 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnleashing the Power of LLMs as Multi-Modal Encoders for Text and Graph-Structured Data
Oct 15, 2024



Graph-structured information offers rich contextual information that can enhance language models by providing structured relationships and hierarchies, leading to more expressive embeddings for various applications such as retrieval, question answering, and classification. However, existing methods for integrating graph and text embeddings, often based on Multi-layer Perceptrons (MLPs) or shallow transformers, are limited in their ability to fully exploit the heterogeneous nature of these modalities. To overcome this, we propose Janus, a simple yet effective framework that leverages Large Language Models (LLMs) to jointly encode text and graph data. Specifically, Janus employs an MLP adapter to project graph embeddings into the same space as text embeddings, allowing the LLM to process both modalities jointly. Unlike prior work, we also introduce contrastive learning to align the graph and text spaces more effectively, thereby improving the quality of learned joint embeddings. Empirical results across six datasets spanning three tasks, knowledge graph-contextualized question answering, graph-text pair classification, and retrieval, demonstrate that Janus consistently outperforms existing baselines, achieving significant improvements across multiple datasets, with gains of up to 11.4% in QA tasks. These results highlight Janus's effectiveness in integrating graph and text data. Ablation studies further validate the effectiveness of our method.
Covering a Graph with Dense Subgraph Families, via Triangle-Rich Sets
Jul 23, 2024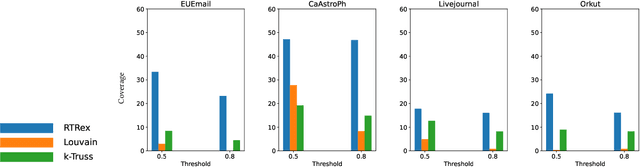

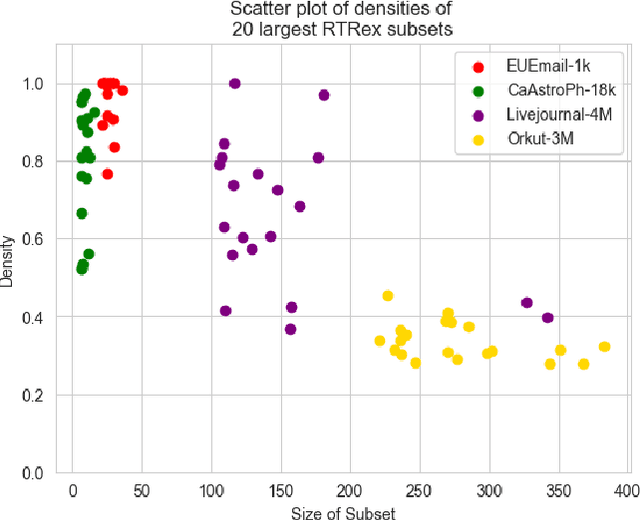
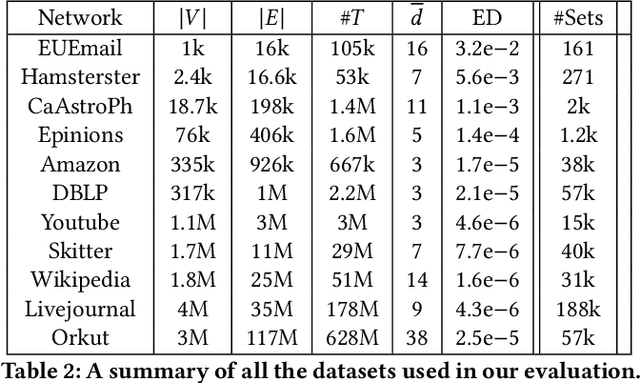
Graphs are a fundamental data structure used to represent relationships in domains as diverse as the social sciences, bioinformatics, cybersecurity, the Internet, and more. One of the central observations in network science is that real-world graphs are globally sparse, yet contains numerous "pockets" of high edge density. A fundamental task in graph mining is to discover these dense subgraphs. Most common formulations of the problem involve finding a single (or a few) "optimally" dense subsets. But in most real applications, one does not care for the optimality. Instead, we want to find a large collection of dense subsets that covers a significant fraction of the input graph. We give a mathematical formulation of this problem, using a new definition of regularly triangle-rich (RTR) families. These families capture the notion of dense subgraphs that contain many triangles and have degrees comparable to the subgraph size. We design a provable algorithm, RTRExtractor, that can discover RTR families that approximately cover any RTR set. The algorithm is efficient and is inspired by recent results that use triangle counts for community testing and clustering. We show that RTRExtractor has excellent behavior on a large variety of real-world datasets. It is able to process graphs with hundreds of millions of edges within minutes. Across many datasets, RTRExtractor achieves high coverage using high edge density datasets. For example, the output covers a quarter of the vertices with subgraphs of edge density more than (say) $0.5$, for datasets with 10M+ edges. We show an example of how the output of RTRExtractor correlates with meaningful sets of similar vertices in a citation network, demonstrating the utility of RTRExtractor for unsupervised graph discovery tasks.
