 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative or Discriminative? Revisiting Text Classification in the Era of Transformers
Jun 13, 2025The comparison between discriminative and generative classifiers has intrigued researchers since Efron's seminal analysis of logistic regression versus discriminant analysis. While early theoretical work established that generative classifiers exhibit lower sample complexity but higher asymptotic error in simple linear settings, these trade-offs remain unexplored in the transformer era. We present the first comprehensive evaluation of modern generative and discriminative architectures - Auto-regressive modeling, Masked Language Modeling, Discrete Diffusion, and Encoders for text classification. Our study reveals that the classical 'two regimes' phenomenon manifests distinctly across different architectures and training paradigms. Beyond accuracy, we analyze sample efficiency, calibration, noise robustness, and ordinality across diverse scenarios. Our findings offer practical guidance for selecting the most suitable modeling approach based on real-world constraints such as latency and data limitations.
Exploring Ordinality in Text Classification: A Comparative Study of Explicit and Implicit Techniques
May 20, 2024
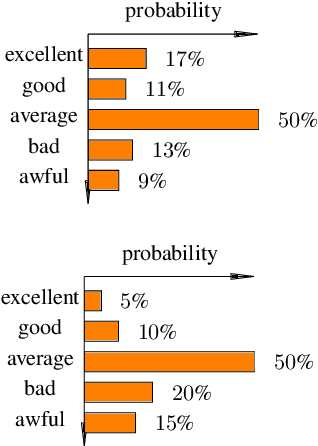

Ordinal Classification (OC) is a widely encountered challenge in Natural Language Processing (NLP), with applications in various domains such as sentiment analysis, rating prediction, and more. Previous approaches to tackle OC have primarily focused on modifying existing or creating novel loss functions that \textbf{explicitly} account for the ordinal nature of labels. However, with the advent of Pretrained Language Models (PLMs), it became possible to tackle ordinality through the \textbf{implicit} semantics of the labels as well. This paper provides a comprehensive theoretical and empirical examination of both these approaches. Furthermore, we also offer strategic recommendations regarding the most effective approach to adopt based on specific settings.
How Robust are LLMs to In-Context Majority Label Bias?
Dec 27, 2023In the In-Context Learning (ICL) setup, various forms of label biases can manifest. One such manifestation is majority label bias, which arises when the distribution of labeled examples in the in-context samples is skewed towards one or more specific classes making Large Language Models (LLMs) more prone to predict those labels. Such discrepancies can arise from various factors, including logistical constraints, inherent biases in data collection methods, limited access to diverse data sources, etc. which are unavoidable in a real-world industry setup. In this work, we study the robustness of in-context learning in LLMs to shifts that occur due to majority label bias within the purview of text classification tasks. Prior works have shown that in-context learning with LLMs is susceptible to such biases. In our study, we go one level deeper and show that the robustness boundary varies widely for different models and tasks, with certain LLMs being highly robust (~90%) to majority label bias. Additionally, our findings also highlight the impact of model size and the richness of instructional prompts contributing towards model robustness. We restrict our study to only publicly available open-source models to ensure transparency and reproducibility.
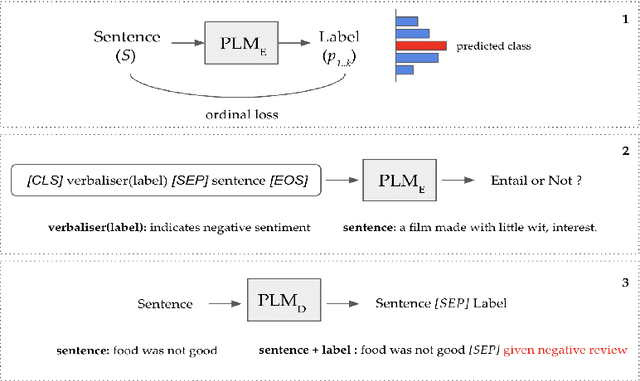
Tackling Concept Shift in Text Classification using Entailment-style Modeling
Nov 06, 2023Pre-trained language models (PLMs) have seen tremendous success in text classification (TC) problems in the context of Natural Language Processing (NLP). In many real-world text classification tasks, the class definitions being learned do not remain constant but rather change with time - this is known as Concept Shift. Most techniques for handling concept shift rely on retraining the old classifiers with the newly labelled data. However, given the amount of training data required to fine-tune large DL models for the new concepts, the associated labelling costs can be prohibitively expensive and time consuming. In this work, we propose a reformulation, converting vanilla classification into an entailment-style problem that requires significantly less data to re-train the text classifier to adapt to new concepts. We demonstrate the effectiveness of our proposed method on both real world & synthetic datasets achieving absolute F1 gains upto 7% and 40% respectively in few-shot settings. Further, upon deployment, our solution also helped save 75% of labeling costs overall.
