 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Gradient Analysis Framework for Rewarding Good and Penalizing Bad Examples in Language Models
Aug 29, 2024



Beyond maximum likelihood estimation (MLE), the standard objective of a language model (LM) that optimizes good examples probabilities, many studies have explored ways that also penalize bad examples for enhancing the quality of output distribution, including unlikelihood training, exponential maximizing average treatment effect (ExMATE), and direct preference optimization (DPO). To systematically compare these methods and further provide a unified recipe for LM optimization, in this paper, we present a unique angle of gradient analysis of loss functions that simultaneously reward good examples and penalize bad ones in LMs. Through both mathematical results and experiments on CausalDialogue and Anthropic HH-RLHF datasets, we identify distinct functional characteristics among these methods. We find that ExMATE serves as a superior surrogate for MLE, and that combining DPO with ExMATE instead of MLE further enhances both the statistical (5-7%) and generative (+18% win rate) performance.
Towards Safety and Helpfulness Balanced Responses via Controllable Large Language Models
Apr 01, 2024



As large language models (LLMs) become easily accessible nowadays, the trade-off between safety and helpfulness can significantly impact user experience. A model that prioritizes safety will cause users to feel less engaged and assisted while prioritizing helpfulness will potentially cause harm. Possible harms include teaching people how to build a bomb, exposing youth to inappropriate content, and hurting users' mental health. In this work, we propose to balance safety and helpfulness in diverse use cases by controlling both attributes in LLM. We explore training-free and fine-tuning methods that do not require extra human annotations and analyze the challenges of controlling safety and helpfulness in LLMs. Our experiments demonstrate that our method can rewind a learned model and unlock its controllability.
CausalDialogue: Modeling Utterance-level Causality in Conversations
Dec 20, 2022Despite their widespread adoption, neural conversation models have yet to exhibit natural chat capabilities with humans. In this research, we examine user utterances as causes and generated responses as effects, recognizing that changes in a cause should produce a different effect. To further explore this concept, we have compiled and expanded upon a new dataset called CausalDialogue through crowd-sourcing. This dataset includes multiple cause-effect pairs within a directed acyclic graph (DAG) structure. Our analysis reveals that traditional loss functions can struggle to effectively incorporate the DAG structure, leading us to propose a causality-enhanced method called Exponential Maximum Average Treatment Effect (ExMATE) to enhance the impact of causality at the utterance level in training neural conversation models. To evaluate the effectiveness of this approach, we have built a comprehensive benchmark using the CausalDialogue dataset leveraging large-scale pre-trained language models, and have assessed the results through both human and automatic evaluation metrics for coherence, diversity, and agility. Our findings show that current techniques are still unable to effectively address conversational DAGs, and that the ExMATE method can improve the diversity and agility of conventional loss functions while maintaining coherence.
Knowledge-Grounded Reinforcement Learning
Oct 07, 2022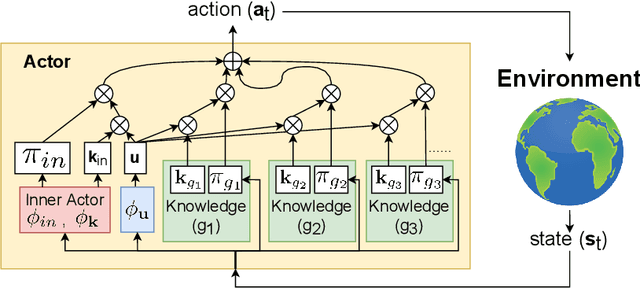
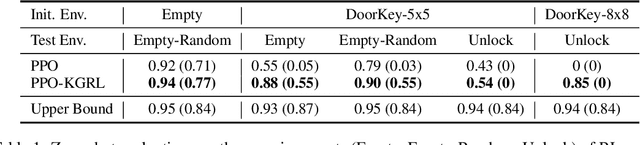
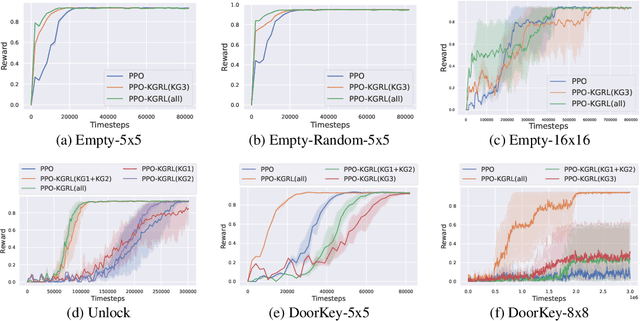

Receiving knowledge, abiding by laws, and being aware of regulations are common behaviors in human society. Bearing in mind that reinforcement learning (RL) algorithms benefit from mimicking humanity, in this work, we propose that an RL agent can act on external guidance in both its learning process and model deployment, making the agent more socially acceptable. We introduce the concept, Knowledge-Grounded RL (KGRL), with a formal definition that an agent learns to follow external guidelines and develop its own policy. Moving towards the goal of KGRL, we propose a novel actor model with an embedding-based attention mechanism that can attend to either a learnable internal policy or external knowledge. The proposed method is orthogonal to training algorithms, and the external knowledge can be flexibly recomposed, rearranged, and reused in both training and inference stages. Through experiments on tasks with discrete and continuous action space, our KGRL agent is shown to be more sample efficient and generalizable, and it has flexibly rearrangeable knowledge embeddings and interpretable behaviors.
