 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonality Detection and Analysis using Twitter Data
Sep 11, 2023Personality types are important in various fields as they hold relevant information about the characteristics of a human being in an explainable format. They are often good predictors of a person's behaviors in a particular environment and have applications ranging from candidate selection to marketing and mental health. Recently automatic detection of personality traits from texts has gained significant attention in computational linguistics. Most personality detection and analysis methods have focused on small datasets making their experimental observations often limited. To bridge this gap, we focus on collecting and releasing the largest automatically curated dataset for the research community which has 152 million tweets and 56 thousand data points for the Myers-Briggs personality type (MBTI) prediction task. We perform a series of extensive qualitative and quantitative studies on our dataset to analyze the data patterns in a better way and infer conclusions. We show how our intriguing analysis results often follow natural intuition. We also perform a series of ablation studies to show how the baselines perform for our dataset.
Fast Few shot Self-attentive Semi-supervised Political Inclination Prediction
Sep 23, 2022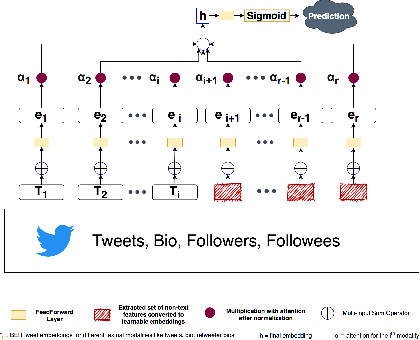
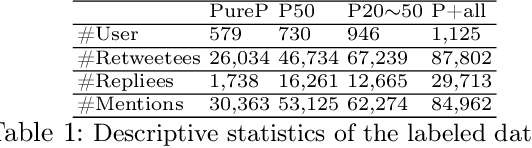
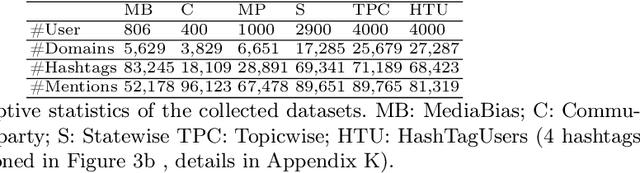
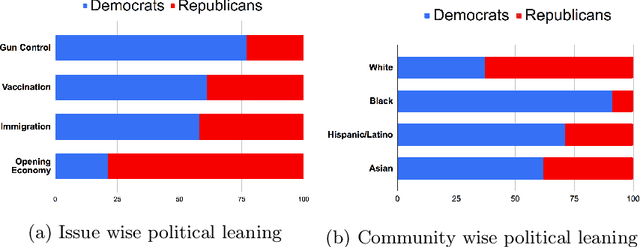
With the rising participation of the common mass in social media, it is increasingly common now for policymakers/journalists to create online polls on social media to understand the political leanings of people in specific locations. The caveat here is that only influential people can make such an online polling and reach out at a mass scale. Further, in such cases, the distribution of voters is not controllable and may be, in fact, biased. On the other hand,if we can interpret the publicly available data over social media to probe the political inclination of users, we will be able to have controllable insights about the survey population, keep the cost of survey low and also collect publicly available data without involving the concerned persons. Hence we introduce a self-attentive semi-supervised framework for political inclination detection to further that objective. The advantage of our model is that it neither needs huge training data nor does it need to store social network parameters. Nevertheless, it achieves an accuracy of 93.7\% with no annotated data; further, with only a few annotated examples per class it achieves competitive performance. We found that the model is highly efficient even in resource-constrained settings, and insights drawn from its predictions match the manual survey outcomes when applied to diverse real-life scenarios.