CRUSH: Contextually Regularized and User anchored Self-supervised Hate speech Detection
Apr 13, 2022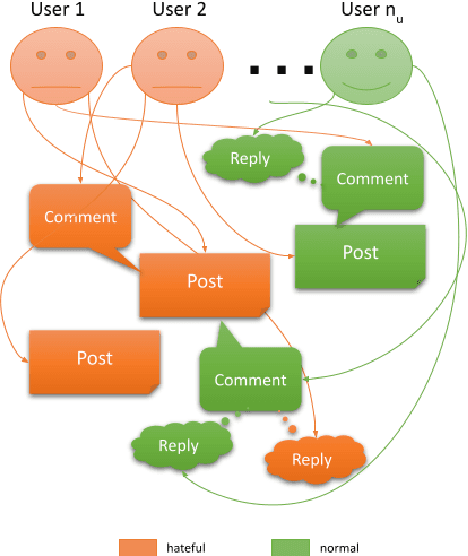
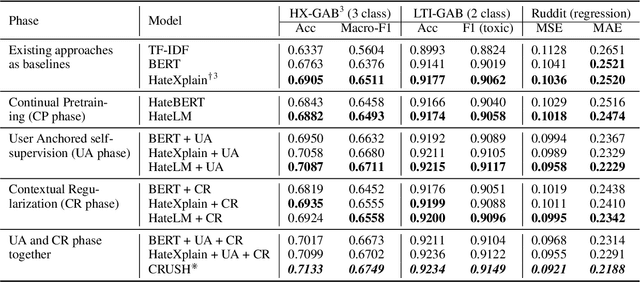
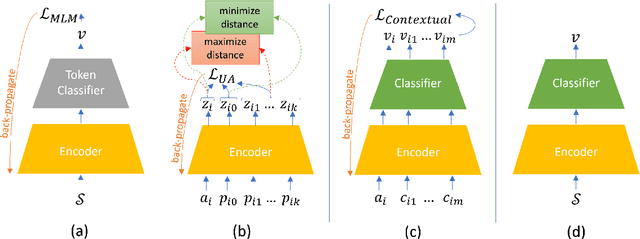
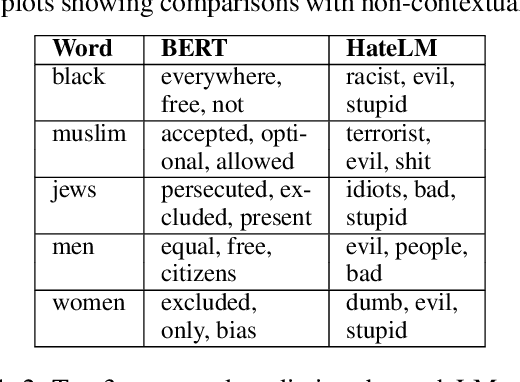
The last decade has witnessed a surge in the interaction of people through social networking platforms. While there are several positive aspects of these social platforms, the proliferation has led them to become the breeding ground for cyber-bullying and hate speech. Recent advances in NLP have often been used to mitigate the spread of such hateful content. Since the task of hate speech detection is usually applicable in the context of social networks, we introduce CRUSH, a framework for hate speech detection using user-anchored self-supervision and contextual regularization. Our proposed approach secures ~ 1-12% improvement in test set metrics over best performing previous approaches on two types of tasks and multiple popular english social media datasets.