Atomized Deep Learning Models
Oct 07, 2022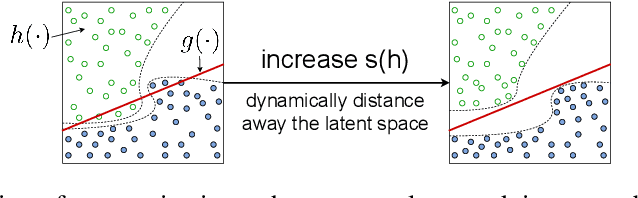
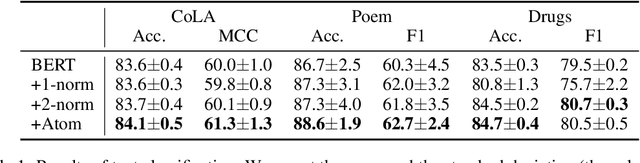
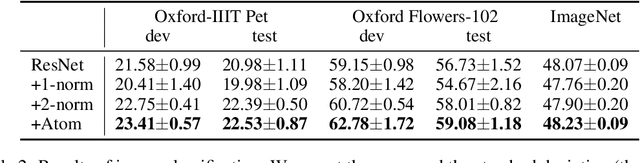
Deep learning models often tackle the intra-sample structure, such as the order of words in a sentence and pixels in an image, but have not pay much attention to the inter-sample relationship. In this paper, we show that explicitly modeling the inter-sample structure to be more discretized can potentially help model's expressivity. We propose a novel method, Atom Modeling, that can discretize a continuous latent space by drawing an analogy between a data point and an atom, which is naturally spaced away from other atoms with distances depending on their intra structures. Specifically, we model each data point as an atom composed of electrons, protons, and neutrons and minimize the potential energy caused by the interatomic force among data points. Through experiments with qualitative analysis in our proposed Atom Modeling on synthetic and real datasets, we find that Atom Modeling can improve the performance by maintaining the inter-sample relation and can capture an interpretable intra-sample relation by mapping each component in a data point to electron/proton/neutron.
