 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstAP: Instance-Aware Vision-Language Pre-Train for Spatial-Temporal Understanding
Apr 09, 2026Current vision-language pre-training (VLP) paradigms excel at global scene understanding but struggle with instance-level reasoning due to global-only supervision. We introduce InstAP, an Instance-Aware Pre-training framework that jointly optimizes global vision-text alignment and fine-grained, instance-level contrastive alignment by grounding textual mentions to specific spatial-temporal regions. To support this, we present InstVL, a large-scale dataset (2 million images, 50,000 videos) with dual-granularity annotations: holistic scene captions and dense, grounded instance descriptions. On the InstVL benchmark, InstAP substantially outperforms existing VLP models on instance-level retrieval, and also surpasses a strong VLP baseline trained on the exact same data corpus, isolating the benefit of our instance-aware objective. Moreover, instance-centric pre-training improves global understanding: InstAP achieves competitive zero-shot performance on multiple video benchmarks, including MSR-VTT and DiDeMo. Qualitative visualizations further show that InstAP localizes textual mentions to the correct instances, while global-only models exhibit more diffuse, scene-level attention.
TrajTok: Learning Trajectory Tokens enables better Video Understanding
Feb 26, 2026Tokenization in video models, typically through patchification, generates an excessive and redundant number of tokens. This severely limits video efficiency and scalability. While recent trajectory-based tokenizers offer a promising solution by decoupling video duration from token count, they rely on complex external segmentation and tracking pipelines that are slow and task-agnostic. We propose TrajTok, an end-to-end video tokenizer module that is fully integrated and co-trained with video models for a downstream objective, dynamically adapting its token granularity to semantic complexity, independent of video duration. TrajTok contains a unified segmenter that performs implicit clustering over pixels in both space and time to directly produce object trajectories in a single forward pass. By prioritizing downstream adaptability over pixel-perfect segmentation fidelity, TrajTok is lightweight and efficient, yet empirically improves video understanding performance. With TrajTok, we implement a video CLIP model trained from scratch (TrajViT2). It achieves the best accuracy at scale across both classification and retrieval benchmarks, while maintaining efficiency comparable to the best token-merging methods. TrajTok also proves to be a versatile component beyond its role as a tokenizer. We show that it can be seamlessly integrated as either a probing head for pretrained visual features (TrajAdapter) or an alignment connector in vision-language models (TrajVLM) with especially strong performance in long-video reasoning.
HypER: Hyperbolic Echo State Networks for Capturing Stretch-and-Fold Dynamics in Chaotic Flows
Aug 25, 2025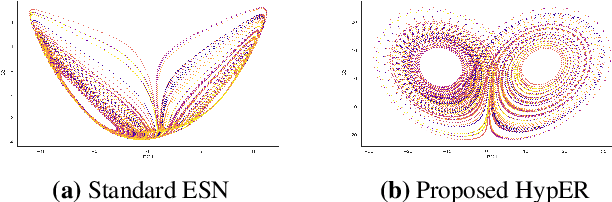
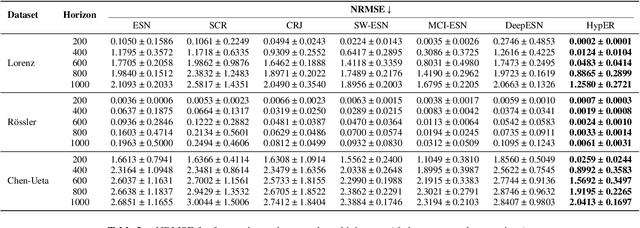
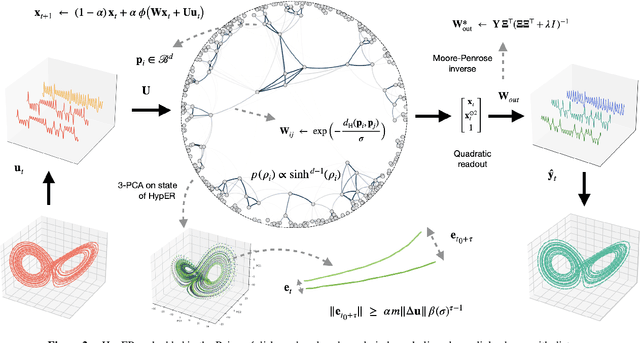
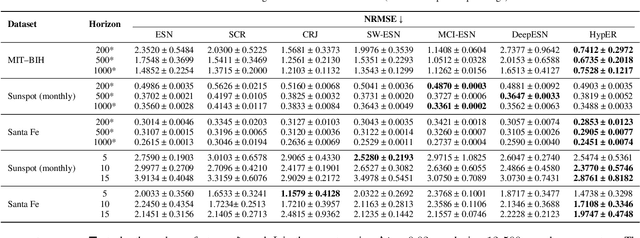