Decoding Demographic un-fairness from Indian Names
Sep 07, 2022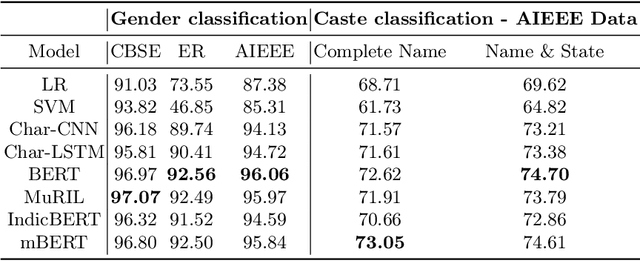
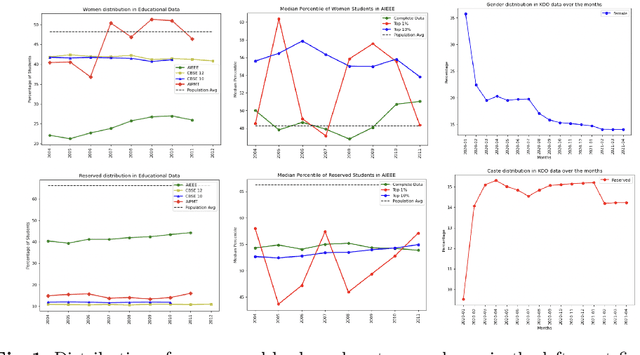
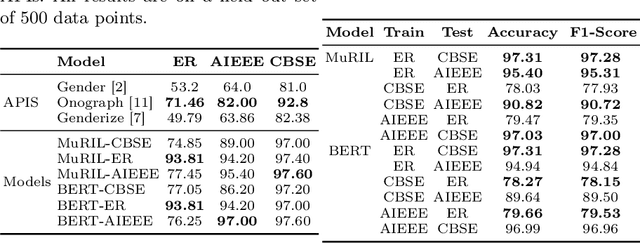
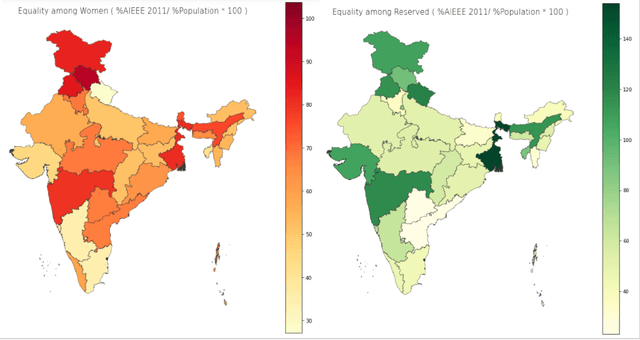
Demographic classification is essential in fairness assessment in recommender systems or in measuring unintended bias in online networks and voting systems. Important fields like education and politics, which often lay a foundation for the future of equality in society, need scrutiny to design policies that can better foster equality in resource distribution constrained by the unbalanced demographic distribution of people in the country. We collect three publicly available datasets to train state-of-the-art classifiers in the domain of gender and caste classification. We train the models in the Indian context, where the same name can have different styling conventions (Jolly Abraham/Kumar Abhishikta in one state may be written as Abraham Jolly/Abishikta Kumar in the other). Finally, we also perform cross-testing (training and testing on different datasets) to understand the efficacy of the above models. We also perform an error analysis of the prediction models. Finally, we attempt to assess the bias in the existing Indian system as case studies and find some intriguing patterns manifesting in the complex demographic layout of the sub-continent across the dimensions of gender and caste.
* Accepted to SocInfo'22; code hosted at https://github.com/vahini01/IndianDemographics
CRUSH: Contextually Regularized and User anchored Self-supervised Hate speech Detection
Apr 13, 2022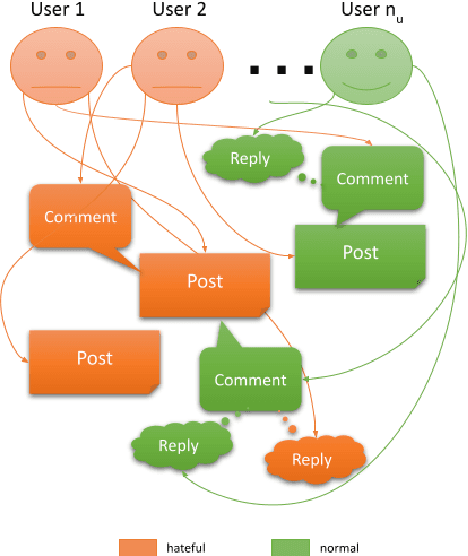
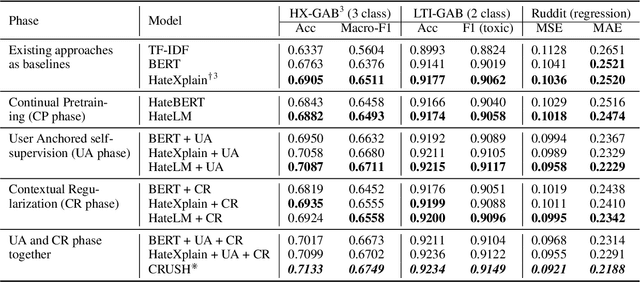
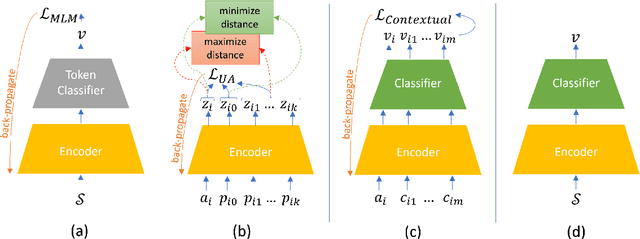
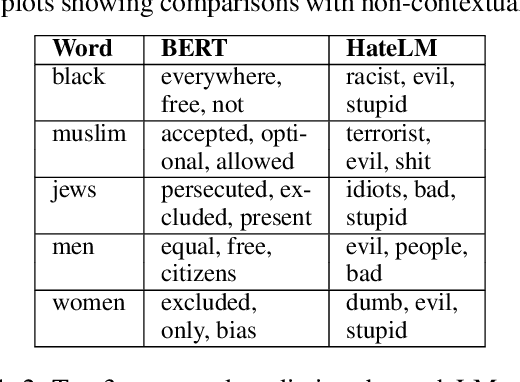
The last decade has witnessed a surge in the interaction of people through social networking platforms. While there are several positive aspects of these social platforms, the proliferation has led them to become the breeding ground for cyber-bullying and hate speech. Recent advances in NLP have often been used to mitigate the spread of such hateful content. Since the task of hate speech detection is usually applicable in the context of social networks, we introduce CRUSH, a framework for hate speech detection using user-anchored self-supervision and contextual regularization. Our proposed approach secures ~ 1-12% improvement in test set metrics over best performing previous approaches on two types of tasks and multiple popular english social media datasets.
