 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJudgmentBench: Comparing Rubric and Preference Evaluation for Quality Assessment
May 24, 2026Two methodologies dominate current practices of benchmarking: rubric-based scoring evaluates items against predefined criteria, whereas comparative judgment elicits pairwise preferences between outputs. Although both methodologies are widely used, the choice between them is rarely justified. We release JudgmentBench, a benchmark of 30 real-world legal tasks, paired with 1,539 rubric scores and 1,530 pairwise preference judgments collected from practicing attorneys--including at major U.S. law firms--with substantial experience. The annotations constitute the first publicly available dataset in a high-expertise domain in which both supervision signals are elicited from the same experts on the same items. Using LLM-generated outputs at three constructed quality levels, we provide an initial empirical comparison: comparative judgments recover the intended quality ordering substantially better than rubrics (mean Spearman's rank correlation of 0.908 vs. 0.150, estimated difference = 0.758 [0.494, 1.021]) while requiring less than half the annotation time. The patterns hold for human annotators and LLM autograders. Beyond this initial comparison, the paired structure of the dataset supports a broader research agenda on how expert judgment should be elicited, aggregated, and used as supervision in domains without verifiable ground truth.
RIFT: A RubrIc Failure Mode Taxonomy and Automated Diagnostics
Apr 01, 2026Rubric-based evaluation is widely used in LLM benchmarks and training pipelines for open-ended, less verifiable tasks. While prior work has demonstrated the effectiveness of rubrics using downstream signals such as reinforcement learning outcomes, there remains no principled way to diagnose rubric quality issues from such aggregated or downstream signals alone. To address this gap, we introduce RIFT: RubrIc Failure mode Taxonomy, a taxonomy for systematically characterizing failure modes in rubric composition and design. RIFT consists of eight failure modes organized into three high-level categories: Reliability Failures, Content Validity Failures, and Consequential Validity Failures. RIFT is developed using grounded theory by iteratively annotating rubrics drawn from five diverse benchmarks spanning general instruction following, code generation, creative writing, and expert-level deep research, until no new failure modes are identified. We evaluate the consistency of the taxonomy by measuring agreement among independent human annotators, observing fair agreement overall (87% pairwise agreement and 0.64 average Cohen's kappa). Finally, to support scalable diagnosis, we propose automated rubric quality metrics and show that they align with human failure-mode annotations, achieving up to 0.86 F1.
Benchmarking Agents in Insurance Underwriting Environments
Jan 31, 2026As AI agents integrate into enterprise applications, their evaluation demands benchmarks that reflect the complexity of real-world operations. Instead, existing benchmarks overemphasize open-domains such as code, use narrow accuracy metrics, and lack authentic complexity. We present UNDERWRITE, an expert-first, multi-turn insurance underwriting benchmark designed in close collaboration with domain experts to capture real-world enterprise challenges. UNDERWRITE introduces critical realism factors often absent in current benchmarks: proprietary business knowledge, noisy tool interfaces, and imperfect simulated users requiring careful information gathering. Evaluating 13 frontier models, we uncover significant gaps between research lab performance and enterprise readiness: the most accurate models are not the most efficient, models hallucinate domain knowledge despite tool access, and pass^k results show a 20% drop in performance. The results from UNDERWRITE demonstrate that expert involvement in benchmark design is essential for realistic agent evaluation, common agentic frameworks exhibit brittleness that skews performance reporting, and hallucination detection in specialized domains demands compositional approaches. Our work provides insights for developing benchmarks that better align with enterprise deployment requirements.