All Against Some: Efficient Integration of Large Language Models for Message Passing in Graph Neural Networks
Jul 20, 2024



Graph Neural Networks (GNNs) have attracted immense attention in the past decade due to their numerous real-world applications built around graph-structured data. On the other hand, Large Language Models (LLMs) with extensive pretrained knowledge and powerful semantic comprehension abilities have recently shown a remarkable ability to benefit applications using vision and text data. In this paper, we investigate how LLMs can be leveraged in a computationally efficient fashion to benefit rich graph-structured data, a modality relatively unexplored in LLM literature. Prior works in this area exploit LLMs to augment every node features in an ad-hoc fashion (not scalable for large graphs), use natural language to describe the complex structural information of graphs, or perform computationally expensive finetuning of LLMs in conjunction with GNNs. We propose E-LLaGNN (Efficient LLMs augmented GNNs), a framework with an on-demand LLM service that enriches message passing procedure of graph learning by enhancing a limited fraction of nodes from the graph. More specifically, E-LLaGNN relies on sampling high-quality neighborhoods using LLMs, followed by on-demand neighborhood feature enhancement using diverse prompts from our prompt catalog, and finally information aggregation using message passing from conventional GNN architectures. We explore several heuristics-based active node selection strategies to limit the computational and memory footprint of LLMs when handling millions of nodes. Through extensive experiments & ablation on popular graph benchmarks of varying scales (Cora, PubMed, ArXiv, & Products), we illustrate the effectiveness of our E-LLaGNN framework and reveal many interesting capabilities such as improved gradient flow in deep GNNs, LLM-free inference ability etc.
AvaTaR: Optimizing LLM Agents for Tool-Assisted Knowledge Retrieval
Jun 18, 2024



Large language model (LLM) agents have demonstrated impressive capability in utilizing external tools and knowledge to boost accuracy and reduce hallucinations. However, developing the prompting techniques that make LLM agents able to effectively use external tools and knowledge is a heuristic and laborious task. Here, we introduce AvaTaR, a novel and automatic framework that optimizes an LLM agent to effectively use the provided tools and improve its performance on a given task/domain. During optimization, we design a comparator module to iteratively provide insightful and holistic prompts to the LLM agent via reasoning between positive and negative examples sampled from training data. We demonstrate AvaTaR on four complex multimodal retrieval datasets featuring textual, visual, and relational information. We find AvaTaR consistently outperforms state-of-the-art approaches across all four challenging tasks and exhibits strong generalization ability when applied to novel cases, achieving an average relative improvement of 14% on the Hit@1 metric. Code and dataset are available at https://github.com/zou-group/avatar.
STaRK: Benchmarking LLM Retrieval on Textual and Relational Knowledge Bases
Apr 19, 2024



Answering real-world user queries, such as product search, often requires accurate retrieval of information from semi-structured knowledge bases or databases that involve blend of unstructured (e.g., textual descriptions of products) and structured (e.g., entity relations of products) information. However, previous works have mostly studied textual and relational retrieval tasks as separate topics. To address the gap, we develop STARK, a large-scale Semi-structure retrieval benchmark on Textual and Relational Knowledge Bases. We design a novel pipeline to synthesize natural and realistic user queries that integrate diverse relational information and complex textual properties, as well as their ground-truth answers. Moreover, we rigorously conduct human evaluation to validate the quality of our benchmark, which covers a variety of practical applications, including product recommendations, academic paper searches, and precision medicine inquiries. Our benchmark serves as a comprehensive testbed for evaluating the performance of retrieval systems, with an emphasis on retrieval approaches driven by large language models (LLMs). Our experiments suggest that the STARK datasets present significant challenges to the current retrieval and LLM systems, indicating the demand for building more capable retrieval systems that can handle both textual and relational aspects.