FETA: A Benchmark for Few-Sample Task Transfer in Open-Domain Dialogue
May 12, 2022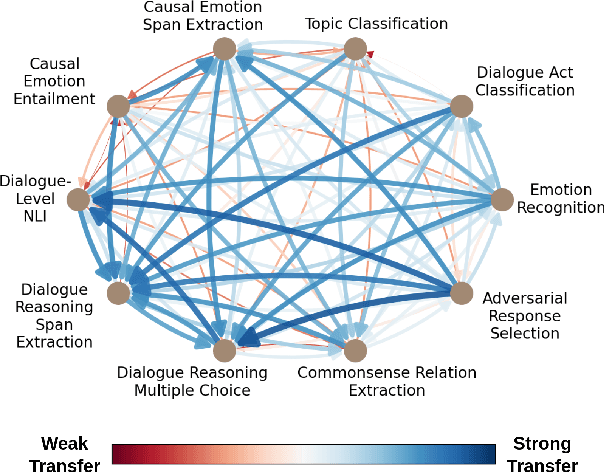
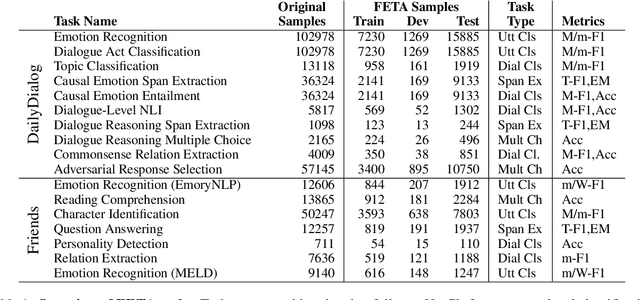
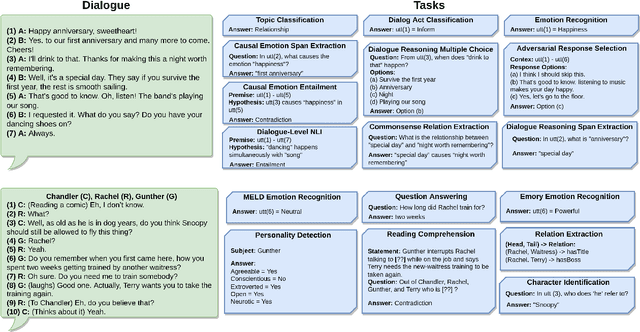
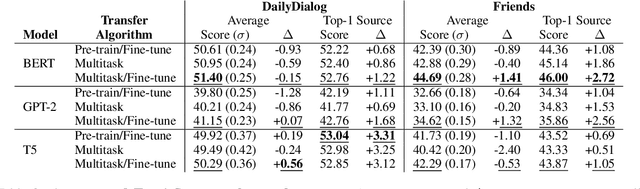
Task transfer, transferring knowledge contained in related tasks, holds the promise of reducing the quantity of labeled data required to fine-tune language models. Dialogue understanding encompasses many diverse tasks, yet task transfer has not been thoroughly studied in conversational AI. This work explores conversational task transfer by introducing FETA: a benchmark for few-sample task transfer in open-domain dialogue. FETA contains two underlying sets of conversations upon which there are 10 and 7 tasks annotated, enabling the study of intra-dataset task transfer; task transfer without domain adaptation. We utilize three popular language models and three learning algorithms to analyze the transferability between 132 source-target task pairs and create a baseline for future work. We run experiments in the single- and multi-source settings and report valuable findings, e.g., most performance trends are model-specific, and span extraction and multiple-choice tasks benefit the most from task transfer. In addition to task transfer, FETA can be a valuable resource for future research into the efficiency and generalizability of pre-training datasets and model architectures, as well as for learning settings such as continual and multitask learning.
HybriDialogue: An Information-Seeking Dialogue Dataset Grounded on Tabular and Textual Data
Apr 28, 2022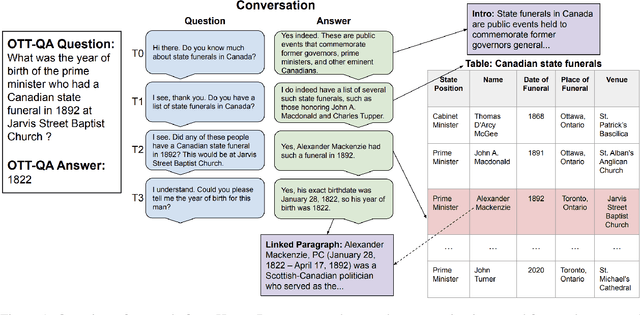
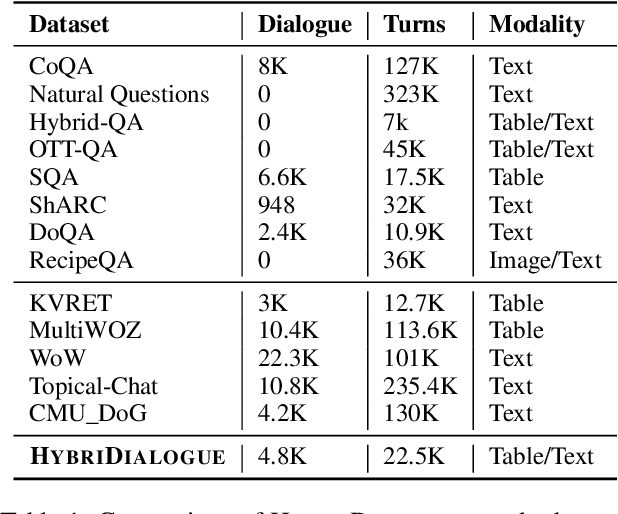
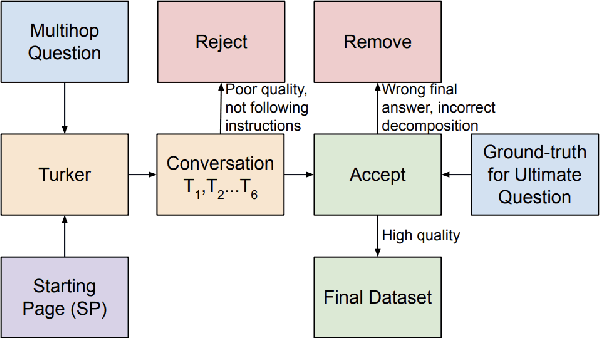
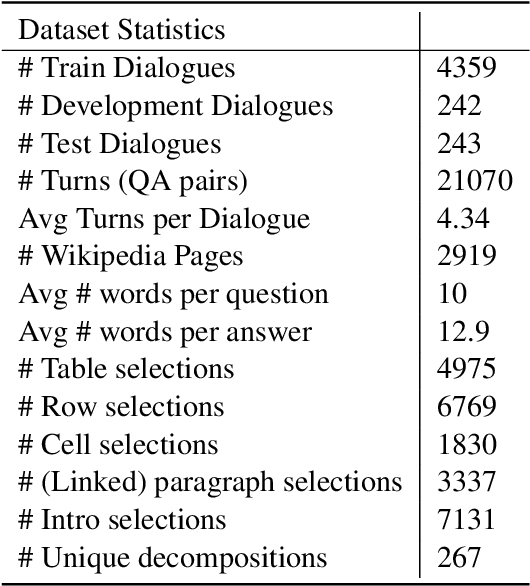
A pressing challenge in current dialogue systems is to successfully converse with users on topics with information distributed across different modalities. Previous work in multiturn dialogue systems has primarily focused on either text or table information. In more realistic scenarios, having a joint understanding of both is critical as knowledge is typically distributed over