 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast-dLLM++: Fréchet Profile Decoding for Faster Diffusion LLM Inference
Jun 01, 2026Diffusion large language models promise parallel token generation, yet inference remains bottlenecked by deciding which masked tokens can be safely committed together. Fast-dLLM addressed this with KV caching and confidence-guided parallel decoding, but its decoding theory uses a homogeneous high-confidence assumption that effectively reduces each candidate set to its weakest selected token. We argue that this leaves speed on the table because real decoding steps exhibit heterogeneous confidence profiles. We propose \textbf{Fast-dLLM++}, a training-free extension that introduces \emph{Fréchet profile decoding}: selecting parallel commit sets from the full sorted confidence profile rather than a single worst-case confidence. The resulting rule is a heterogeneous-confidence generalization of Fast-dLLM's factor selector and it recovers the previous rule exactly in the equal-confidence case and adds a provable \emph{heterogeneity bonus} when the selected tokens have uneven confidences. Fast-dLLM++ leaves the model, diffusion process, and cache implementation entirely unchanged, making it a drop-in replacement for existing Fast-dLLM decoding. Experiments on GSM8K, MATH, HumanEval, and MBPP with the LLaDA-8B model show that the theoretical improvement translates directly into empirical gains: profile-aware selection improves the accuracy--throughput frontier by exploiting safe parallelism that weakest-token rules miss, achieving up to 37\% higher throughput at comparable accuracy. Our anonymous code release is at https://github.com/Ringo-Star/FastdLLM_plusplus.
DIVERSED: Relaxed Speculative Decoding via Dynamic Ensemble Verification
Apr 08, 2026Speculative decoding is an effective technique for accelerating large language model inference by drafting multiple tokens in parallel. In practice, its speedup is often bottlenecked by a rigid verification step that strictly enforces the accepted token distribution to exactly match the target model. This constraint leads to the rejection of many plausible tokens, lowering the acceptance rate and limiting overall time speedup. To overcome this limitation, we propose Dynamic Verification Relaxed Speculative Decoding (DIVERSED), a relaxed verification framework that improves time efficiency while preserving generation quality. DIVERSED learns an ensemble-based verifier that blends the draft and target model distributions with a task-dependent and context-dependent weight. We provide theoretical justification for our approach and demonstrate empirically that DIVERSED achieves substantially higher inference efficiency compared to standard speculative decoding methods. Code is available at: https://github.com/comeusr/diversed.