An Interpretable Ensemble of Graph and Language Models for Improving Search Relevance in E-Commerce
Mar 01, 2024



The problem of search relevance in the E-commerce domain is a challenging one since it involves understanding the intent of a user's short nuanced query and matching it with the appropriate products in the catalog. This problem has traditionally been addressed using language models (LMs) and graph neural networks (GNNs) to capture semantic and inter-product behavior signals, respectively. However, the rapid development of new architectures has created a gap between research and the practical adoption of these techniques. Evaluating the generalizability of these models for deployment requires extensive experimentation on complex, real-world datasets, which can be non-trivial and expensive. Furthermore, such models often operate on latent space representations that are incomprehensible to humans, making it difficult to evaluate and compare the effectiveness of different models. This lack of interpretability hinders the development and adoption of new techniques in the field. To bridge this gap, we propose Plug and Play Graph LAnguage Model (PP-GLAM), an explainable ensemble of plug and play models. Our approach uses a modular framework with uniform data processing pipelines. It employs additive explanation metrics to independently decide whether to include (i) language model candidates, (ii) GNN model candidates, and (iii) inter-product behavioral signals. For the task of search relevance, we show that PP-GLAM outperforms several state-of-the-art baselines as well as a proprietary model on real-world multilingual, multi-regional e-commerce datasets. To promote better model comprehensibility and adoption, we also provide an analysis of the explainability and computational complexity of our model. We also provide the public codebase and provide a deployment strategy for practical implementation.
Graph Coarsening via Convolution Matching for Scalable Graph Neural Network Training
Dec 24, 2023



Graph summarization as a preprocessing step is an effective and complementary technique for scalable graph neural network (GNN) training. In this work, we propose the Coarsening Via Convolution Matching (CONVMATCH) algorithm and a highly scalable variant, A-CONVMATCH, for creating summarized graphs that preserve the output of graph convolution. We evaluate CONVMATCH on six real-world link prediction and node classification graph datasets, and show it is efficient and preserves prediction performance while significantly reducing the graph size. Notably, CONVMATCH achieves up to 95% of the prediction performance of GNNs on node classification while trained on graphs summarized down to 1% the size of the original graph. Furthermore, on link prediction tasks, CONVMATCH consistently outperforms all baselines, achieving up to a 2x improvement.
ForeSeer: Product Aspect Forecasting Using Temporal Graph Embedding
Oct 07, 2023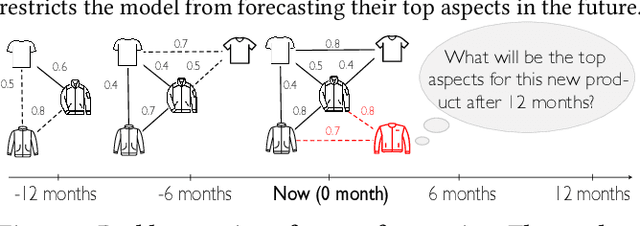
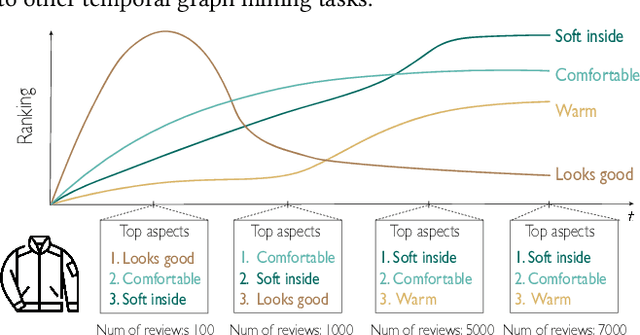
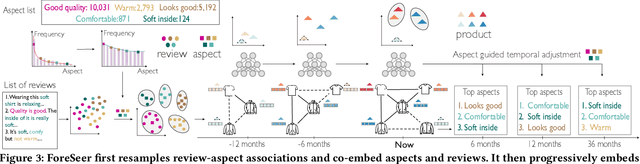
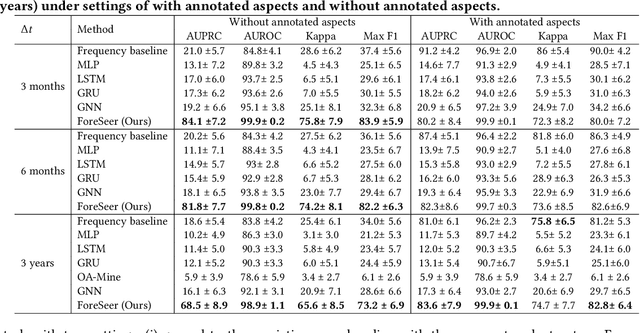