both unstructured and structured forms. We present a new dialogue dataset, HybriDialogue, which consists of crowdsourced natural conversations grounded on both Wikipedia text and tables. The conversations are created through the decomposition of complex multihop questions into simple, realistic multiturn dialogue interactions. We propose retrieval, system state tracking, and dialogue response generation tasks for our dataset and conduct baseline experiments for each. Our results show that there is still ample opportunity for improvement, demonstrating the importance of building stronger dialogue systems that can reason over the complex setting of information-seeking dialogue grounded on tables and text.
Towards Large-Scale Interpretable Knowledge Graph Reasoning for Dialogue Systems
Mar 20, 2022
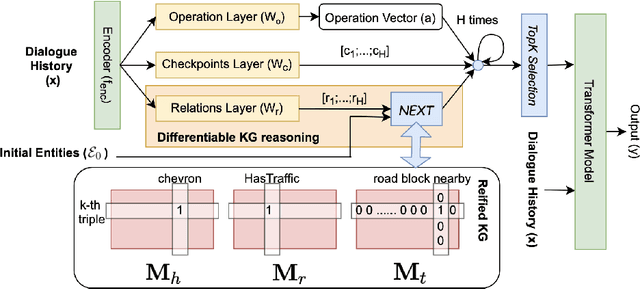
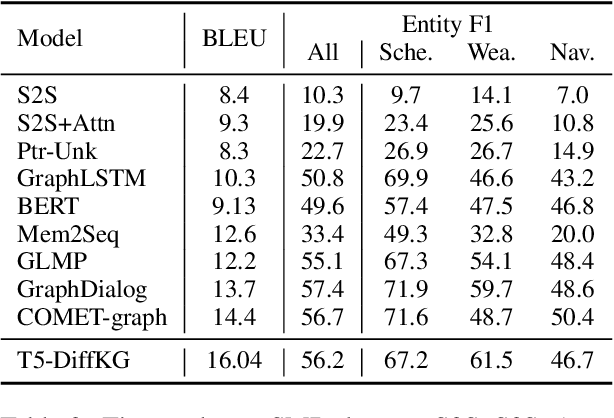
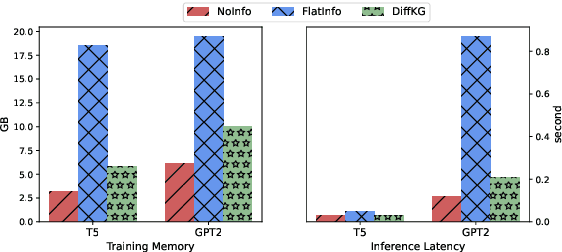
Users interacting with voice assistants today need to phrase their requests in a very specific manner to elicit an appropriate response. This limits the user experience, and is partly due to the lack of reasoning capabilities of dialogue platforms and the hand-crafted rules that require extensive labor. One possible way to improve user experience and relieve the manual efforts of designers is to build an end-to-end dialogue system that can do reasoning itself while perceiving user's utterances. In this work, we propose a novel method to incorporate the knowledge reasoning capability into dialogue systems in a more scalable and generalizable manner. Our proposed method allows a single transformer model to directly walk on a large-scale knowledge graph to generate responses. To the best of our knowledge, this is the first work to have transformer models generate responses by reasoning over differentiable knowledge graphs. We investigate the reasoning abilities of the proposed method on both task-oriented and domain-specific chit-chat dialogues. Empirical results show that this method can effectively and efficiently incorporate a knowledge graph into a dialogue system with fully-interpretable reasoning paths.