Forecasting chaotic dynamics beyond a few Lyapunov times is difficult because infinitesimal errors grow exponentially. Existing Echo State Networks (ESNs) mitigate this growth but employ reservoirs whose Euclidean geometry is mismatched to the stretch-and-fold structure of chaos. We introduce the Hyperbolic Embedding Reservoir (HypER), an ESN whose neurons are sampled in the Poincare ball and whose connections decay exponentially with hyperbolic distance. This negative-curvature construction embeds an exponential metric directly into the latent space, aligning the reservoir's local expansion-contraction spectrum with the system's Lyapunov directions while preserving standard ESN features such as sparsity, leaky integration, and spectral-radius control. Training is limited to a Tikhonov-regularized readout. On the chaotic Lorenz-63 and Roessler systems, and the hyperchaotic Chen-Ueta attractor, HypER consistently lengthens the mean valid-prediction horizon beyond Euclidean and graph-structured ESN baselines, with statistically significant gains confirmed over 30 independent runs; parallel results on real-world benchmarks, including heart-rate variability from the Santa Fe and MIT-BIH datasets and international sunspot numbers, corroborate its advantage. We further establish a lower bound on the rate of state divergence for HypER, mirroring Lyapunov growth.
Generative or Discriminative? Revisiting Text Classification in the Era of Transformers
Jun 13, 2025The comparison between discriminative and generative classifiers has intrigued researchers since Efron's seminal analysis of logistic regression versus discriminant analysis. While early theoretical work established that generative classifiers exhibit lower sample complexity but higher asymptotic error in simple linear settings, these trade-offs remain unexplored in the transformer era. We present the first comprehensive evaluation of modern generative and discriminative architectures - Auto-regressive modeling, Masked Language Modeling, Discrete Diffusion, and Encoders for text classification. Our study reveals that the classical 'two regimes' phenomenon manifests distinctly across different architectures and training paradigms. Beyond accuracy, we analyze sample efficiency, calibration, noise robustness, and ordinality across diverse scenarios. Our findings offer practical guidance for selecting the most suitable modeling approach based on real-world constraints such as latency and data limitations.
Dynamics and Computational Principles of Echo State Networks: A Mathematical Perspective
Apr 16, 2025Reservoir computing (RC) represents a class of state-space models (SSMs) characterized by a fixed state transition mechanism (the reservoir) and a flexible readout layer that maps from the state space. It is a paradigm of computational dynamical systems that harnesses the transient dynamics of high-dimensional state spaces for efficient processing of temporal data. Rooted in concepts from recurrent neural networks, RC achieves exceptional computational power by decoupling the training of the dynamic reservoir from the linear readout layer, thereby circumventing the complexities of gradient-based optimization. This work presents a systematic exploration of RC, addressing its foundational properties such as the echo state property, fading memory, and reservoir capacity through the lens of dynamical systems theory. We formalize the interplay between input signals and reservoir states, demonstrating the conditions under which reservoirs exhibit stability and expressive power. Further, we delve into the computational trade-offs and robustness characteristics of RC architectures, extending the discussion to their applications in signal processing, time-series prediction, and control systems. The analysis is complemented by theoretical insights into optimization, training methodologies, and scalability, highlighting open challenges and potential directions for advancing the theoretical underpinnings of RC.
