 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning LLM Preference over Intra-Dialogue Pairs: A Framework for Utterance-level Understandings
Mar 07, 2025

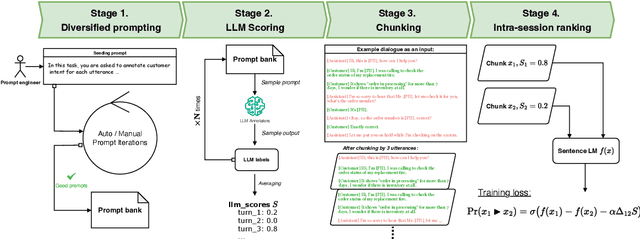

Large language models (LLMs) have demonstrated remarkable capabilities in handling complex dialogue tasks without requiring use case-specific fine-tuning. However, analyzing live dialogues in real-time necessitates low-latency processing systems, making it impractical to deploy models with billions of parameters due to latency constraints. As a result, practitioners often prefer smaller models with millions of parameters, trained on high-quality, human-annotated datasets. Yet, curating such datasets is both time-consuming and costly. Consequently, there is a growing need to combine the scalability of LLM-generated labels with the precision of human annotations, enabling fine-tuned smaller models to achieve both higher speed and accuracy comparable to larger models. In this paper, we introduce a simple yet effective framework to address this challenge. Our approach is specifically designed for per-utterance classification problems, which encompass tasks such as intent detection, dialogue state tracking, and more. To mitigate the impact of labeling errors from LLMs -- the primary source of inaccuracies in student models -- we propose a noise-reduced preference learning loss. Experimental results demonstrate that our method significantly improves accuracy across utterance-level dialogue tasks, including sentiment detection (over $2\%$), dialogue act classification (over $1.5\%$), etc.
Diffusion Models for Multi-Task Generative Modeling
Jul 24, 2024
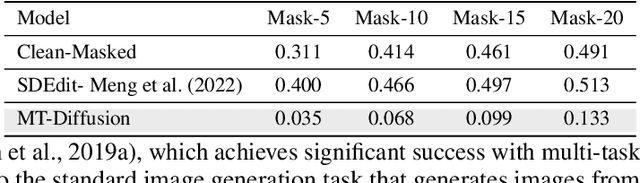
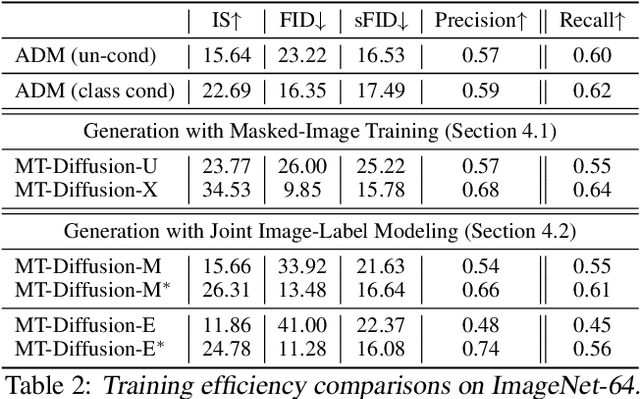
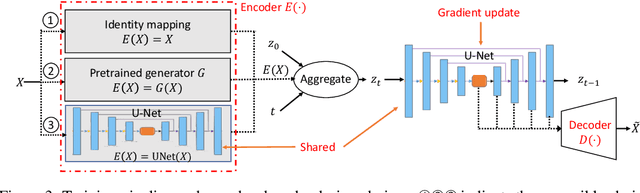
Diffusion-based generative modeling has been achieving state-of-the-art results on various generation tasks. Most diffusion models, however, are limited to a single-generation modeling. Can we generalize diffusion models with the ability of multi-modal generative training for more generalizable modeling? In this paper, we propose a principled way to define a diffusion model by constructing a unified multi-modal diffusion model in a common diffusion space. We define the forward diffusion process to be driven by an information aggregation from multiple types of task-data, e.g., images for a generation task and labels for a classification task. In the reverse process, we enforce information sharing by parameterizing a shared backbone denoising network with additional modality-specific decoder heads. Such a structure can simultaneously learn to generate different types of multi-modal data with a multi-task loss, which is derived from a new multi-modal variational lower bound that generalizes the standard diffusion model. We propose several multimodal generation settings to verify our framework, including image transition, masked-image training, joint image-label and joint image-representation generative modeling. Extensive experimental results on ImageNet indicate the effectiveness of our framework for various multi-modal generative modeling, which we believe is an important research direction worthy of more future explorations.