Deep Learning-Based Perceptual Stimulus Encoder for Bionic Vision
Mar 10, 2022

Retinal implants have the potential to treat incurable blindness, yet the quality of the artificial vision they produce is still rudimentary. An outstanding challenge is identifying electrode activation patterns that lead to intelligible visual percepts (phosphenes). Here we propose a PSE based on CNN that is trained in an end-to-end fashion to predict the electrode activation patterns required to produce a desired visual percept. We demonstrate the effectiveness of the encoder on MNIST using a psychophysically validated phosphene model tailored to individual retinal implant users. The present work constitutes an essential first step towards improving the quality of the artificial vision provided by retinal implants.
D-REX: Dialogue Relation Extraction with Explanations
Sep 10, 2021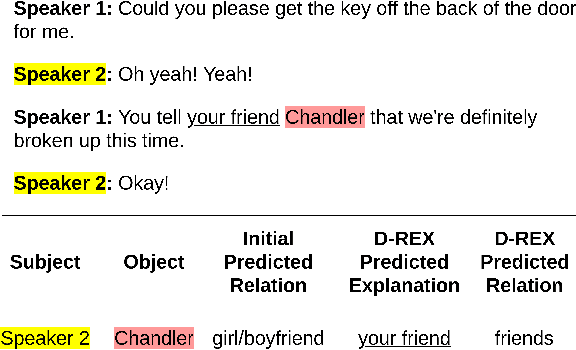

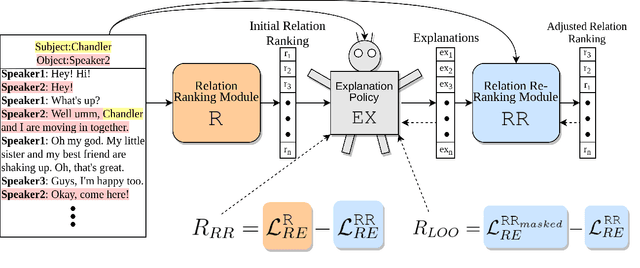
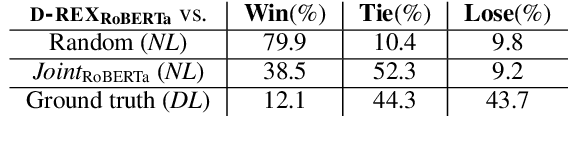
Existing research studies on cross-sentence relation extraction in long-form multi-party conversations aim to improve relation extraction without considering the explainability of such methods. This work addresses that gap by focusing on extracting explanations that indicate that a relation exists while using only partially labeled data. We propose our model-agnostic framework, D-REX, a policy-guided semi-supervised algorithm that explains and ranks relations. We frame relation extraction as a re-ranking task and include relation- and entity-specific explanations as an intermediate step of the inference process. We find that about 90% of the time, human annotators prefer D-REX's explanations over a strong BERT-based joint relation extraction and explanation model. Finally, our evaluations on a dialogue relation extraction dataset show that our method is simple yet effective and achieves a state-of-the-art F1 score on relation extraction, improving upon existing methods by 13.5%.