 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaliMory: Orchestrating Cognitive Memory for Conversational Agents
Jun 02, 2026Conversational agents that serve as lifelong companions must maintain persistent memory across all interactions. However, simply expanding context windows with raw retrieval degrades reasoning quality, while training memory agents via standard reinforcement learning creates a severe credit assignment bottleneck in a multi-stage pipeline. To solve this, we introduce SALIMORY, a framework that trains a single language model to manage a cognitively-structured memory-spanning user facts, preferences, and working memory. By introducing a hierarchical stage-wise process reward and reward-decomposed contrastive refinement, SALIMORY provides isolated supervision for distinct memory operations (selective filtering, consolidation, and cue-driven recall) end-to-end. SALIMORY cuts memory-attributed failures by one-third, outperforms the state-of-the-art by over 10% in end-to-end accuracy, and more than doubles the Good Personalization rate.
Synthetic Users, Real Differences: an Evaluation Framework for User Simulation in Multi-Turn Conversations
May 04, 2026There is growing interest in exploring user simulation as an alternative to gathering and scoring real user-chatbot interactions for AI chatbot evaluation. For this purpose, it is important to ensure the realism of the simulation, i.e., the extent to which simulated dialogues reflect real dialogues users have with chatbots. Most existing methods evaluating simulation realism produce coarse quality signal and remain solely at the level of individual dialogues. To support more rigorous evaluation in this area, we propose realsim, an evaluation framework that enables practitioners to take a distributional view of real vs. simulated dialogues along 8 dimensions, covering attributes related to the communicative functions of the interaction, user states, and the surface form of user messages. We then instantiate the framework with a curated dataset of 1K multi-turn task-focused real user-chatbot dialogues that cover 16 domains of chatbot applications. Overall, we find that simulated users tend to struggle at capturing communication frictions that real users introduce to interactions, which could make evaluations based on such simulations overly optimistic. We also observe variability in performance across different domains, which may indicate a need for domain-specific user simulators.
Ask a Strong LLM Judge when Your Reward Model is Uncertain
Oct 23, 2025Reward model (RM) plays a pivotal role in reinforcement learning with human feedback (RLHF) for aligning large language models (LLMs). However, classical RMs trained on human preferences are vulnerable to reward hacking and generalize poorly to out-of-distribution (OOD) inputs. By contrast, strong LLM judges equipped with reasoning capabilities demonstrate superior generalization, even without additional training, but incur significantly higher inference costs, limiting their applicability in online RLHF. In this work, we propose an uncertainty-based routing framework that efficiently complements a fast RM with a strong but costly LLM judge. Our approach formulates advantage estimation in policy gradient (PG) methods as pairwise preference classification, enabling principled uncertainty quantification to guide routing. Uncertain pairs are forwarded to the LLM judge, while confident ones are evaluated by the RM. Experiments on RM benchmarks demonstrate that our uncertainty-based routing strategy significantly outperforms random judge calling at the same cost, and downstream alignment results showcase its effectiveness in improving online RLHF.