Developing text mining approaches to mine aspects from customer reviews has been well-studied due to its importance in understanding customer needs and product attributes. In contrast, it remains unclear how to predict the future emerging aspects of a new product that currently has little review information. This task, which we named product aspect forecasting, is critical for recommending new products, but also challenging because of the missing reviews. Here, we propose ForeSeer, a novel textual mining and product embedding approach progressively trained on temporal product graphs for this novel product aspect forecasting task. ForeSeer transfers reviews from similar products on a large product graph and exploits these reviews to predict aspects that might emerge in future reviews. A key novelty of our method is to jointly provide review, product, and aspect embeddings that are both time-sensitive and less affected by extremely imbalanced aspect frequencies. We evaluated ForeSeer on a real-world product review system containing 11,536,382 reviews and 11,000 products over 3 years. We observe that ForeSeer substantially outperformed existing approaches with at least 49.1\% AUPRC improvement under the real setting where aspect associations are not given. ForeSeer further improves future link prediction on the product graph and the review aspect association prediction. Collectively, Foreseer offers a novel framework for review forecasting by effectively integrating review text, product network, and temporal information, opening up new avenues for online shopping recommendation and e-commerce applications.
Communication-Free Distributed GNN Training with Vertex Cut
Aug 06, 2023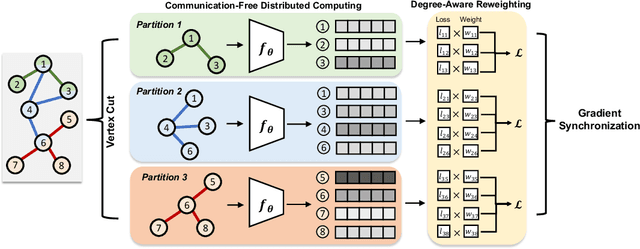
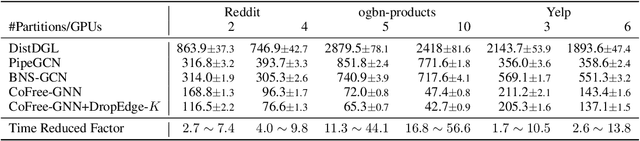
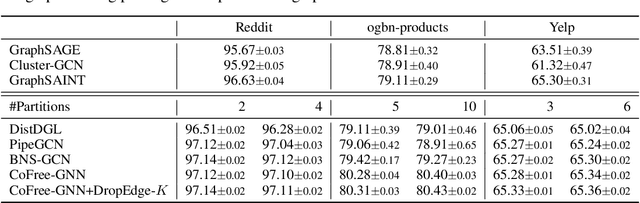

Training Graph Neural Networks (GNNs) on real-world graphs consisting of billions of nodes and edges is quite challenging, primarily due to the substantial memory needed to store the graph and its intermediate node and edge features, and there is a pressing need to speed up the training process. A common approach to achieve speed up is to divide the graph into many smaller subgraphs, which are then distributed across multiple GPUs in one or more machines and processed in parallel. However, existing distributed methods require frequent and substantial cross-GPU communication, leading to significant time overhead and progressively diminishing scalability. Here, we introduce CoFree-GNN, a novel distributed GNN training framework that significantly speeds up the training process by implementing communication-free training. The framework utilizes a Vertex Cut partitioning, i.e., rather than partitioning the graph by cutting the edges between partitions, the Vertex Cut partitions the edges and duplicates the node information to preserve the graph structure. Furthermore, the framework maintains high model accuracy by incorporating a reweighting mechanism to handle a distorted graph distribution that arises from the duplicated nodes. We also propose a modified DropEdge technique to further speed up the training process. Using an extensive set of experiments on real-world networks, we demonstrate that CoFree-GNN speeds up the GNN training process by up to 10 times over the existing state-of-the-art GNN training approaches.