GraphStorm: all-in-one graph machine learning framework for industry applications
Jun 10, 2024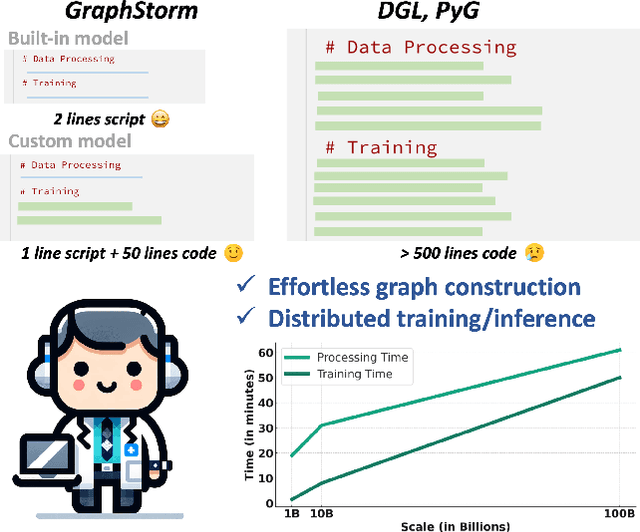

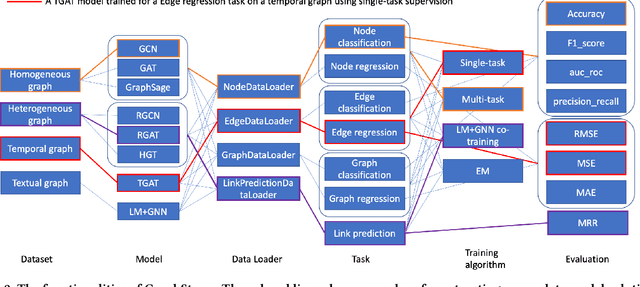

Graph machine learning (GML) is effective in many business applications. However, making GML easy to use and applicable to industry applications with massive datasets remain challenging. We developed GraphStorm, which provides an end-to-end solution for scalable graph construction, graph model training and inference. GraphStorm has the following desirable properties: (a) Easy to use: it can perform graph construction and model training and inference with just a single command; (b) Expert-friendly: GraphStorm contains many advanced GML modeling techniques to handle complex graph data and improve model performance; (c) Scalable: every component in GraphStorm can operate on graphs with billions of nodes and can scale model training and inference to different hardware without changing any code. GraphStorm has been used and deployed for over a dozen billion-scale industry applications after its release in May 2023. It is open-sourced in Github: https://github.com/awslabs/graphstorm.
VidLA: Video-Language Alignment at Scale
Mar 21, 2024In this paper, we propose VidLA, an approach for video-language alignment at scale. There are two major limitations of previous video-language alignment approaches. First, they do not capture both short-range and long-range temporal dependencies and typically employ complex hierarchical deep network architectures that are hard to integrate with existing pretrained image-text foundation models. To effectively address this limitation, we instead keep the network architecture simple and use a set of data tokens that operate at different temporal resolutions in a hierarchical manner, accounting for the temporally hierarchical nature of videos. By employing a simple two-tower architecture, we are able to initialize our video-language model with pretrained image-text foundation models, thereby boosting the final performance. Second, existing video-language alignment works struggle due to the lack of semantically aligned large-scale training data. To overcome it, we leverage recent LLMs to curate the largest video-language dataset to date with better visual grounding. Furthermore, unlike existing video-text datasets which only contain short clips, our dataset is enriched with video clips of varying durations to aid our temporally hierarchical data tokens in extracting better representations at varying temporal scales. Overall, empirical results show that our proposed approach surpasses state-of-the-art methods on multiple retrieval benchmarks, especially on longer videos, and performs competitively on classification benchmarks.