Aligning Large Language Models with Implicit Preferences from User-Generated Content
Jun 04, 2025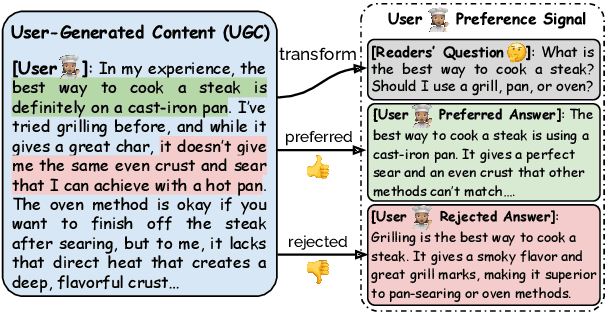
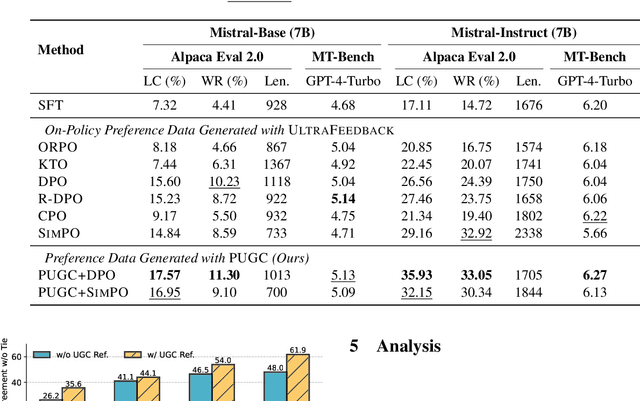
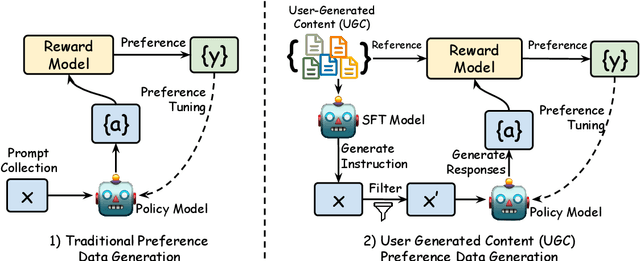

Learning from preference feedback is essential for aligning large language models (LLMs) with human values and improving the quality of generated responses. However, existing preference learning methods rely heavily on curated data from humans or advanced LLMs, which is costly and difficult to scale. In this work, we present PUGC, a novel framework that leverages implicit human Preferences in unlabeled User-Generated Content (UGC) to generate preference data. Although UGC is not explicitly created to guide LLMs in generating human-preferred responses, it often reflects valuable insights and implicit preferences from its creators that has the potential to address readers' questions. PUGC transforms UGC into user queries and generates responses from the policy model. The UGC is then leveraged as a reference text for response scoring, aligning the model with these implicit preferences. This approach improves the quality of preference data while enabling scalable, domain-specific alignment. Experimental results on Alpaca Eval 2 show that models trained with DPO and PUGC achieve a 9.37% performance improvement over traditional methods, setting a 35.93% state-of-the-art length-controlled win rate using Mistral-7B-Instruct. Further studies highlight gains in reward quality, domain-specific alignment effectiveness, robustness against UGC quality, and theory of mind capabilities. Our code and dataset are available at https://zhaoxuan.info/PUGC.github.io/
WebAgent-R1: Training Web Agents via End-to-End Multi-Turn Reinforcement Learning
May 22, 2025While reinforcement learning (RL) has demonstrated remarkable success in enhancing large language models (LLMs), it has primarily focused on single-turn tasks such as solving math problems. Training effective web agents for multi-turn interactions remains challenging due to the complexity of long-horizon decision-making across dynamic web interfaces. In this work, we present WebAgent-R1, a simple yet effective end-to-end multi-turn RL framework for training web agents. It learns directly from online interactions with web environments by asynchronously generating diverse trajectories, entirely guided by binary rewards depending on task success. Experiments on the WebArena-Lite benchmark demonstrate the effectiveness of WebAgent-R1, boosting the task success rate of Qwen-2.5-3B from 6.1% to 33.9% and Llama-3.1-8B from 8.5% to 44.8%, significantly outperforming existing state-of-the-art methods and strong proprietary models such as OpenAI o3. In-depth analyses reveal the effectiveness of the thinking-based prompting strategy and test-time scaling through increased interactions for web tasks. We further investigate different RL initialization policies by introducing two variants, namely WebAgent-R1-Zero and WebAgent-R1-CoT, which highlight the importance of the warm-up training stage (i.e., behavior cloning) and provide insights on incorporating long chain-of-thought (CoT) reasoning in web agents.
RealWebAssist: A Benchmark for Long-Horizon Web Assistance with Real-World Users
Apr 14, 2025To achieve successful assistance with long-horizon web-based tasks, AI agents must be able to sequentially follow real-world user instructions over a long period. Unlike existing web-based agent benchmarks, sequential instruction following in the real world poses significant challenges beyond performing a single, clearly defined task. For instance, real-world human instructions can be ambiguous, require different levels of AI assistance, and may evolve over time, reflecting changes in the user's mental state. To address this gap, we introduce RealWebAssist, a novel benchmark designed to evaluate sequential instruction-following in realistic scenarios involving long-horizon interactions with the web, visual GUI grounding, and understanding ambiguous real-world user instructions. RealWebAssist includes a dataset of sequential instructions collected from real-world human users. Each user instructs a web-based assistant to perform a series of tasks on multiple websites. A successful agent must reason about the true intent behind each instruction, keep track of the mental state of the user, understand user-specific routines, and ground the intended tasks to actions on the correct GUI elements. Our experimental results show that state-of-the-art models struggle to understand and ground user instructions, posing critical challenges in following real-world user instructions for long-horizon web assistance.
