 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Reinforcement Learning Strategies for Offline Policy Improvement
Dec 17, 2024



Learning agents that excel at sequential decision-making tasks must continuously resolve the problem of exploration and exploitation for optimal learning. However, such interactions with the environment online might be prohibitively expensive and may involve some constraints, such as a limited budget for agent-environment interactions and restricted exploration in certain regions of the state space. Examples include selecting candidates for medical trials and training agents in complex navigation environments. This problem necessitates the study of active reinforcement learning strategies that collect minimal additional experience trajectories by reusing existing offline data previously collected by some unknown behavior policy. In this work, we propose a representation-aware uncertainty-based active trajectory collection method that intelligently decides interaction strategies that consider the distribution of the existing offline data. With extensive experimentation, we demonstrate that our proposed method reduces additional online interaction with the environment by up to 75% over competitive baselines across various continuous control environments.
Deep Representation Learning for Prediction of Temporal Event Sets in the Continuous Time Domain
Sep 29, 2023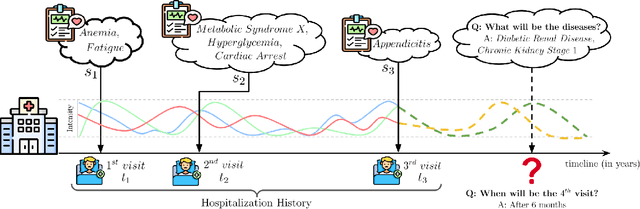
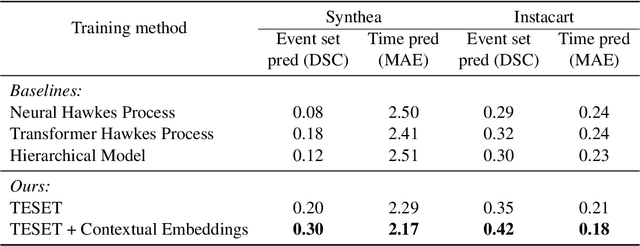
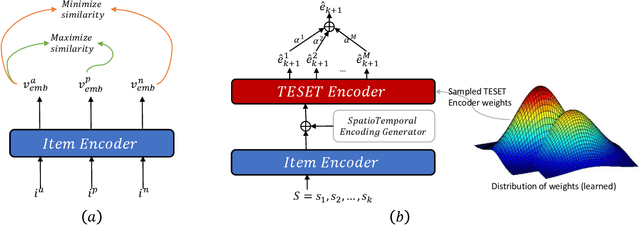
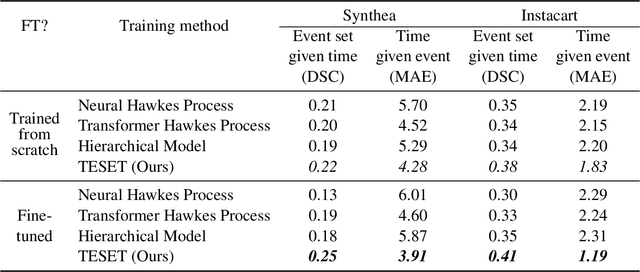
Temporal Point Processes (TPP) play an important role in predicting or forecasting events. Although these problems have been studied extensively, predicting multiple simultaneously occurring events can be challenging. For instance, more often than not, a patient gets admitted to a hospital with multiple conditions at a time. Similarly people buy more than one stock and multiple news breaks out at the same time. Moreover, these events do not occur at discrete time intervals, and forecasting event sets in the continuous time domain remains an open problem. Naive approaches for extending the existing TPP models for solving this problem lead to dealing with an exponentially large number of events or ignoring set dependencies among events. In this work, we propose a scalable and efficient approach based on TPPs to solve this problem. Our proposed approach incorporates contextual event embeddings, temporal information, and domain features to model the temporal event sets. We demonstrate the effectiveness of our approach through extensive experiments on multiple datasets, showing that our model outperforms existing methods in terms of prediction metrics and computational efficiency. To the best of our knowledge, this is the first work that solves the problem of predicting event set intensities in the continuous time domain by using TPPs.