Robust Multi-Task Learning with Excess Risks
Feb 14, 2024



Multi-task learning (MTL) considers learning a joint model for multiple tasks by optimizing a convex combination of all task losses. To solve the optimization problem, existing methods use an adaptive weight updating scheme, where task weights are dynamically adjusted based on their respective losses to prioritize difficult tasks. However, these algorithms face a great challenge whenever label noise is present, in which case excessive weights tend to be assigned to noisy tasks that have relatively large Bayes optimal errors, thereby overshadowing other tasks and causing performance to drop across the board. To overcome this limitation, we propose Multi-Task Learning with Excess Risks (ExcessMTL), an excess risk-based task balancing method that updates the task weights by their distances to convergence instead. Intuitively, ExcessMTL assigns higher weights to worse-trained tasks that are further from convergence. To estimate the excess risks, we develop an efficient and accurate method with Taylor approximation. Theoretically, we show that our proposed algorithm achieves convergence guarantees and Pareto stationarity. Empirically, we evaluate our algorithm on various MTL benchmarks and demonstrate its superior performance over existing methods in the presence of label noise.
Better Representations via Adversarial Training in Pre-Training: A Theoretical Perspective
Jan 26, 2024



Pre-training is known to generate universal representations for downstream tasks in large-scale deep learning such as large language models. Existing literature, e.g., \cite{kim2020adversarial}, empirically observe that the downstream tasks can inherit the adversarial robustness of the pre-trained model. We provide theoretical justifications for this robustness inheritance phenomenon. Our theoretical results reveal that feature purification plays an important role in connecting the adversarial robustness of the pre-trained model and the downstream tasks in two-layer neural networks. Specifically, we show that (i) with adversarial training, each hidden node tends to pick only one (or a few) feature; (ii) without adversarial training, the hidden nodes can be vulnerable to attacks. This observation is valid for both supervised pre-training and contrastive learning. With purified nodes, it turns out that clean training is enough to achieve adversarial robustness in downstream tasks.
ForeSeer: Product Aspect Forecasting Using Temporal Graph Embedding
Oct 07, 2023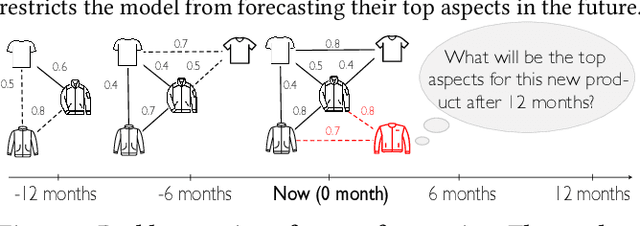
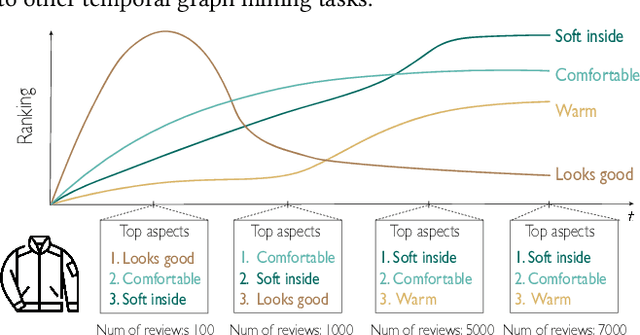
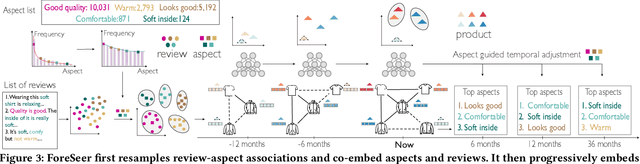
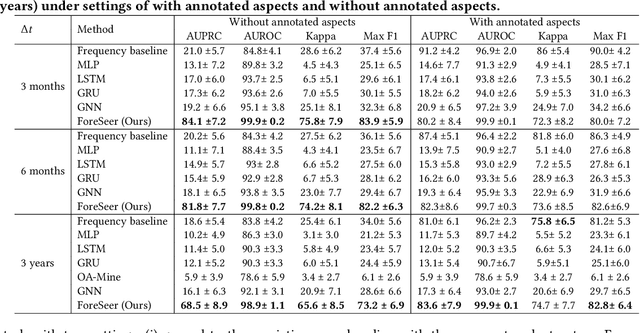