Evolutionary Contrastive Distillation for Language Model Alignment
Oct 10, 2024
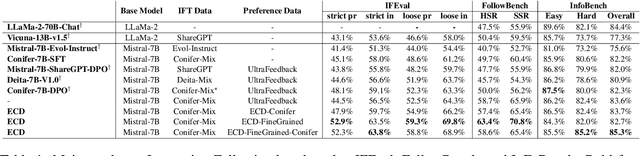
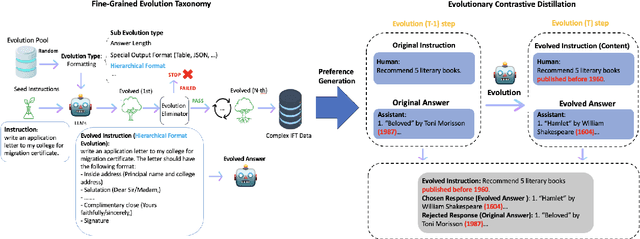

The ability of large language models (LLMs) to execute complex instructions is essential for their real-world applications. However, several recent studies indicate that LLMs struggle with challenging instructions. In this paper, we propose Evolutionary Contrastive Distillation (ECD), a novel method for generating high-quality synthetic preference data designed to enhance the complex instruction-following capability of language models. ECD generates data that specifically illustrates the difference between a response that successfully follows a set of complex instructions and a response that is high-quality, but nevertheless makes some subtle mistakes. This is done by prompting LLMs to progressively evolve simple instructions to more complex instructions. When the complexity of an instruction is increased, the original successful response to the original instruction becomes a "hard negative" response for the new instruction, mostly meeting requirements of the new instruction, but barely missing one or two. By pairing a good response with such a hard negative response, and employing contrastive learning algorithms such as DPO, we improve language models' ability to follow complex instructions. Empirically, we observe that our method yields a 7B model that exceeds the complex instruction-following performance of current SOTA 7B models and is competitive even with open-source 70B models.
