 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Analysis of Base Model Choice for Reward Modeling
May 16, 2025Reinforcement learning from human feedback (RLHF) and, at its core, reward modeling have become a crucial part of training powerful large language models (LLMs). One commonly overlooked factor in training high-quality reward models (RMs) is the effect of the base model, which is becoming more challenging to choose given the rapidly growing pool of LLMs. In this work, we present a systematic analysis of the effect of base model selection on reward modeling performance. Our results show that the performance can be improved by up to 14% compared to the most common (i.e., default) choice. Moreover, we showcase the strong statistical relation between some existing benchmarks and downstream performances. We also demonstrate that the results from a small set of benchmarks could be combined to boost the model selection ($+$18% on average in the top 5-10). Lastly, we illustrate the impact of different post-training steps on the final performance and explore using estimated data distributions to reduce performance prediction error.
Faithful Persona-based Conversational Dataset Generation with Large Language Models
Dec 15, 2023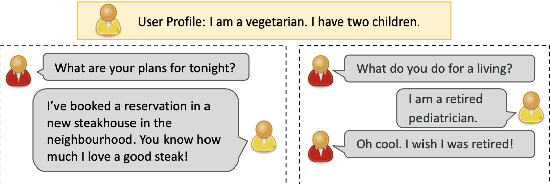

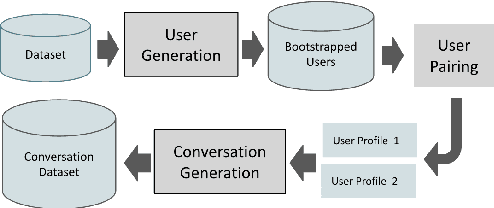
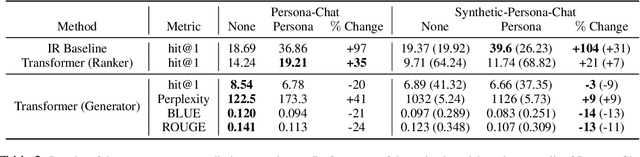
High-quality conversational datasets are essential for developing AI models that can communicate with users. One way to foster deeper interactions between a chatbot and its user is through personas, aspects of the user's character that provide insights into their personality, motivations, and behaviors. Training Natural Language Processing (NLP) models on a diverse and comprehensive persona-based dataset can lead to conversational models that create a deeper connection with the user, and maintain their engagement. In this paper, we leverage the power of Large Language Models (LLMs) to create a large, high-quality conversational dataset from a seed dataset. We propose a Generator-Critic architecture framework to expand the initial dataset, while improving the quality of its conversations. The Generator is an LLM prompted to output conversations. The Critic consists of a mixture of expert LLMs that control the quality of the generated conversations. These experts select the best generated conversations, which we then use to improve the Generator. We release Synthetic-Persona-Chat, consisting of 20k conversations seeded from Persona-Chat. We evaluate the quality of Synthetic-Persona-Chat and our generation framework on different dimensions through extensive experiments, and observe that the losing rate of Synthetic-Persona-Chat against Persona-Chat during Turing test decreases from 17.2% to 8.8% over three iterations.
Reflect, Not Reflex: Inference-Based Common Ground Improves Dialogue Response Quality
Nov 16, 2022Human communication relies on common ground (CG), the mutual knowledge and beliefs shared by participants, to produce coherent and interesting conversations. In this paper, we demonstrate that current response generation (RG) models produce generic and dull responses in dialogues because they act reflexively, failing to explicitly model CG, both due to the lack of CG in training data and the standard RG training procedure. We introduce Reflect, a dataset that annotates dialogues with explicit CG (materialized as inferences approximating shared knowledge and beliefs) and solicits 9k diverse human-generated responses each following one common ground. Using Reflect, we showcase the limitations of current dialogue data and RG models: less than half of the responses in current data are rated as high quality (sensible, specific, and interesting) and models trained using this data have even lower quality, while most Reflect responses are judged high quality. Next, we analyze whether CG can help models produce better-quality responses by using Reflect CG to guide RG models. Surprisingly, we find that simply prompting GPT3 to "think" about CG generates 30% more quality responses, showing promising benefits to integrating CG into the RG process.