Representation Learning for Conversational Data using Discourse Mutual Information Maximization
Dec 04, 2021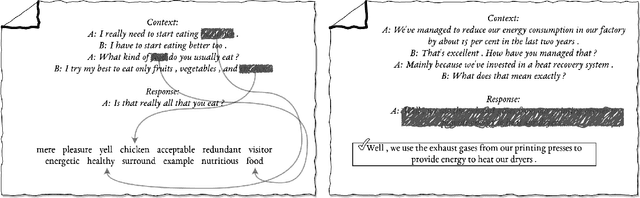
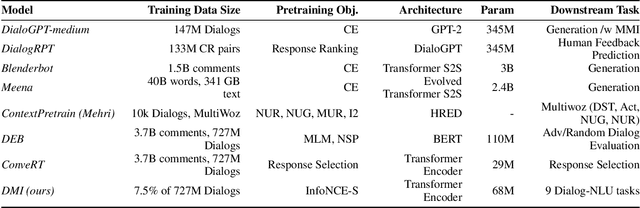
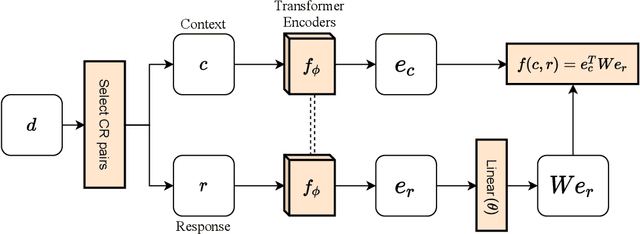
Although many pretrained models exist for text or images, there have been relatively fewer attempts to train representations specifically for dialog understanding. Prior works usually relied on finetuned representations based on generic text representation models like BERT or GPT-2. But, existing pretraining objectives do not take the structural information of text into consideration. Although generative dialog models can learn structural features too, we argue that the structure-unaware word-by-word generation is not suitable for effective conversation modeling. We empirically demonstrate that such representations do not perform consistently across various dialog understanding tasks. Hence, we propose a structure-aware Mutual Information based loss-function DMI (Discourse Mutual Information) for training dialog-representation models, that additionally captures the inherent uncertainty in response prediction. Extensive evaluation on nine diverse dialog modeling tasks shows that our proposed DMI-based models outperform strong baselines by significant margins, even with small-scale pretraining. Our models show the most promising performance on the dialog evaluation task DailyDialog++, in both random and adversarial negative scenarios.
Video2Skill: Adapting Events in Demonstration Videos to Skills in an Environment using Cyclic MDP Homomorphisms
Sep 09, 2021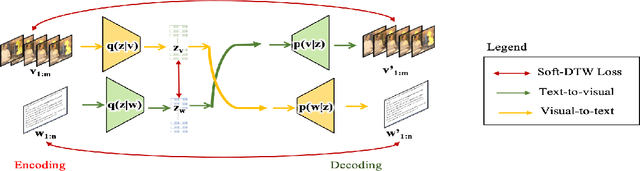
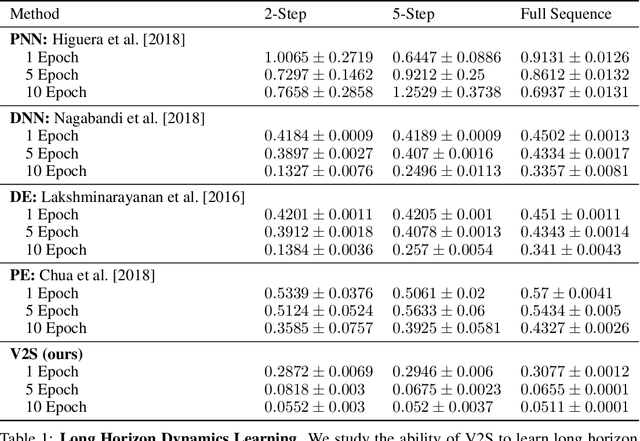
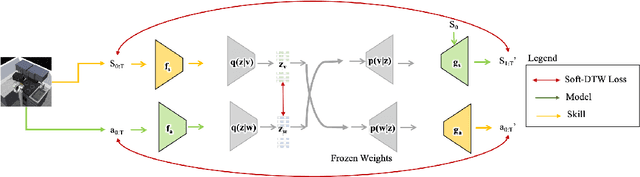
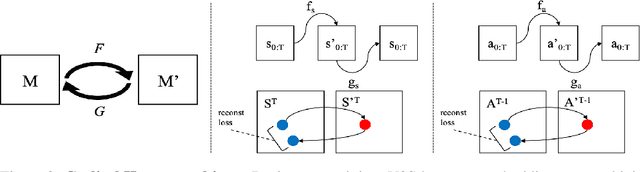
Humans excel at learning long-horizon tasks from demonstrations augmented with textual commentary, as evidenced by the burgeoning popularity of tutorial videos online. Intuitively, this capability can be separated into 2 distinct subtasks - first, dividing a long-horizon demonstration sequence into semantically meaningful events; second, adapting such events into meaningful behaviors in one's own environment. Here, we present Video2Skill (V2S), which attempts to extend this capability to artificial agents by allowing a robot arm to learn from human cooking videos. We first use sequence-to-sequence Auto-Encoder style architectures to learn a temporal latent space for events in long-horizon demonstrations. We then transfer these representations to the robotic target domain, using a small amount of offline and unrelated interaction data (sequences of state-action pairs of the robot arm controlled by an expert) to adapt these events into actionable representations, i.e., skills. Through experiments, we demonstrate that our approach results in self-supervised analogy learning, where the agent learns to draw analogies between motions in human demonstration data and behaviors in the robotic environment. We also demonstrate the efficacy of our approach on model learning - demonstrating how Video2Skill utilizes prior knowledge from human demonstration to outperform traditional model learning of long-horizon dynamics. Finally, we demonstrate the utility of our approach for non-tabula rasa decision-making, i.e, utilizing video demonstration for zero-shot skill generation.