Developing text mining approaches to mine aspects from customer reviews has been well-studied due to its importance in understanding customer needs and product attributes. In contrast, it remains unclear how to predict the future emerging aspects of a new product that currently has little review information. This task, which we named product aspect forecasting, is critical for recommending new products, but also challenging because of the missing reviews. Here, we propose ForeSeer, a novel textual mining and product embedding approach progressively trained on temporal product graphs for this novel product aspect forecasting task. ForeSeer transfers reviews from similar products on a large product graph and exploits these reviews to predict aspects that might emerge in future reviews. A key novelty of our method is to jointly provide review, product, and aspect embeddings that are both time-sensitive and less affected by extremely imbalanced aspect frequencies. We evaluated ForeSeer on a real-world product review system containing 11,536,382 reviews and 11,000 products over 3 years. We observe that ForeSeer substantially outperformed existing approaches with at least 49.1\% AUPRC improvement under the real setting where aspect associations are not given. ForeSeer further improves future link prediction on the product graph and the review aspect association prediction. Collectively, Foreseer offers a novel framework for review forecasting by effectively integrating review text, product network, and temporal information, opening up new avenues for online shopping recommendation and e-commerce applications.
Graph-Aware Language Model Pre-Training on a Large Graph Corpus Can Help Multiple Graph Applications
Jun 05, 2023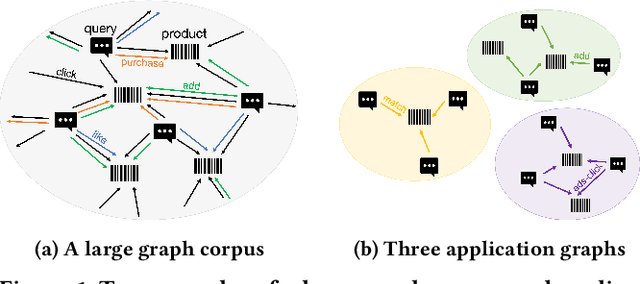
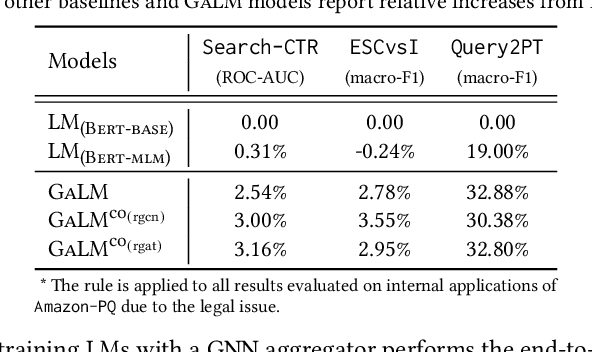
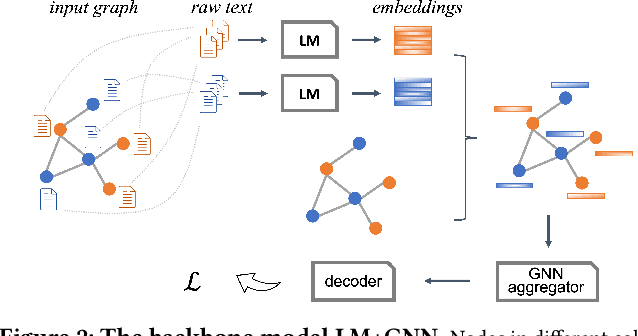
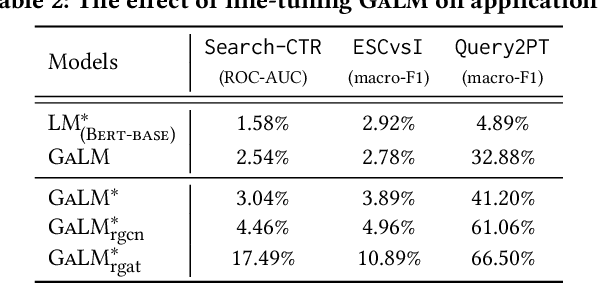
Model pre-training on large text corpora has been demonstrated effective for various downstream applications in the NLP domain. In the graph mining domain, a similar analogy can be drawn for pre-training graph models on large graphs in the hope of benefiting downstream graph applications, which has also been explored by several recent studies. However, no existing study has ever investigated the pre-training of text plus graph models on large heterogeneous graphs with abundant textual information (a.k.a. large graph corpora) and then fine-tuning the model on different related downstream applications with different graph schemas. To address this problem, we propose a framework of graph-aware language model pre-training (GALM) on a large graph corpus, which incorporates large language models and graph neural networks, and a variety of fine-tuning methods on downstream applications. We conduct extensive experiments on Amazon's real internal datasets and large public datasets. Comprehensive empirical results and in-depth analysis demonstrate the effectiveness of our proposed methods along with lessons learned.