Generative or Discriminative? Revisiting Text Classification in the Era of Transformers
Jun 13, 2025The comparison between discriminative and generative classifiers has intrigued researchers since Efron's seminal analysis of logistic regression versus discriminant analysis. While early theoretical work established that generative classifiers exhibit lower sample complexity but higher asymptotic error in simple linear settings, these trade-offs remain unexplored in the transformer era. We present the first comprehensive evaluation of modern generative and discriminative architectures - Auto-regressive modeling, Masked Language Modeling, Discrete Diffusion, and Encoders for text classification. Our study reveals that the classical 'two regimes' phenomenon manifests distinctly across different architectures and training paradigms. Beyond accuracy, we analyze sample efficiency, calibration, noise robustness, and ordinality across diverse scenarios. Our findings offer practical guidance for selecting the most suitable modeling approach based on real-world constraints such as latency and data limitations.
Exposing Privacy Gaps: Membership Inference Attack on Preference Data for LLM Alignment
Jul 08, 2024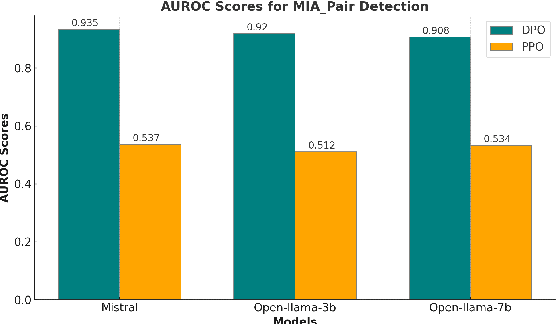
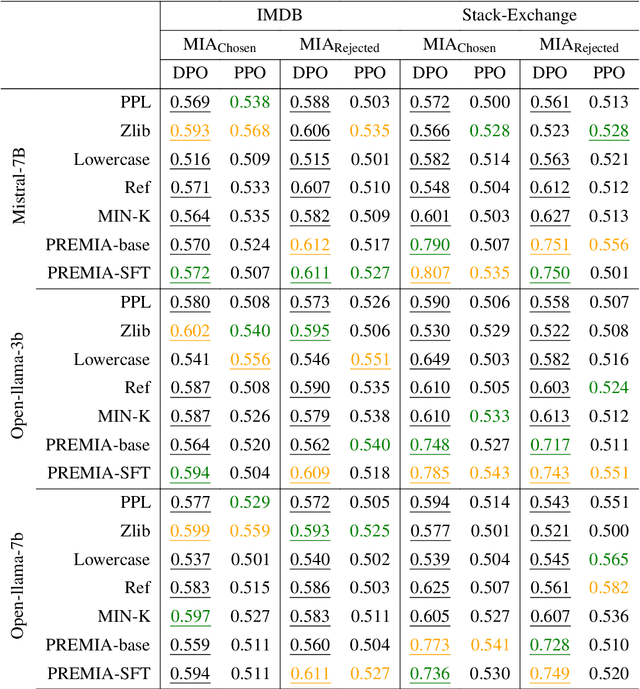
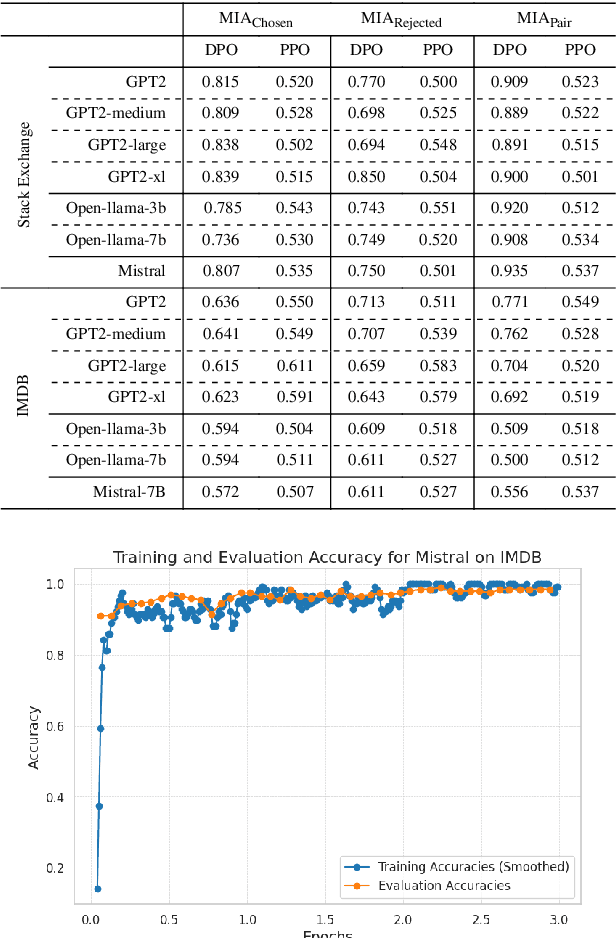
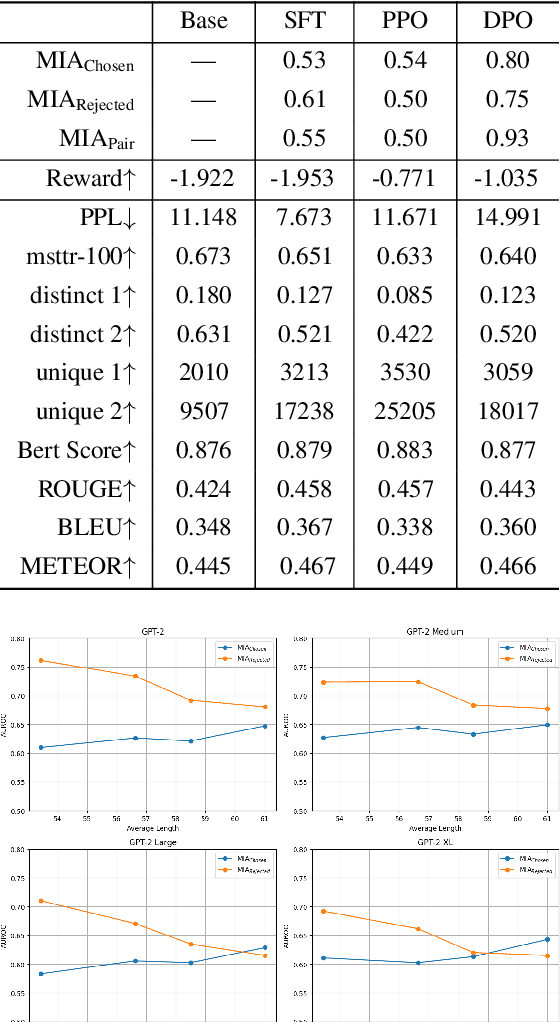
Large Language Models (LLMs) have seen widespread adoption due to their remarkable natural language capabilities. However, when deploying them in real-world settings, it is important to align LLMs to generate texts according to acceptable human standards. Methods such as Proximal Policy Optimization (PPO) and Direct Preference Optimization (DPO) have made significant progress in refining LLMs using human preference data. However, the privacy concerns inherent in utilizing such preference data have yet to be adequately studied. In this paper, we investigate the vulnerability of LLMs aligned using human preference datasets to membership inference attacks (MIAs), highlighting the shortcomings of previous MIA approaches with respect to preference data. Our study has two main contributions: first, we introduce a novel reference-based attack framework specifically for analyzing preference data called PREMIA (\uline{Pre}ference data \uline{MIA}); second, we provide empirical evidence that DPO models are more vulnerable to MIA compared to PPO models. Our findings highlight gaps in current privacy-preserving practices for LLM alignment.
