 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrowdCounter: A benchmark type-specific multi-target counterspeech dataset
Oct 02, 2024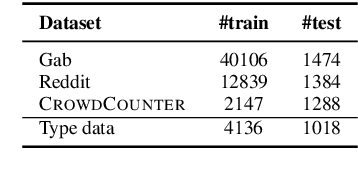


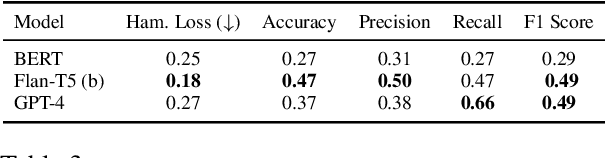
Counterspeech presents a viable alternative to banning or suspending users for hate speech while upholding freedom of expression. However, writing effective counterspeech is challenging for moderators/users. Hence, developing suggestion tools for writing counterspeech is the need of the hour. One critical challenge in developing such a tool is the lack of quality and diversity of the responses in the existing datasets. Hence, we introduce a new dataset - CrowdCounter containing 3,425 hate speech-counterspeech pairs spanning six different counterspeech types (empathy, humor, questioning, warning, shaming, contradiction), which is the first of its kind. The design of our annotation platform itself encourages annotators to write type-specific, non-redundant and high-quality counterspeech. We evaluate two frameworks for generating counterspeech responses - vanilla and type-controlled prompts - across four large language models. In terms of metrics, we evaluate the responses using relevance, diversity and quality. We observe that Flan-T5 is the best model in the vanilla framework across different models. Type-specific prompts enhance the relevance of the responses, although they might reduce the language quality. DialoGPT proves to be the best at following the instructions and generating the type-specific counterspeech accurately.
Personality Detection and Analysis using Twitter Data
Sep 11, 2023Personality types are important in various fields as they hold relevant information about the characteristics of a human being in an explainable format. They are often good predictors of a person's behaviors in a particular environment and have applications ranging from candidate selection to marketing and mental health. Recently automatic detection of personality traits from texts has gained significant attention in computational linguistics. Most personality detection and analysis methods have focused on small datasets making their experimental observations often limited. To bridge this gap, we focus on collecting and releasing the largest automatically curated dataset for the research community which has 152 million tweets and 56 thousand data points for the Myers-Briggs personality type (MBTI) prediction task. We perform a series of extensive qualitative and quantitative studies on our dataset to analyze the data patterns in a better way and infer conclusions. We show how our intriguing analysis results often follow natural intuition. We also perform a series of ablation studies to show how the baselines perform for our dataset.