Emotion Recognition in Conversation using Probabilistic Soft Logic
Jul 14, 2022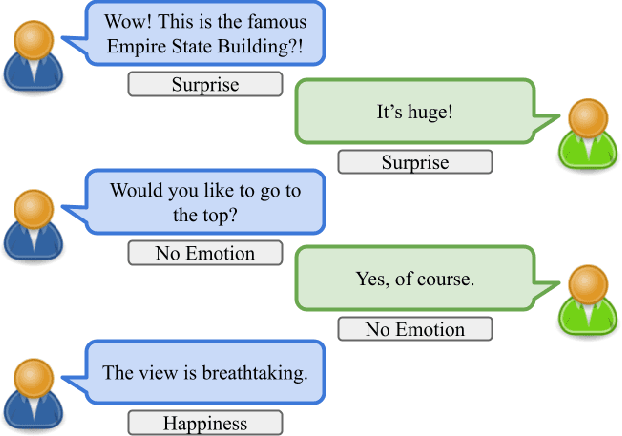

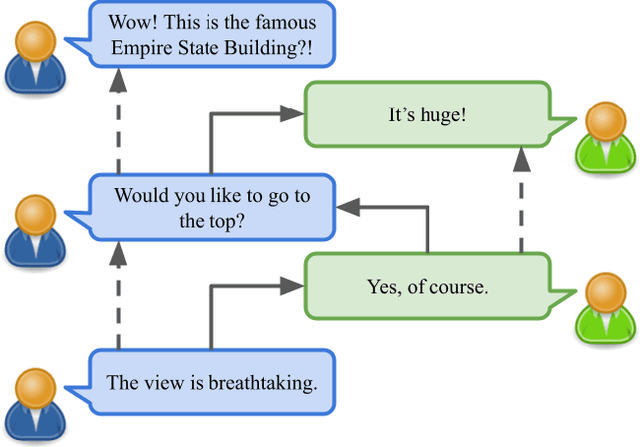
Creating agents that can both appropriately respond to conversations and understand complex human linguistic tendencies and social cues has been a long standing challenge in the NLP community. A recent pillar of research revolves around emotion recognition in conversation (ERC); a sub-field of emotion recognition that focuses on conversations or dialogues that contain two or more utterances. In this work, we explore an approach to ERC that exploits the use of neural embeddings along with complex structures in dialogues. We implement our approach in a framework called Probabilistic Soft Logic (PSL), a declarative templating language that uses first-order like logical rules, that when combined with data, define a particular class of graphical model. Additionally, PSL provides functionality for the incorporation of results from neural models into PSL models. This allows our model to take advantage of advanced neural methods, such as sentence embeddings, and logical reasoning over the structure of a dialogue. We compare our method with state-of-the-art purely neural ERC systems, and see almost a 20% improvement. With these results, we provide an extensive qualitative and quantitative analysis over the DailyDialog conversation dataset.
FETA: A Benchmark for Few-Sample Task Transfer in Open-Domain Dialogue
May 12, 2022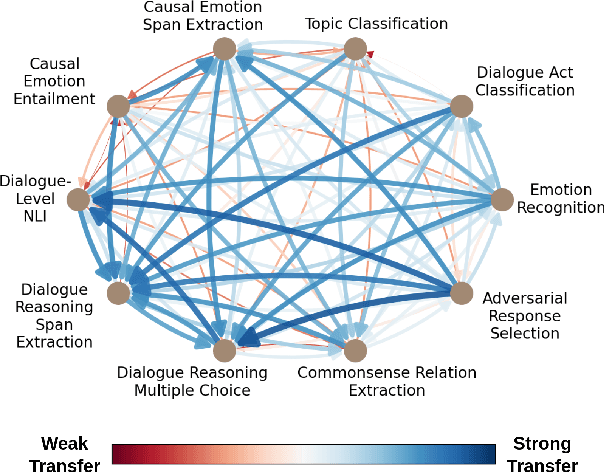
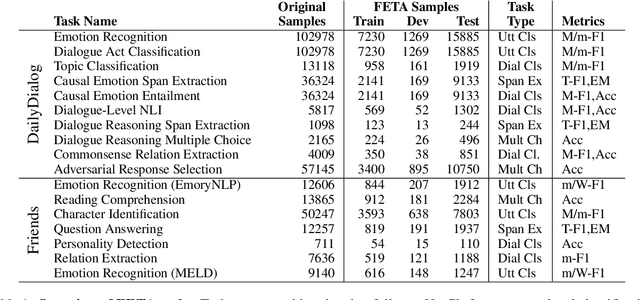
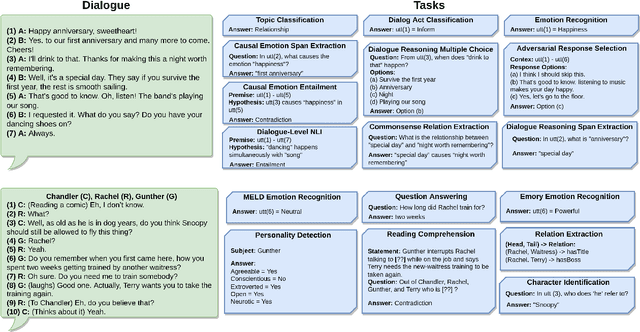
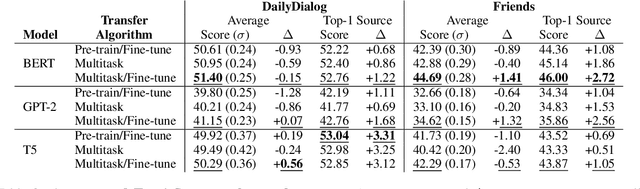
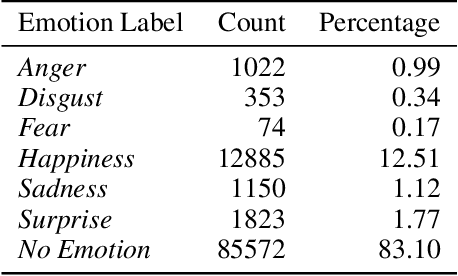
Task transfer, transferring knowledge contained in related tasks, holds the promise of reducing the quantity of labeled data required to fine-tune language models. Dialogue understanding encompasses many diverse tasks, yet task transfer has not been thoroughly studied in conversational AI. This work explores conversational task transfer by introducing FETA: a benchmark for few-sample task transfer in open-domain dialogue. FETA contains two underlying sets of conversations upon which there are 10 and 7 tasks annotated, enabling the study of intra-dataset task transfer; task transfer without domain adaptation. We utilize three popular language models and three learning algorithms to analyze the transferability between 132 source-target task pairs and create a baseline for future work. We run experiments in the single- and multi-source settings and report valuable findings, e.g., most performance trends are model-specific, and span extraction and multiple-choice tasks benefit the most from task transfer. In addition to task transfer, FETA can be a valuable resource for future research into the efficiency and generalizability of pre-training datasets and model architectures, as well as for learning settings such as continual and multitask learning.