Exposing Privacy Gaps: Membership Inference Attack on Preference Data for LLM Alignment
Jul 08, 2024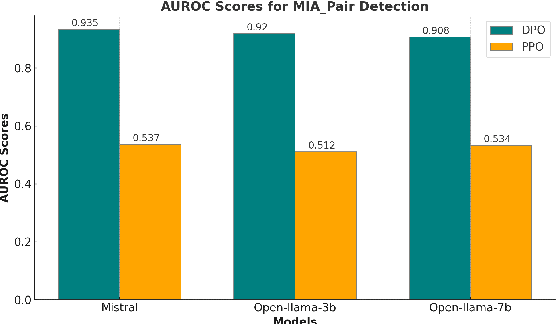
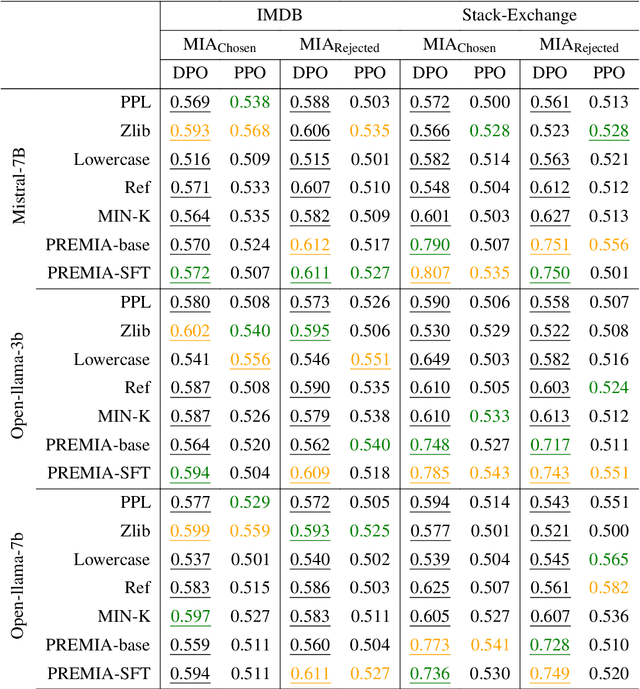
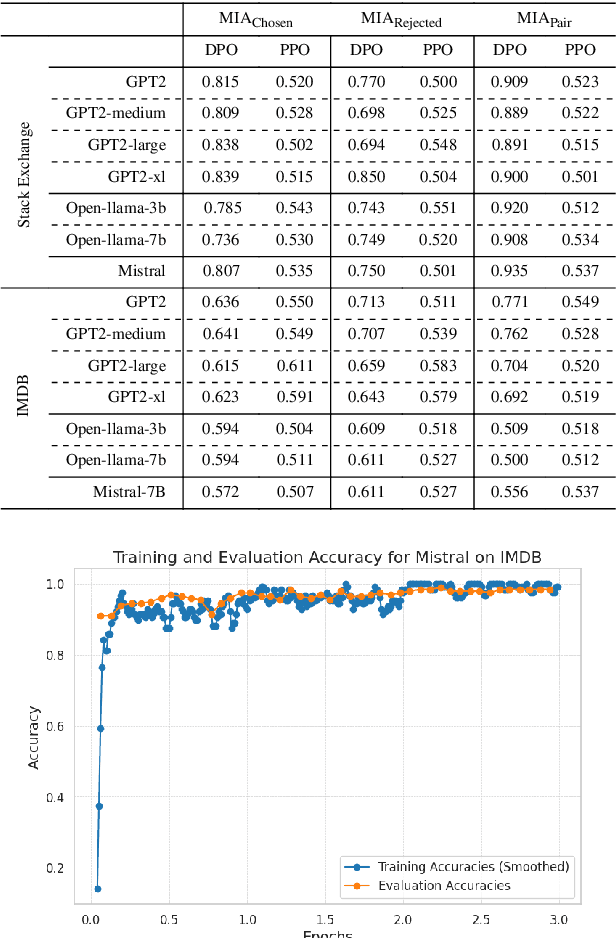
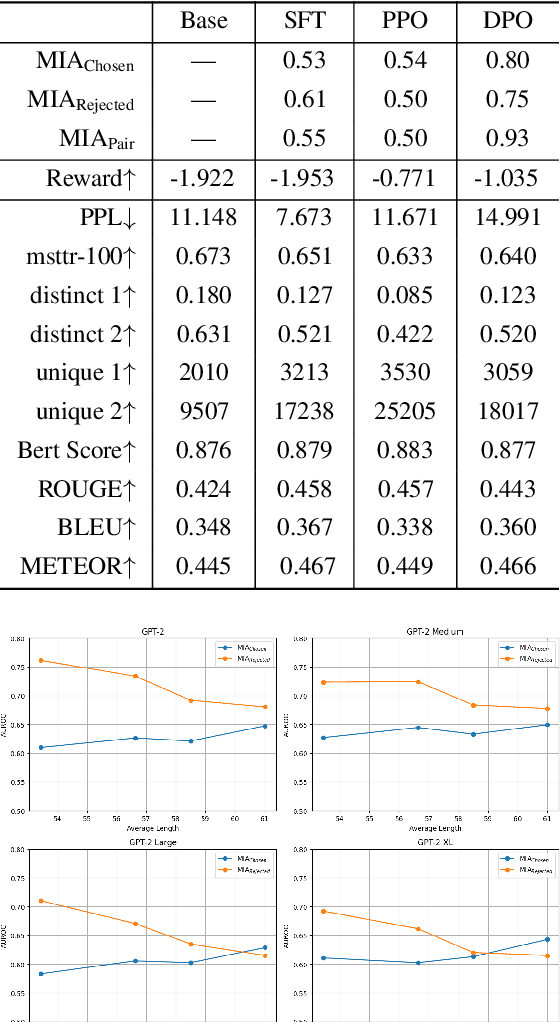
Large Language Models (LLMs) have seen widespread adoption due to their remarkable natural language capabilities. However, when deploying them in real-world settings, it is important to align LLMs to generate texts according to acceptable human standards. Methods such as Proximal Policy Optimization (PPO) and Direct Preference Optimization (DPO) have made significant progress in refining LLMs using human preference data. However, the privacy concerns inherent in utilizing such preference data have yet to be adequately studied. In this paper, we investigate the vulnerability of LLMs aligned using human preference datasets to membership inference attacks (MIAs), highlighting the shortcomings of previous MIA approaches with respect to preference data. Our study has two main contributions: first, we introduce a novel reference-based attack framework specifically for analyzing preference data called PREMIA (\uline{Pre}ference data \uline{MIA}); second, we provide empirical evidence that DPO models are more vulnerable to MIA compared to PPO models. Our findings highlight gaps in current privacy-preserving practices for LLM alignment.