Leveraging Post Hoc Context for Faster Learning in Bandit Settings with Applications in Robot-Assisted Feeding
Nov 05, 2020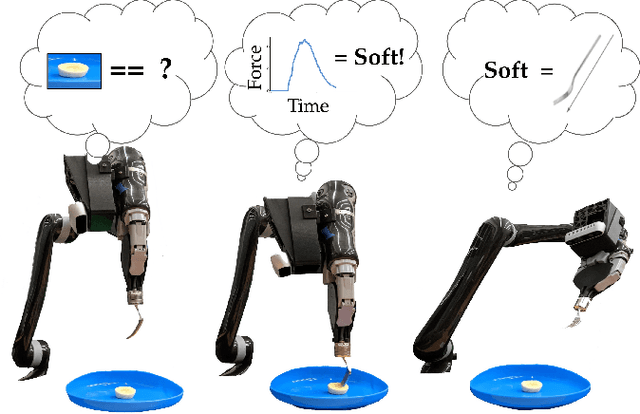
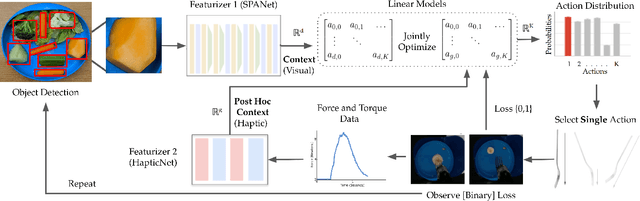


Autonomous robot-assisted feeding requires the ability to acquire a wide variety of food items. However, it is impossible for such a system to be trained on all types of food in existence. Therefore, a key challenge is choosing a manipulation strategy for a previously unseen food item. Previous work showed that the problem can be represented as a linear contextual bandit on visual information. However, food has a wide variety of multi-modal properties relevant to manipulation that can be hard to distinguish visually. Our key insight is that we can leverage the haptic information we collect during manipulation to learn some of these properties and more quickly adapt our visual model to previously unseen food. In general, we propose a modified linear contextual bandit framework augmented with post hoc context observed after action selection to empirically increase learning speed (as measured by cross-validation mean square error) and reduce cumulative regret. Experiments on synthetic data demonstrate that this effect is more pronounced when the dimensionality of the context is large relative to the post hoc context or when the post hoc context model is particularly easy to learn. Finally, we apply this framework to the bite acquisition problem and demonstrate the acquisition of 8 previously unseen types of food with 21% fewer failures across 64 attempts.
Unsupervised Hierarchical Concept Learning
Oct 06, 2020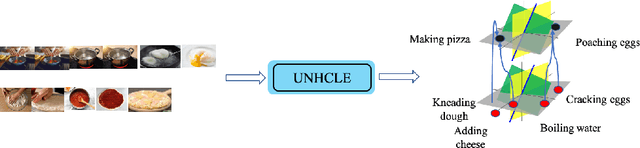

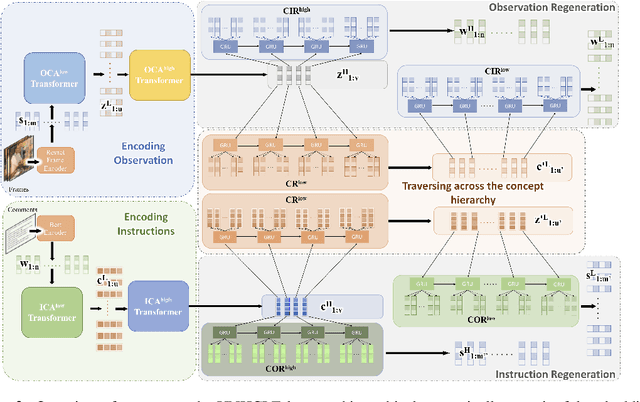
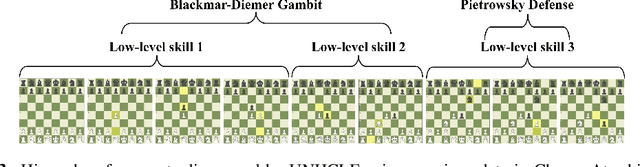
Discovering concepts (or temporal abstractions) in an unsupervised manner from demonstration data in the absence of an environment is an important problem. Organizing these discovered concepts hierarchically at different levels of abstraction is useful in discovering patterns, building ontologies, and generating tutorials from demonstration data. However, recent work to discover such concepts without access to any environment does not discover