Exploring Ordinality in Text Classification: A Comparative Study of Explicit and Implicit Techniques
May 20, 2024
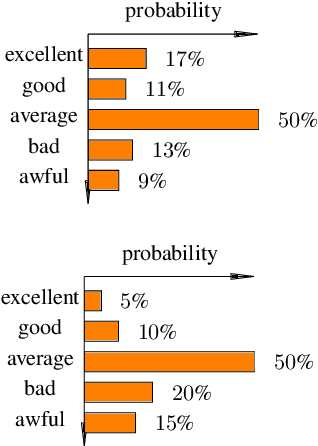
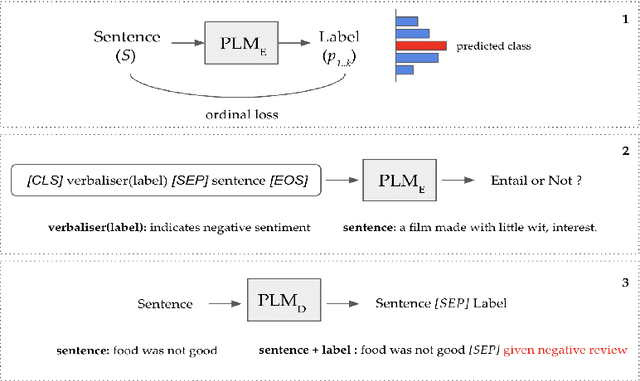

Ordinal Classification (OC) is a widely encountered challenge in Natural Language Processing (NLP), with applications in various domains such as sentiment analysis, rating prediction, and more. Previous approaches to tackle OC have primarily focused on modifying existing or creating novel loss functions that \textbf{explicitly} account for the ordinal nature of labels. However, with the advent of Pretrained Language Models (PLMs), it became possible to tackle ordinality through the \textbf{implicit} semantics of the labels as well. This paper provides a comprehensive theoretical and empirical examination of both these approaches. Furthermore, we also offer strategic recommendations regarding the most effective approach to adopt based on specific settings.
Mixture-Models: a one-stop Python Library for Model-based Clustering using various Mixture Models
Feb 08, 2024\texttt{Mixture-Models} is an open-source Python library for fitting Gaussian Mixture Models (GMM) and their variants, such as Parsimonious GMMs, Mixture of Factor Analyzers, MClust models, Mixture of Student's t distributions, etc. It streamlines the implementation and analysis of these models using various first/second order optimization routines such as Gradient Descent and Newton-CG through automatic differentiation (AD) tools. This helps in extending these models to high-dimensional data, which is first of its kind among Python libraries. The library provides user-friendly model evaluation tools, such as BIC, AIC, and log-likelihood estimation. The source-code is licensed under MIT license and can be accessed at \url{https://github.com/kasakh/Mixture-Models}. The package is highly extensible, allowing users to incorporate new distributions and optimization techniques with ease. We conduct a large scale simulation to compare the performance of various gradient based approaches against Expectation Maximization on a wide range of settings and identify the corresponding best suited approach.
How Robust are LLMs to In-Context Majority Label Bias?
Dec 27, 2023In the In-Context Learning (ICL) setup, various forms of label biases can manifest. One such manifestation is majority label bias, which arises when the distribution of labeled examples in the in-context samples is skewed towards one or more specific classes making Large Language Models (LLMs) more prone to predict those labels. Such discrepancies can arise from various factors, including logistical constraints, inherent biases in data collection methods, limited access to diverse data sources, etc. which are unavoidable in a real-world industry setup. In this work, we study the robustness of in-context learning in LLMs to shifts that occur due to majority label bias within the purview of text classification tasks. Prior works have shown that in-context learning with LLMs is susceptible to such biases. In our study, we go one level deeper and show that the robustness boundary varies widely for different models and tasks, with certain LLMs being highly robust (~90%) to majority label bias. Additionally, our findings also highlight the impact of model size and the richness of instructional prompts contributing towards model robustness. We restrict our study to only publicly available open-source models to ensure transparency and reproducibility.
Tackling Concept Shift in Text Classification using Entailment-style Modeling
Nov 06, 2023Pre-trained language models (PLMs) have seen tremendous success in text classification (TC) problems in the context of Natural Language Processing (NLP). In many real-world text classification tasks, the class definitions being learned do not remain constant but rather change with time - this is known as Concept Shift. Most techniques for handling concept shift rely on retraining the old classifiers with the newly labelled data. However, given the amount of training data required to fine-tune large DL models for the new concepts, the associated labelling costs can be prohibitively expensive and time consuming. In this work, we propose a reformulation, converting vanilla classification into an entailment-style problem that requires significantly less data to re-train the text classifier to adapt to new concepts. We demonstrate the effectiveness of our proposed method on both real world & synthetic datasets achieving absolute F1 gains upto 7% and 40% respectively in few-shot settings. Further, upon deployment, our solution also helped save 75% of labeling costs overall.