A Mathematical Framework, a Taxonomy of Modeling Paradigms, and a Suite of Learning Techniques for Neural-Symbolic Systems
Jul 12, 2024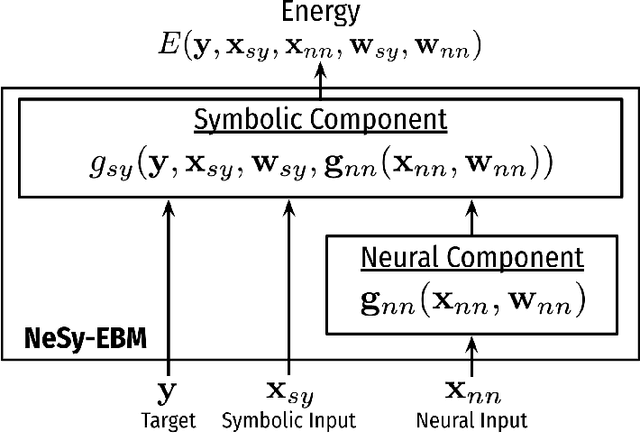

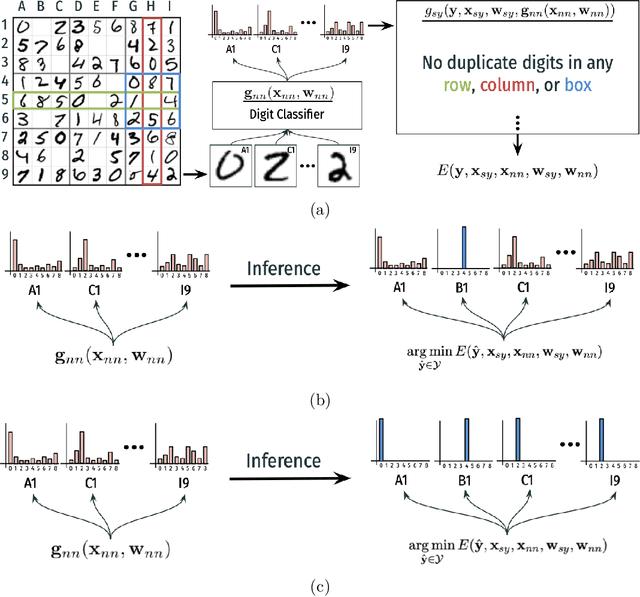
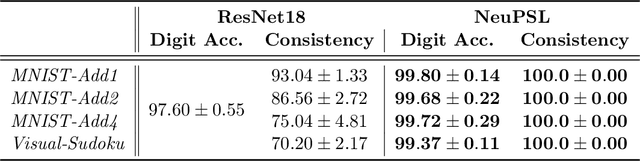
The field of Neural-Symbolic (NeSy) systems is growing rapidly. Proposed approaches show great promise in achieving symbiotic unions of neural and symbolic methods. However, each NeSy system differs in fundamental ways. There is a pressing need for a unifying theory to illuminate the commonalities and differences in approaches and enable further progress. In this paper, we introduce Neural-Symbolic Energy-Based Models (NeSy-EBMs), a unifying mathematical framework for discriminative and generative modeling with probabilistic and non-probabilistic NeSy approaches. We utilize NeSy-EBMs to develop a taxonomy of modeling paradigms focusing on a system's neural-symbolic interface and reasoning capabilities. Additionally, we introduce a suite of learning techniques for NeSy-EBMs. Importantly, NeSy-EBMs allow the derivation of general expressions for gradients of prominent learning losses, and we provide four learning approaches that leverage methods from multiple domains, including bilevel and stochastic policy optimization. Finally, we present Neural Probabilistic Soft Logic (NeuPSL), an open-source NeSy-EBM library designed for scalability and expressivity, facilitating real-world application of NeSy systems. Through extensive empirical analysis across multiple datasets, we demonstrate the practical advantages of NeSy-EBMs in various tasks, including image classification, graph node labeling, autonomous vehicle situation awareness, and question answering.
Convex and Bilevel Optimization for Neuro-Symbolic Inference and Learning
Jan 17, 2024We address a key challenge for neuro-symbolic (NeSy) systems by leveraging convex and bilevel optimization techniques to develop a general gradient-based framework for end-to-end neural and symbolic parameter learning. The applicability of our framework is demonstrated with NeuPSL, a state-of-the-art NeSy architecture. To achieve this, we propose a smooth primal and dual formulation of NeuPSL inference and show learning gradients are functions of the optimal dual variables. Additionally, we develop a dual block coordinate descent algorithm for the new formulation that naturally exploits warm-starts. This leads to over 100x learning runtime improvements over the current best NeuPSL inference method. Finally, we provide extensive empirical evaluations across $8$ datasets covering a range of tasks and demonstrate our learning framework achieves up to a 16% point prediction performance improvement over alternative learning methods.
