 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExposing Privacy Gaps: Membership Inference Attack on Preference Data for LLM Alignment
Paper and Code
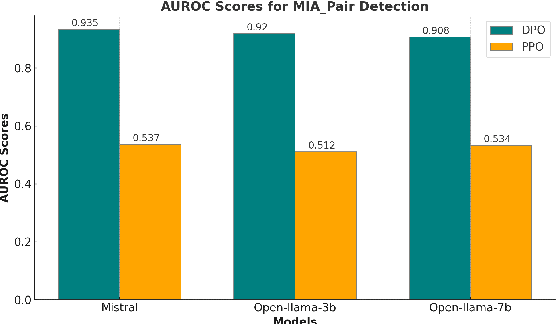
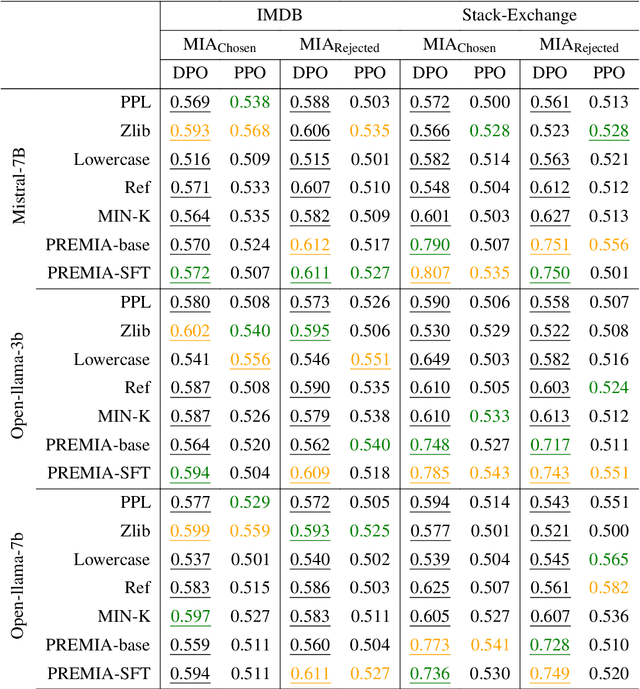
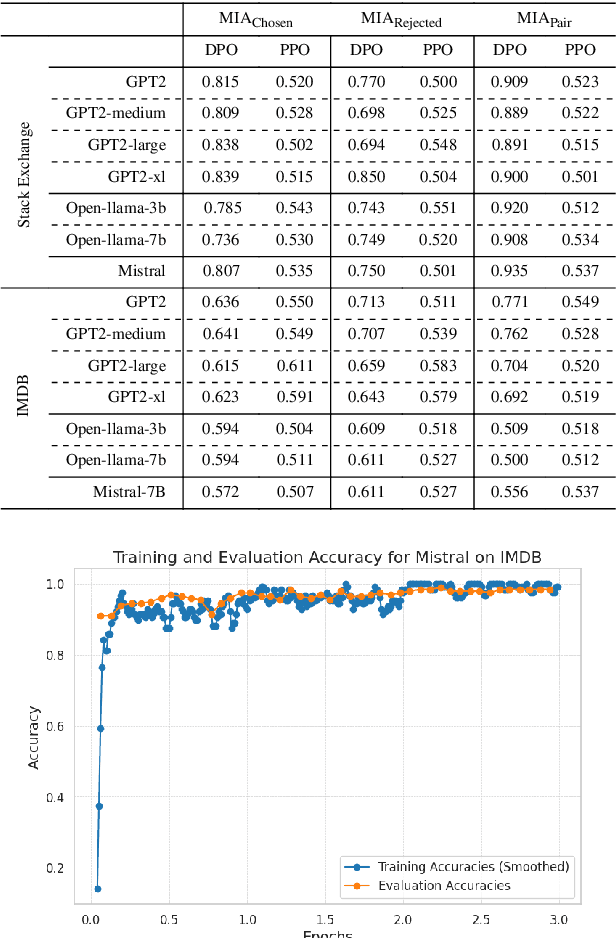
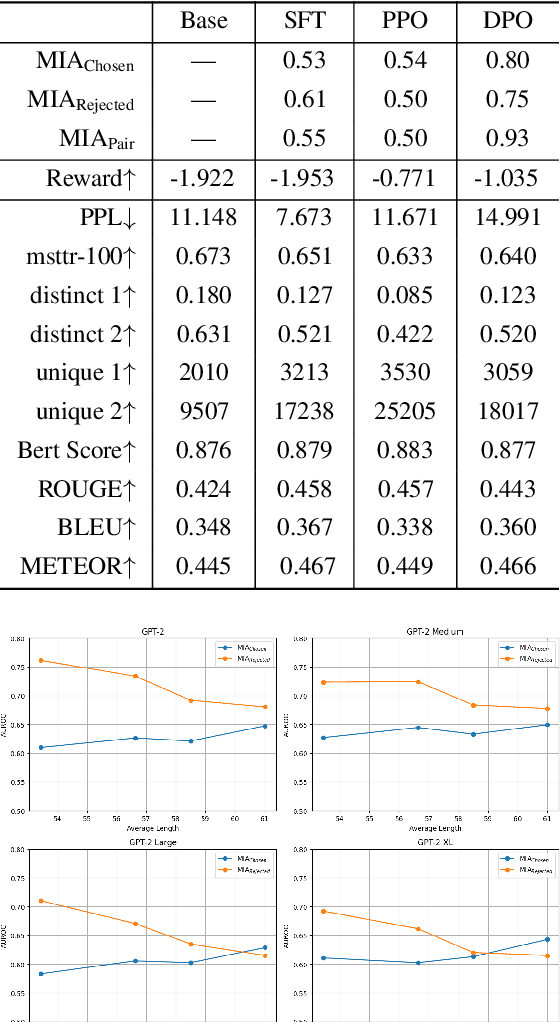
Large Language Models (LLMs) have seen widespread adoption due to their remarkable natural language capabilities. However, when deploying them in real-world settings, it is important to align LLMs to generate texts according to acceptable human standards. Methods such as Proximal Policy Optimization (PPO) and Direct Preference Optimization (DPO) have made significant progress in refining LLMs using human preference data. However, the privacy concerns inherent in utilizing such preference data have yet to be adequately studied. In this paper, we investigate the vulnerability of LLMs aligned using human preference datasets to membership inference attacks (MIAs), highlighting the shortcomings of previous MIA approaches with respect to preference data. Our study has two main contributions: first, we introduce a novel reference-based attack framework specifically for analyzing preference data called PREMIA (\uline{Pre}ference data \uline{MIA}); second, we provide empirical evidence that DPO models are more vulnerable to MIA compared to PPO models. Our findings highlight gaps in current privacy-preserving practices for LLM alignment.