CRUSH: Contextually Regularized and User anchored Self-supervised Hate speech Detection
Apr 13, 2022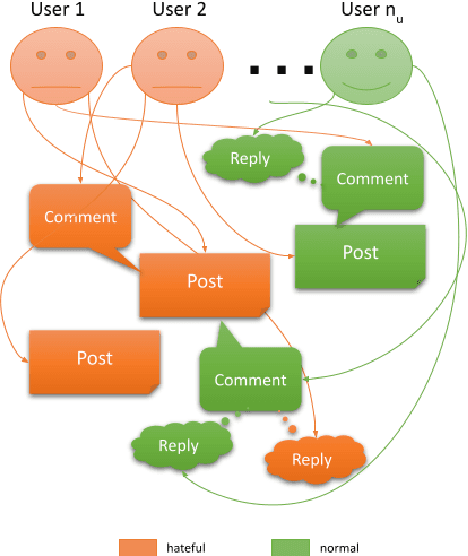
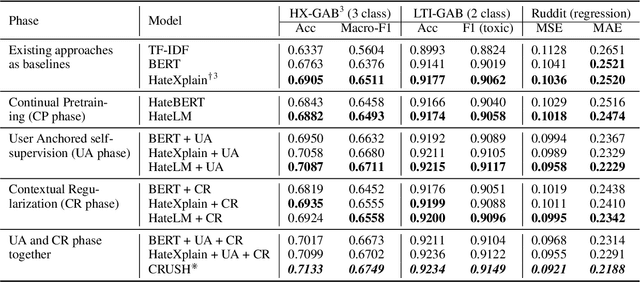
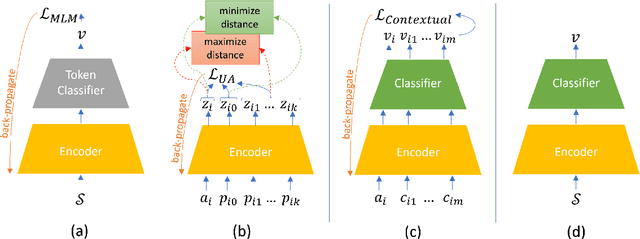
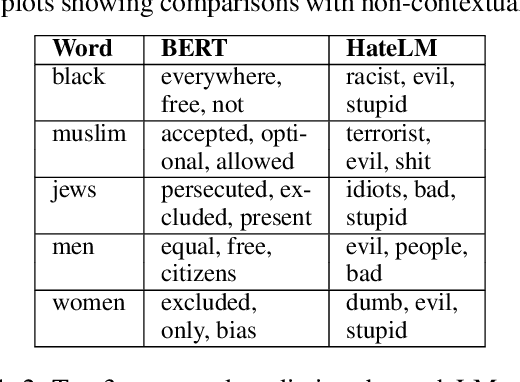
The last decade has witnessed a surge in the interaction of people through social networking platforms. While there are several positive aspects of these social platforms, the proliferation has led them to become the breeding ground for cyber-bullying and hate speech. Recent advances in NLP have often been used to mitigate the spread of such hateful content. Since the task of hate speech detection is usually applicable in the context of social networks, we introduce CRUSH, a framework for hate speech detection using user-anchored self-supervision and contextual regularization. Our proposed approach secures ~ 1-12% improvement in test set metrics over best performing previous approaches on two types of tasks and multiple popular english social media datasets.