Graph Coarsening via Convolution Matching for Scalable Graph Neural Network Training
Dec 24, 2023



Graph summarization as a preprocessing step is an effective and complementary technique for scalable graph neural network (GNN) training. In this work, we propose the Coarsening Via Convolution Matching (CONVMATCH) algorithm and a highly scalable variant, A-CONVMATCH, for creating summarized graphs that preserve the output of graph convolution. We evaluate CONVMATCH on six real-world link prediction and node classification graph datasets, and show it is efficient and preserves prediction performance while significantly reducing the graph size. Notably, CONVMATCH achieves up to 95% of the prediction performance of GNNs on node classification while trained on graphs summarized down to 1% the size of the original graph. Furthermore, on link prediction tasks, CONVMATCH consistently outperforms all baselines, achieving up to a 2x improvement.
Simplifying Distributed Neural Network Training on Massive Graphs: Randomized Partitions Improve Model Aggregation
May 17, 2023



Distributed training of GNNs enables learning on massive graphs (e.g., social and e-commerce networks) that exceed the storage and computational capacity of a single machine. To reach performance comparable to centralized training, distributed frameworks focus on maximally recovering cross-instance node dependencies with either communication across instances or periodic fallback to centralized training, which create overhead and limit the framework scalability. In this work, we present a simplified framework for distributed GNN training that does not rely on the aforementioned costly operations, and has improved scalability, convergence speed and performance over the state-of-the-art approaches. Specifically, our framework (1) assembles independent trainers, each of which asynchronously learns a local model on locally-available parts of the training graph, and (2) only conducts periodic (time-based) model aggregation to synchronize the local models. Backed by our theoretical analysis, instead of maximizing the recovery of cross-instance node dependencies -- which has been considered the key behind closing the performance gap between model aggregation and centralized training -- , our framework leverages randomized assignment of nodes or super-nodes (i.e., collections of original nodes) to partition the training graph such that it improves data uniformity and minimizes the discrepancy of gradient and loss function across instances. In our experiments on social and e-commerce networks with up to 1.3 billion edges, our proposed RandomTMA and SuperTMA approaches -- despite using less training data -- achieve state-of-the-art performance and 2.31x speedup compared to the fastest baseline, and show better robustness to trainer failures.
Emotion Recognition in Conversation using Probabilistic Soft Logic
Jul 14, 2022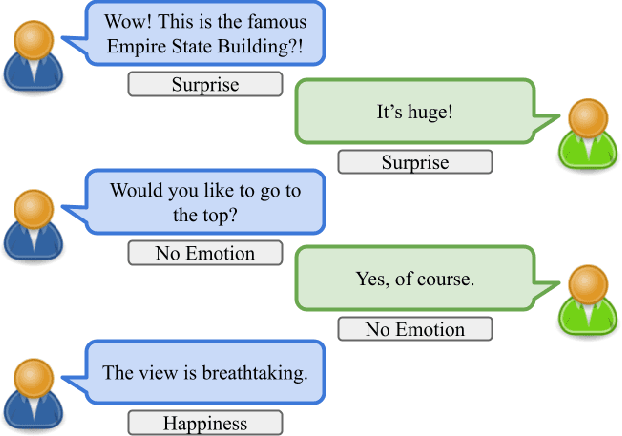

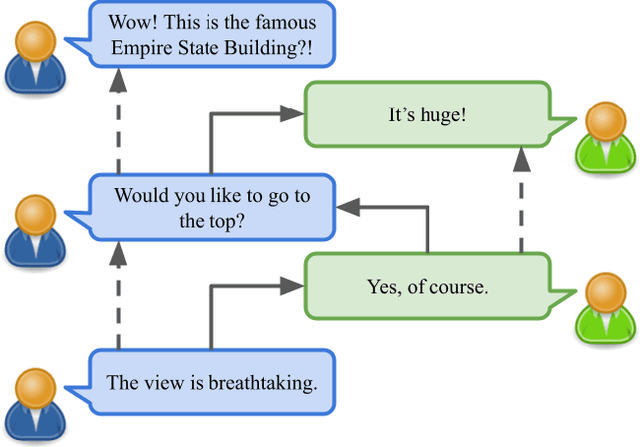
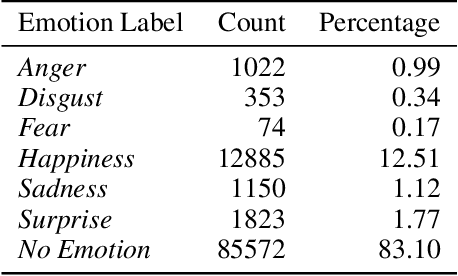
Creating agents that can both appropriately respond to conversations and understand complex human linguistic tendencies and social cues has been a long standing challenge in the NLP community. A recent pillar of research revolves around emotion recognition in conversation (ERC); a sub-field of emotion recognition that focuses on conversations or dialogues that contain two or more utterances. In this work, we explore an approach to ERC that exploits the use of neural embeddings along with complex structures in dialogues. We implement our approach in a framework called Probabilistic Soft Logic (PSL), a declarative templating language that uses first-order like logical rules, that when combined with data, define a particular class of graphical model. Additionally, PSL provides functionality for the incorporation of results from neural models into PSL models. This allows our model to take advantage of advanced neural methods, such as sentence embeddings, and logical reasoning over the structure of a dialogue. We compare our method with state-of-the-art purely neural ERC systems, and see almost a 20% improvement. With these results, we provide an extensive qualitative and quantitative analysis over the DailyDialog conversation dataset.