Robust Multi-Task Learning with Excess Risks
Feb 14, 2024



Multi-task learning (MTL) considers learning a joint model for multiple tasks by optimizing a convex combination of all task losses. To solve the optimization problem, existing methods use an adaptive weight updating scheme, where task weights are dynamically adjusted based on their respective losses to prioritize difficult tasks. However, these algorithms face a great challenge whenever label noise is present, in which case excessive weights tend to be assigned to noisy tasks that have relatively large Bayes optimal errors, thereby overshadowing other tasks and causing performance to drop across the board. To overcome this limitation, we propose Multi-Task Learning with Excess Risks (ExcessMTL), an excess risk-based task balancing method that updates the task weights by their distances to convergence instead. Intuitively, ExcessMTL assigns higher weights to worse-trained tasks that are further from convergence. To estimate the excess risks, we develop an efficient and accurate method with Taylor approximation. Theoretically, we show that our proposed algorithm achieves convergence guarantees and Pareto stationarity. Empirically, we evaluate our algorithm on various MTL benchmarks and demonstrate its superior performance over existing methods in the presence of label noise.
Threshold-aware Learning to Generate Feasible Solutions for Mixed Integer Programs
Aug 01, 2023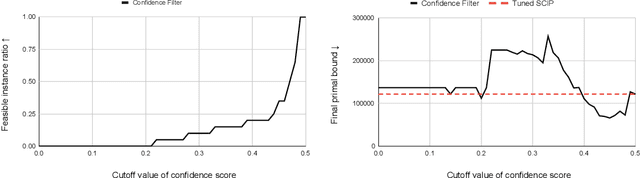

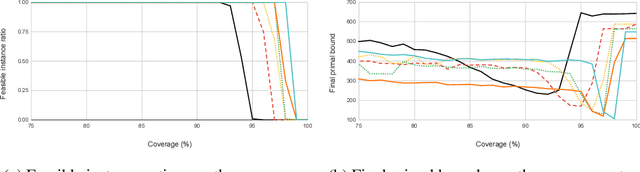
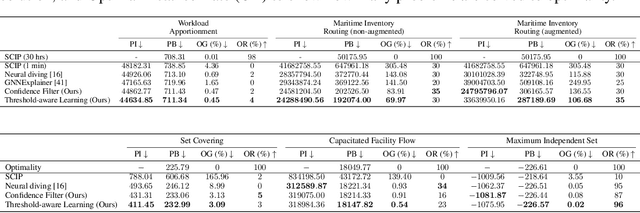
Finding a high-quality feasible solution to a combinatorial optimization (CO) problem in a limited time is challenging due to its discrete nature. Recently, there has been an increasing number of machine learning (ML) methods for addressing CO problems. Neural diving (ND) is one of the learning-based approaches to generating partial discrete variable assignments in Mixed Integer Programs (MIP), a framework for modeling CO problems. However, a major drawback of ND is a large discrepancy between the ML and MIP objectives, i.e., variable value classification accuracy over primal bound. Our study investigates that a specific range of variable assignment rates (coverage) yields high-quality feasible solutions, where we suggest optimizing the coverage bridges the gap between the learning and MIP objectives. Consequently, we introduce a post-hoc method and a learning-based approach for optimizing the coverage. A key idea of our approach is to jointly learn to restrict the coverage search space and to predict the coverage in the learned search space. Experimental results demonstrate that learning a deep neural network to estimate the coverage for finding high-quality feasible solutions achieves state-of-the-art performance in NeurIPS ML4CO datasets. In particular, our method shows outstanding performance in the workload apportionment dataset, achieving the optimality gap of 0.45%, a ten-fold improvement over SCIP within the one-minute time limit.