Understanding and Constructing Latent Modality Structures in Multi-modal Representation Learning
Mar 10, 2023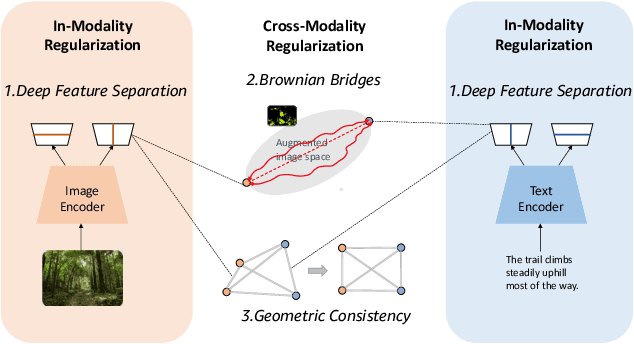
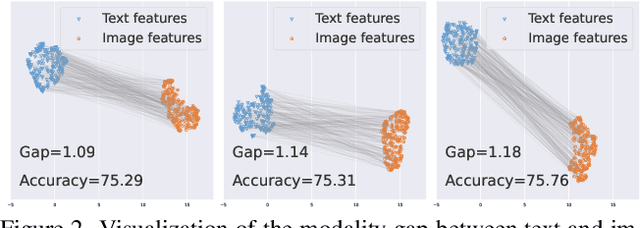
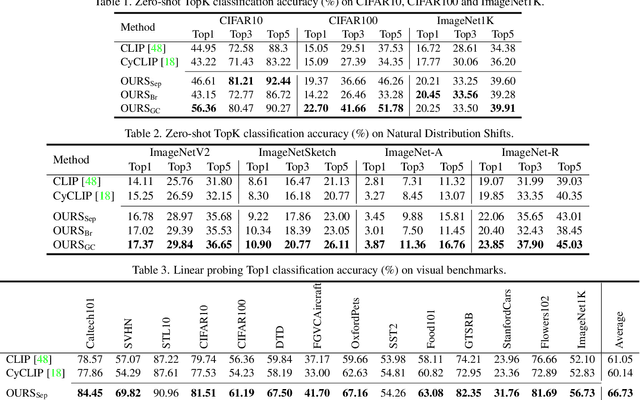
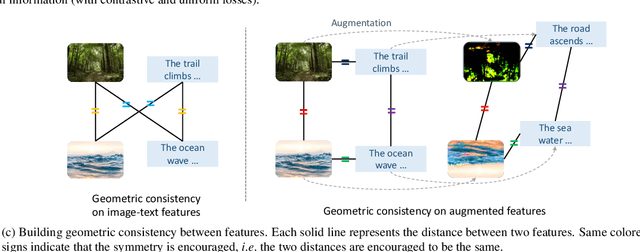
Contrastive loss has been increasingly used in learning representations from multiple modalities. In the limit, the nature of the contrastive loss encourages modalities to exactly match each other in the latent space. Yet it remains an open question how the modality alignment affects the downstream task performance. In this paper, based on an information-theoretic argument, we first prove that exact modality alignment is sub-optimal in general for downstream prediction tasks. Hence we advocate that the key of better performance lies in meaningful latent modality structures instead of perfect modality alignment. To this end, we propose three general approaches to construct latent modality structures. Specifically, we design 1) a deep feature separation loss for intra-modality regularization; 2) a Brownian-bridge loss for inter-modality regularization; and 3) a geometric consistency loss for both intra- and inter-modality regularization. Extensive experiments are conducted on two popular multi-modal representation learning frameworks: the CLIP-based two-tower model and the ALBEF-based fusion model. We test our model on a variety of tasks including zero/few-shot image classification, image-text retrieval, visual question answering, visual reasoning, and visual entailment. Our method achieves consistent improvements over existing methods, demonstrating the effectiveness and generalizability of our proposed approach on latent modality structure regularization.