Aspect-based Sentiment Analysis of Scientific Reviews
Jun 05, 2020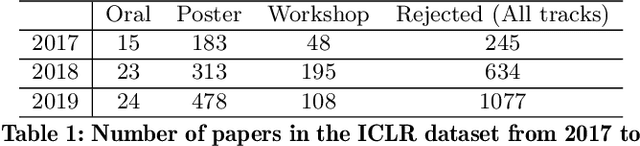

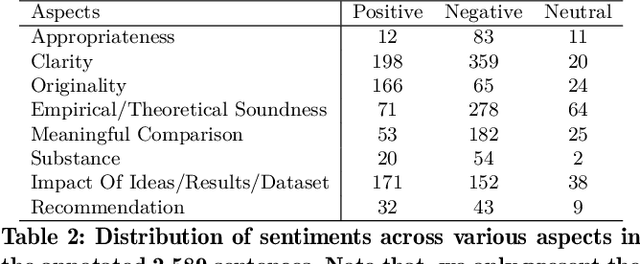
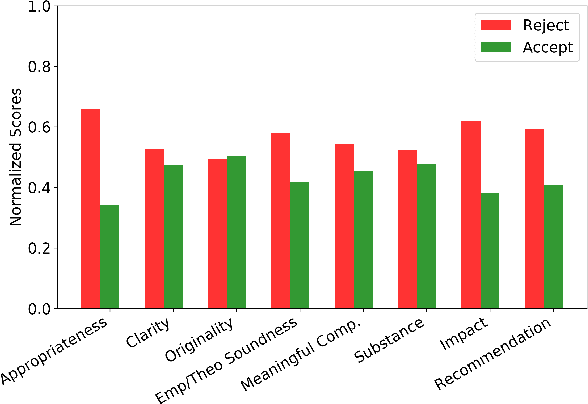
Scientific papers are complex and understanding the usefulness of these papers requires prior knowledge. Peer reviews are comments on a paper provided by designated experts on that field and hold a substantial amount of information, not only for the editors and chairs to make the final decision, but also to judge the potential impact of the paper. In this paper, we propose to use aspect-based sentiment analysis of scientific reviews to be able to extract useful information, which correlates well with the accept/reject decision. While working on a dataset of close to 8k reviews from ICLR, one of the top conferences in the field of machine learning, we use an active learning framework to build a training dataset for aspect prediction, which is further used to obtain the aspects and sentiments for the entire dataset. We show that the distribution of aspect-based sentiments obtained from a review is significantly different for accepted and rejected papers. We use the aspect sentiments from these reviews to make an intriguing observation, certain aspects present in a paper and discussed in the review strongly determine the final recommendation. As a second objective, we quantify the extent of disagreement among the reviewers refereeing a paper. We also investigate the extent of disagreement between the reviewers and the chair and find that the inter-reviewer disagreement may have a link to the disagreement with the chair. One of the most interesting observations from this study is that reviews, where the reviewer score and the aspect sentiments extracted from the review text written by the reviewer are consistent, are also more likely to be concurrent with the chair's decision.