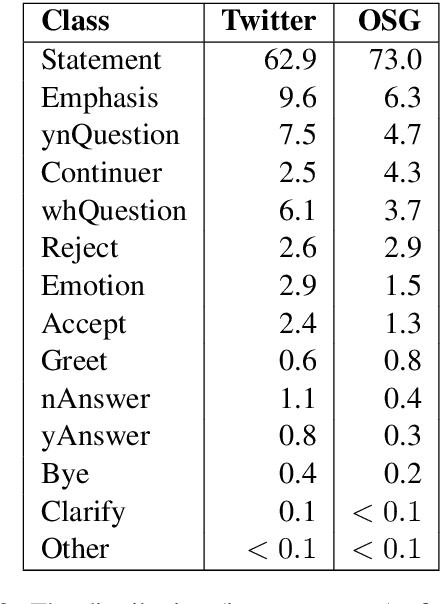
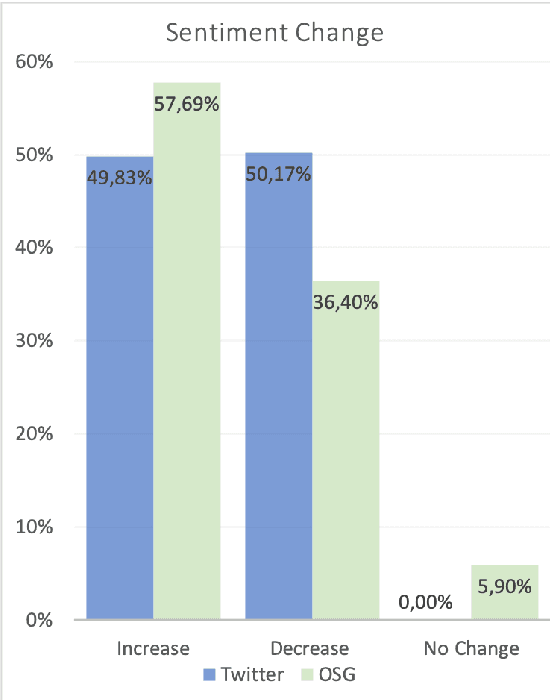
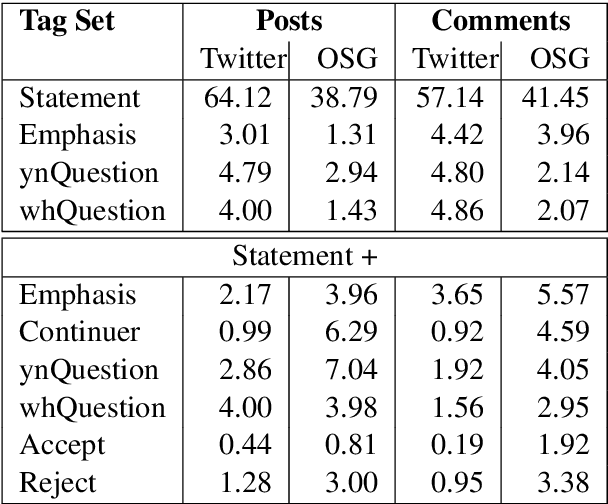
The increase in the prevalence of mental health problems has coincided with a growing popularity of health related social networking sites. Regardless of their therapeutic potential, On-line Support Groups (OSGs) can also have negative effects on patients. In this work we propose a novel methodology to automatically verify the presence of therapeutic factors in social networking websites by using Natural Language Processing (NLP) techniques. The methodology is evaluated on On-line asynchronous multi-party conversations collected from an OSG and Twitter. The results of the analysis indicate that therapeutic factors occur more frequently in OSG conversations than in Twitter conversations. Moreover, the analysis of OSG conversations reveals that the users of that platform are supportive, and interactions are likely to lead to the improvement of their emotional state. We believe that our method provides a stepping stone towards automatic analysis of emotional states of users of online platforms. Possible applications of the method include provision of guidelines that highlight potential implications of using such platforms on users' mental health, and/or support in the analysis of their impact on specific individuals.
Active Annotation: bootstrapping annotation lexicon and guidelines for supervised NLU learning
Aug 12, 2019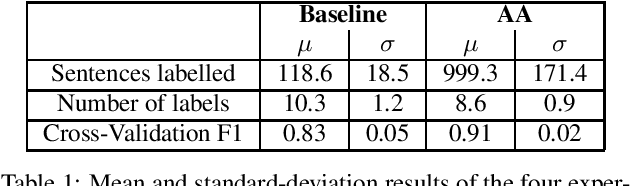
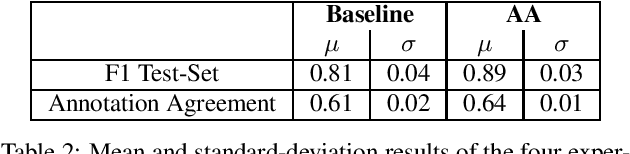
Natural Language Understanding (NLU) models are typically trained in a supervised learning framework. In the case of intent classification, the predicted labels are predefined and based on the designed annotation schema while the labelling process is based on a laborious task where annotators manually inspect each utterance and assign the corresponding label. We propose an Active Annotation (AA) approach where we combine an unsupervised learning method in the embedding space, a human-in-the-loop verification process, and linguistic insights to create lexicons that can be open categories and adapted over time. In particular, annotators define the y-label space on-the-fly during the annotation using an iterative process and without the need for prior knowledge about the input data. We evaluate the proposed annotation paradigm in a real use-case NLU scenario. Results show that our Active Annotation paradigm achieves accurate and higher quality training data, with an annotation speed of an order of magnitude higher with respect to the traditional human-only driven baseline annotation methodology.
* 4 pages