Active$^2$ Learning: Actively reducing redundancies in Active Learning methods for Sequence Tagging and Machine Translation
Apr 03, 2021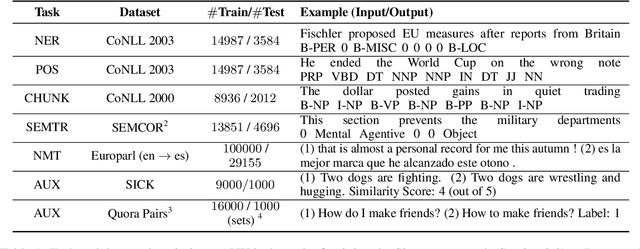
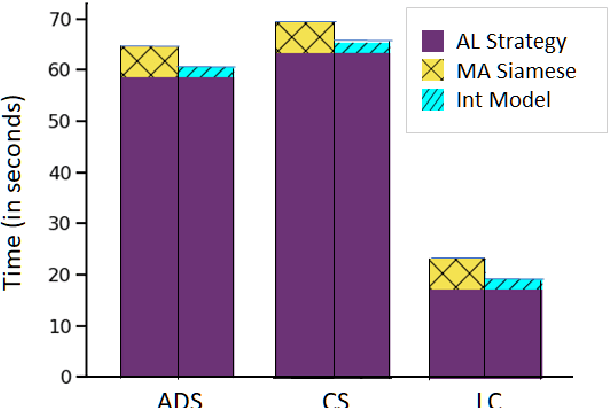

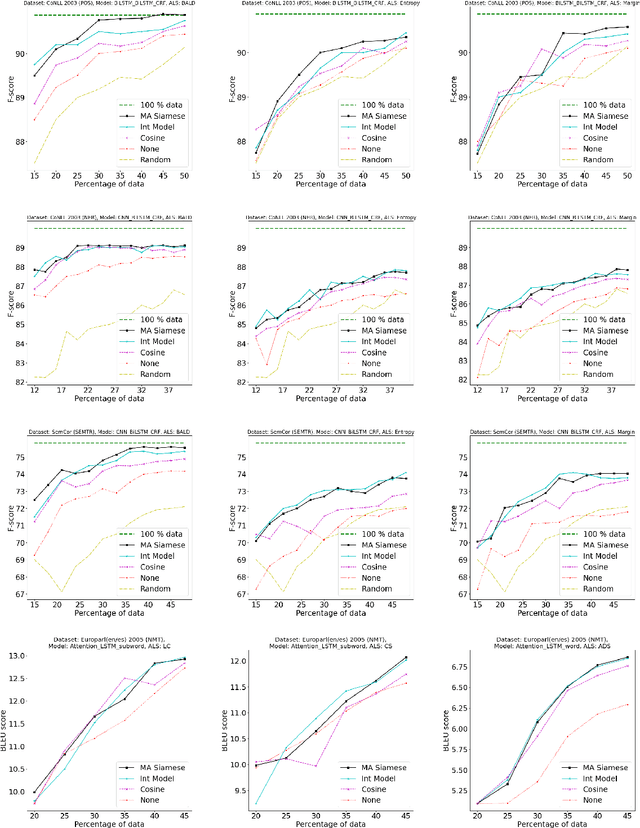
While deep learning is a powerful tool for natural language processing (NLP) problems, successful solutions to these problems rely heavily on large amounts of annotated samples. However, manually annotating data is expensive and time-consuming. Active Learning (AL) strategies reduce the need for huge volumes of labeled data by iteratively selecting a small number of examples for manual annotation based on their estimated utility in training the given model. In this paper, we argue that since AL strategies choose examples independently, they may potentially select similar examples, all of which may not contribute significantly to the learning process. Our proposed approach, Active$\mathbf{^2}$ Learning (A$\mathbf{^2}$L), actively adapts to the deep learning model being trained to eliminate further such redundant examples chosen by an AL strategy. We show that A$\mathbf{^2}$L is widely applicable by using it in conjunction with several different AL strategies and NLP tasks. We empirically demonstrate that the proposed approach is further able to reduce the data requirements of state-of-the-art AL strategies by an absolute percentage reduction of $\approx\mathbf{3-25\%}$ on multiple NLP tasks while achieving the same performance with no additional computation overhead.