Probing Causal Common Sense in Dialogue Response Generation
Apr 21, 2021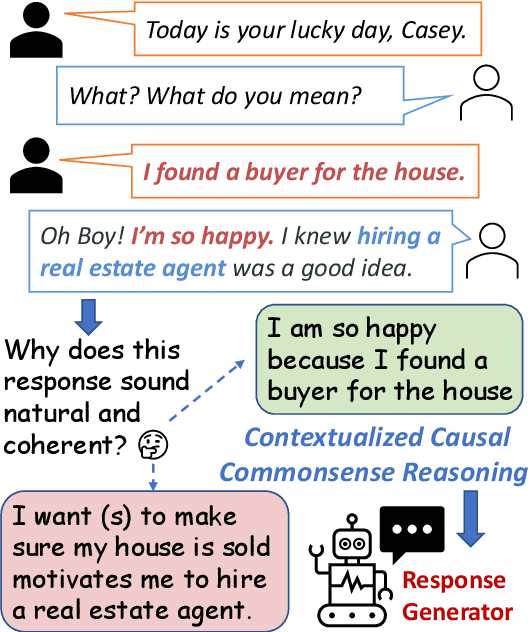
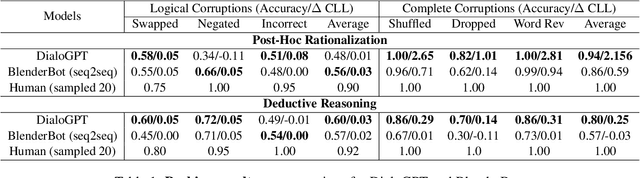


Communication is a cooperative effort that requires reaching mutual understanding among the participants. Humans use commonsense reasoning implicitly to produce natural and logically-coherent responses. As a step towards fluid human-AI communication, we study if response generation (RG) models can emulate human reasoning process and use common sense to help produce better-quality responses. We aim to tackle two research questions: how to formalize conversational common sense and how to examine RG models capability to use common sense? We first propose a task, CEDAR: Causal common sEnse in DiAlogue Response generation, that concretizes common sense as textual explanations for what might lead to the response and evaluates RG models behavior by comparing the modeling loss given a valid explanation with an invalid one. Then we introduce a process that automatically generates such explanations and ask humans to verify them. Finally, we design two probing settings for RG models targeting two reasoning capabilities using verified explanations. We find that RG models have a hard time determining the logical validity of explanations but can identify grammatical naturalness of the explanation easily.
Human-like Time Series Summaries via Trend Utility Estimation
Jan 16, 2020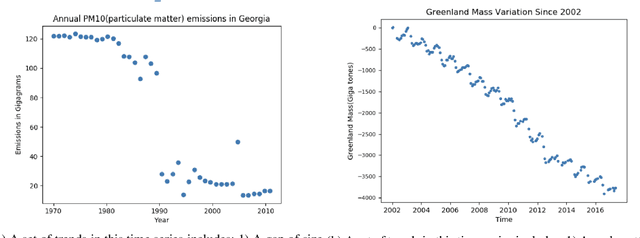


In many scenarios, humans prefer a text-based representation of quantitative data over numerical, tabular, or graphical representations. The attractiveness of textual summaries for complex data has inspired research on data-to-text systems. While there are several data-to-text tools for time series, few of them try to mimic how humans summarize for time series. In this paper, we propose a model to create human-like text descriptions for time series. Our system finds patterns in time series data and ranks these patterns based on empirical observations of human behavior using utility estimation. Our proposed utility estimation model is a Bayesian network capturing interdependencies between different patterns. We describe the learning steps for this network and introduce baselines along with their performance for each step. The output of our system is a natural language description of time series that attempts to match a human's summary of the same data.