Amazon-M2: A Multilingual Multi-locale Shopping Session Dataset for Recommendation and Text Generation
Jul 19, 2023
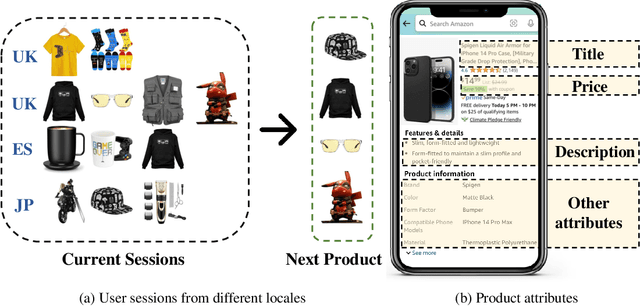
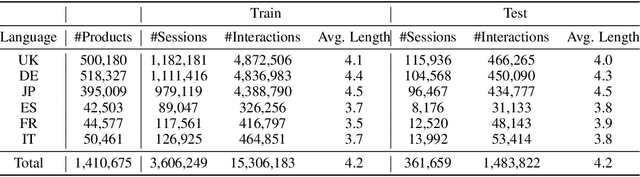
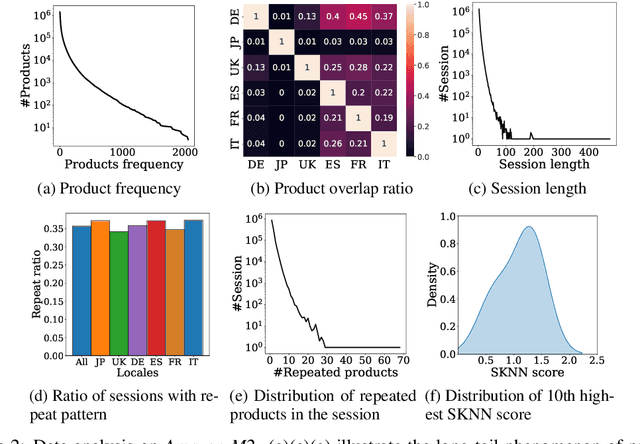
Modeling customer shopping intentions is a crucial task for e-commerce, as it directly impacts user experience and engagement. Thus, accurately understanding customer preferences is essential for providing personalized recommendations. Session-based recommendation, which utilizes customer session data to predict their next interaction, has become increasingly popular. However, existing session datasets have limitations in terms of item attributes, user diversity, and dataset scale. As a result, they cannot comprehensively capture the spectrum of user behaviors and preferences. To bridge this gap, we present the Amazon Multilingual Multi-locale Shopping Session Dataset, namely Amazon-M2. It is the first multilingual dataset consisting of millions of user sessions from six different locales, where the major languages of products are English, German, Japanese, French, Italian, and Spanish. Remarkably, the dataset can help us enhance personalization and understanding of user preferences, which can benefit various existing tasks as well as enable new tasks. To test the potential of the dataset, we introduce three tasks in this work: (1) next-product recommendation, (2) next-product recommendation with domain shifts, and (3) next-product title generation. With the above tasks, we benchmark a range of algorithms on our proposed dataset, drawing new insights for further research and practice. In addition, based on the proposed dataset and tasks, we hosted a competition in the KDD CUP 2023 and have attracted thousands of users and submissions. The winning solutions and the associated workshop can be accessed at our website https://kddcup23.github.io/.