Efficient and effective training of language and graph neural network models
Jun 22, 2022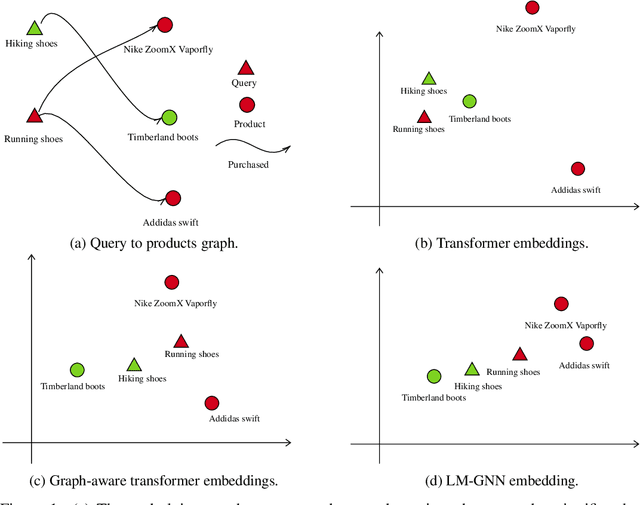
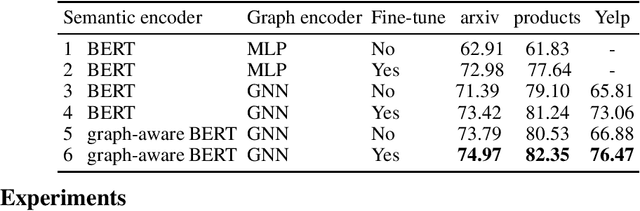
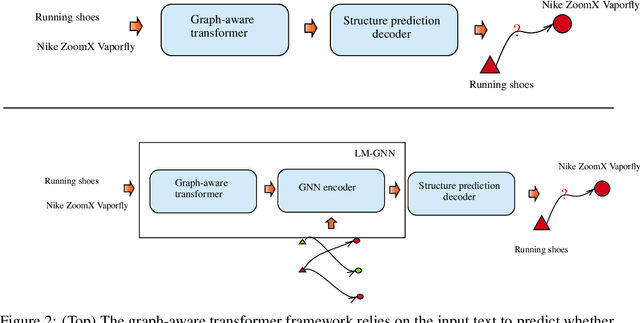
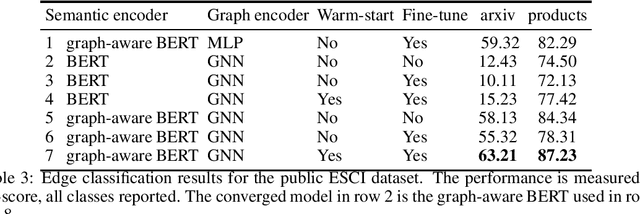
Can we combine heterogenous graph structure with text to learn high-quality semantic and behavioural representations? Graph neural networks (GNN)s encode numerical node attributes and graph structure to achieve impressive performance in a variety of supervised learning tasks. Current GNN approaches are challenged by textual features, which typically need to be encoded to a numerical vector before provided to the GNN that may incur some information loss. In this paper, we put forth an efficient and effective framework termed language model GNN (LM-GNN) to jointly train large-scale language models and graph neural networks. The effectiveness in our framework is achieved by applying stage-wise fine-tuning of the BERT model first with heterogenous graph information and then with a GNN model. Several system and design optimizations are proposed to enable scalable and efficient training. LM-GNN accommodates node and edge classification as well as link prediction tasks. We evaluate the LM-GNN framework in different datasets performance and showcase the effectiveness of the proposed approach. LM-GNN provides competitive results in an Amazon query-purchase-product application.