From Fog to Failure: How Dehazing Can Harm Clear Image Object Detection
Feb 04, 2025



This study explores the challenges of integrating human visual cue-based dehazing into object detection, given the selective nature of human perception. While human vision adapts dynamically to environmental conditions, computational dehazing does not always enhance detection uniformly. We propose a multi-stage framework where a lightweight detector identifies regions of interest (RoIs), which are then enhanced via spatial attention-based dehazing before final detection by a heavier model. Though effective in foggy conditions, this approach unexpectedly degrades the performance on clear images. We analyze this phenomenon, investigate possible causes, and offer insights for designing hybrid pipelines that balance enhancement and detection. Our findings highlight the need for selective preprocessing and challenge assumptions about universal benefits from cascading transformations.
IndicMMLU-Pro: Benchmarking the Indic Large Language Models
Jan 27, 2025Known by more than 1.5 billion people in the Indian subcontinent, Indic languages present unique challenges and opportunities for natural language processing (NLP) research due to their rich cultural heritage, linguistic diversity, and complex structures. IndicMMLU-Pro is a comprehensive benchmark designed to evaluate Large Language Models (LLMs) across Indic languages, building upon the MMLU Pro (Massive Multitask Language Understanding) framework. Covering major languages such as Hindi, Bengali, Gujarati, Marathi, Kannada, Punjabi, Tamil, Telugu, and Urdu, our benchmark addresses the unique challenges and opportunities presented by the linguistic diversity of the Indian subcontinent. This benchmark encompasses a wide range of tasks in language comprehension, reasoning, and generation, meticulously crafted to capture the intricacies of Indian languages. IndicMMLU-Pro provides a standardized evaluation framework to push the research boundaries in Indic language AI, facilitating the development of more accurate, efficient, and culturally sensitive models. This paper outlines the benchmarks' design principles, task taxonomy, data collection methodology, and presents baseline results from state-of-the-art multilingual models.
MoonMetaSync: Lunar Image Registration Analysis
Oct 14, 2024



This paper compares scale-invariant (SIFT) and scale-variant (ORB) feature detection methods, alongside our novel feature detector, IntFeat, specifically applied to lunar imagery. We evaluate these methods using low (128x128) and high-resolution (1024x1024) lunar image patches, providing insights into their performance across scales in challenging extraterrestrial environments. IntFeat combines high-level features from SIFT and low-level features from ORB into a single vector space for robust lunar image registration. We introduce SyncVision, a Python package that compares lunar images using various registration methods, including SIFT, ORB, and IntFeat. Our analysis includes upscaling low-resolution lunar images using bi-linear and bi-cubic interpolation, offering a unique perspective on registration effectiveness across scales and feature detectors in lunar landscapes. This research contributes to computer vision and planetary science by comparing feature detection methods for lunar imagery and introducing a versatile tool for lunar image registration and evaluation, with implications for multi-resolution image analysis in space exploration applications.