NeuPSL: Neural Probabilistic Soft Logic
May 27, 2022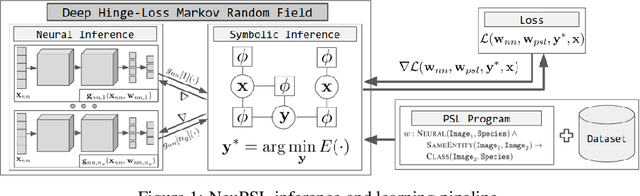

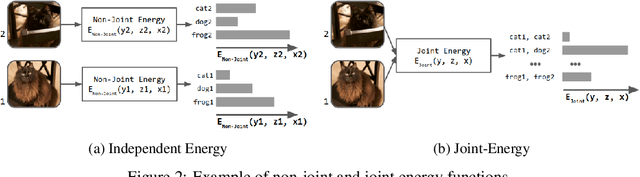
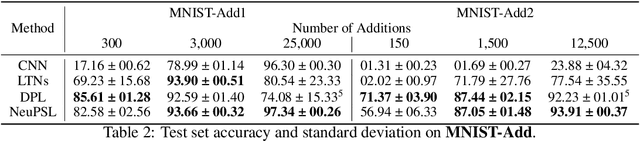
We present Neural Probabilistic Soft Logic (NeuPSL), a novel neuro-symbolic (NeSy) framework that unites state-of-the-art symbolic reasoning with the low-level perception of deep neural networks. To explicitly model the boundary between neural and symbolic representations, we introduce NeSy Energy-Based Models, a general family of energy-based models that combine neural and symbolic reasoning. Using this framework, we show how to seamlessly integrate neural and symbolic parameter learning and inference. We perform an extensive empirical evaluation and show that NeuPSL outperforms existing methods on joint inference and has significantly lower variance in almost all settings.
HyperFair: A Soft Approach to Integrating Fairness Criteria
Sep 05, 2020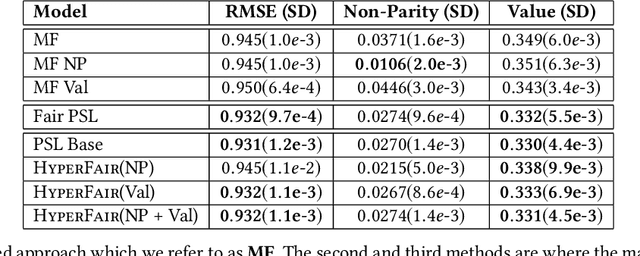

Recommender systems are being employed across an increasingly diverse set of domains that can potentially make a significant social and individual impact. For this reason, considering fairness is a critical step in the design and evaluation of such systems. In this paper, we introduce HyperFair, a general framework for enforcing soft fairness constraints in a hybrid recommender system. HyperFair models integrate variations of fairness metrics as a regularization of a joint inference objective function. We implement our approach using probabilistic soft logic and show that it is particularly well-suited for this task as it is expressive and structural constraints can be added to the system in a concise and interpretable manner. We propose two ways to employ the methods we introduce: first as an extension of a probabilistic soft logic recommender system template; second as a fair retrofitting technique that can be used to improve the fairness of predictions from a black-box model. We empirically validate our approach by implementing multiple HyperFair hybrid recommenders and compare them to a state-of-the-art fair recommender. We also run experiments showing the effectiveness of our methods for the task of retrofitting a black-box model and the trade-off between the amount of fairness enforced and the prediction performance.