relationships (or a hierarchy) between these discovered concepts. In this paper, we present a Transformer-based concept abstraction architecture UNHCLE (pronounced uncle) that extracts a hierarchy of concepts in an unsupervised way from demonstration data. We empirically demonstrate how UNHCLE discovers meaningful hierarchies using datasets from Chess and Cooking domains. Finally, we show how UNHCLE learns meaningful language labels for concepts by using demonstration data augmented with natural language for cooking and chess. All of our code is available at https://github.com/UNHCLE/UNHCLE
Exploring Effects of Random Walk Based Minibatch Selection Policy on Knowledge Graph Completion
Apr 12, 2020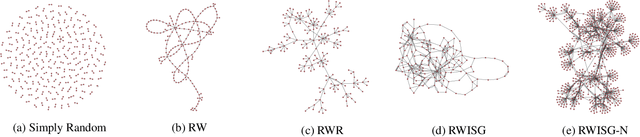
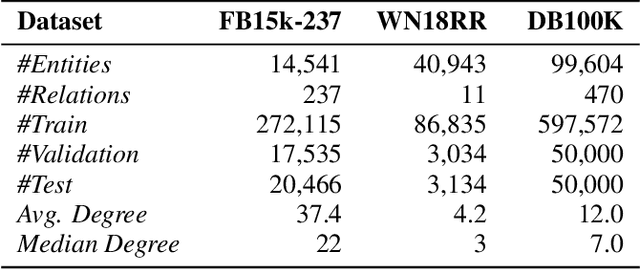
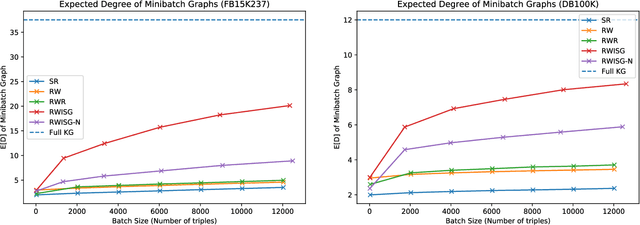
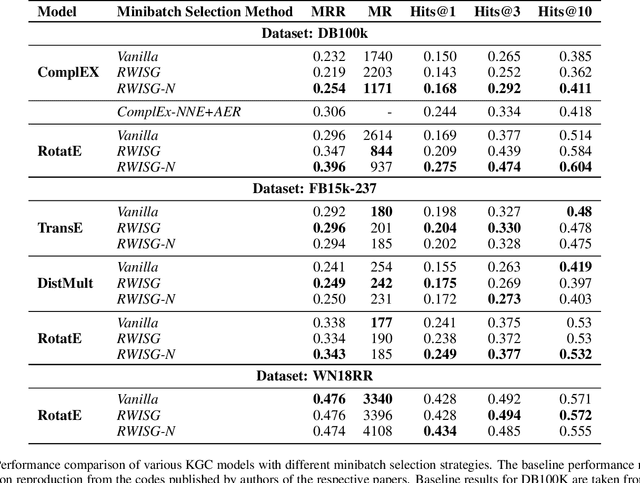
In this paper, we have explored the effects of different minibatch sampling techniques in Knowledge Graph Completion. Knowledge Graph Completion (KGC) or Link Prediction is the task of predicting missing facts in a knowledge graph. KGC models are usually trained using margin, soft-margin or cross-entropy loss function that promotes assigning a higher score or probability for true fact triplets. Minibatch gradient descent is used to optimize these loss functions for training the KGC models. But, as each minibatch consists of only a few randomly sampled triplets from a large knowledge graph, any entity that occurs in a minibatch, occurs only once in most cases. Because of this, these loss functions ignore all other neighbors of any entity, whose embedding is being updated at some minibatch step. In this paper, we propose a new random-walk based minibatch sampling technique for training KGC models that optimizes the loss incurred by a minibatch of closely connected subgraph of triplets instead of randomly selected ones. We have shown results of experiments for different models and datasets with our sampling technique and found that the proposed sampling algorithm has varying effects on these datasets/models. Specifically, we find that our proposed method achieves state-of-the-art performance on the DB100K dataset.