Perceptual Piercing: Human Visual Cue-based Object Detection in Low Visibility Conditions
Oct 02, 2024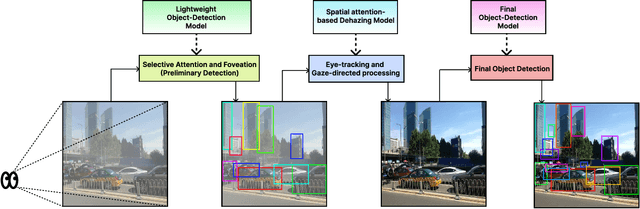
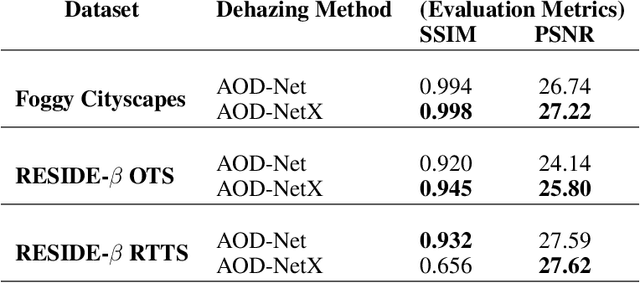
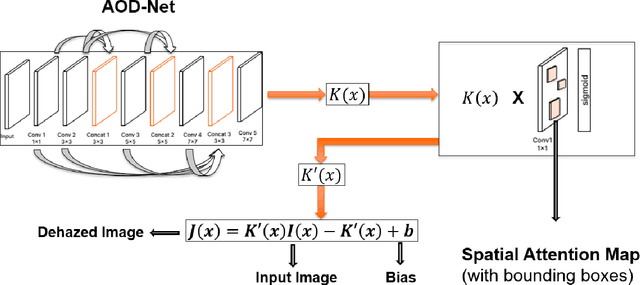
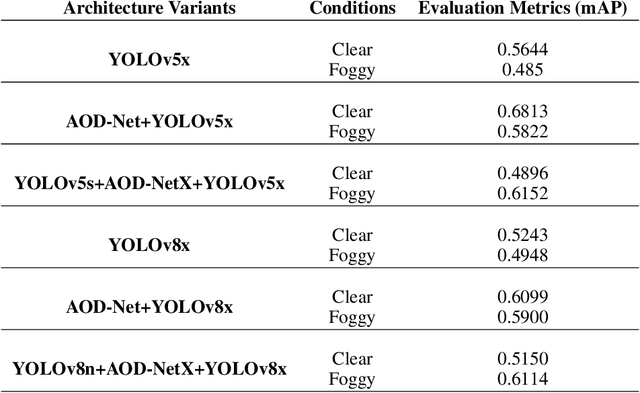
This study proposes a novel deep learning framework inspired by atmospheric scattering and human visual cortex mechanisms to enhance object detection under poor visibility scenarios such as fog, smoke, and haze. These conditions pose significant challenges for object recognition, impacting various sectors, including autonomous driving, aviation management, and security systems. The objective is to enhance the precision and reliability of detection systems under adverse environmental conditions. The research investigates the integration of human-like visual cues, particularly focusing on selective attention and environmental adaptability, to ascertain their impact on object detection's computational efficiency and accuracy. This paper proposes a multi-tiered strategy that integrates an initial quick detection process, followed by targeted region-specific dehazing, and concludes with an in-depth detection phase. The approach is validated using the Foggy Cityscapes, RESIDE-beta (OTS and RTTS) datasets and is anticipated to set new performance standards in detection accuracy while significantly optimizing computational efficiency. The findings offer a viable solution for enhancing object detection in poor visibility and contribute to the broader understanding of integrating human visual principles into deep learning algorithms for intricate visual recognition challenges.
Moonshine: Distilling Game Content Generators into Steerable Generative Models
Aug 18, 2024



Procedural Content Generation via Machine Learning (PCGML) has enhanced game content creation, yet challenges in controllability and limited training data persist. This study addresses these issues by distilling a constructive PCG algorithm into a controllable PCGML model. We first generate a large amount of content with a constructive algorithm and label it using a Large Language Model (LLM). We use these synthetic labels to condition two PCGML models for content-specific generation, a diffusion model and the five-dollar model. This neural network distillation process ensures that the generation aligns with the original algorithm while introducing controllability through plain text. We define this text-conditioned PCGML as a Text-to-game-Map (T2M) task, offering an alternative to prevalent text-to-image multi-modal tasks. We compare our distilled models with the baseline constructive algorithm. Our analysis of the variety, accuracy, and quality of our generation demonstrates the efficacy of distilling constructive methods into controllable text-conditioned PCGML models.