 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrowdCounter: A benchmark type-specific multi-target counterspeech dataset
Oct 02, 2024


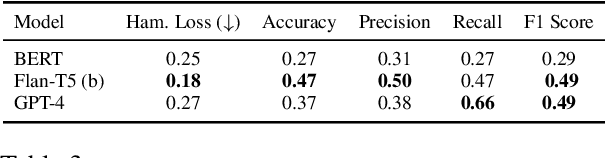
Counterspeech presents a viable alternative to banning or suspending users for hate speech while upholding freedom of expression. However, writing effective counterspeech is challenging for moderators/users. Hence, developing suggestion tools for writing counterspeech is the need of the hour. One critical challenge in developing such a tool is the lack of quality and diversity of the responses in the existing datasets. Hence, we introduce a new dataset - CrowdCounter containing 3,425 hate speech-counterspeech pairs spanning six different counterspeech types (empathy, humor, questioning, warning, shaming, contradiction), which is the first of its kind. The design of our annotation platform itself encourages annotators to write type-specific, non-redundant and high-quality counterspeech. We evaluate two frameworks for generating counterspeech responses - vanilla and type-controlled prompts - across four large language models. In terms of metrics, we evaluate the responses using relevance, diversity and quality. We observe that Flan-T5 is the best model in the vanilla framework across different models. Type-specific prompts enhance the relevance of the responses, although they might reduce the language quality. DialoGPT proves to be the best at following the instructions and generating the type-specific counterspeech accurately.
Demarked: A Strategy for Enhanced Abusive Speech Moderation through Counterspeech, Detoxification, and Message Management
Jun 27, 2024
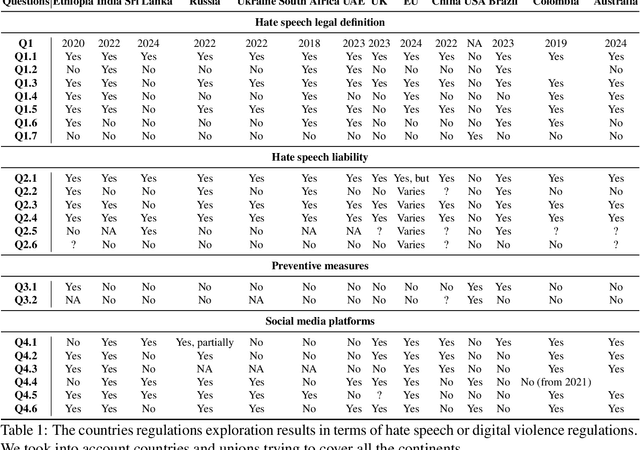
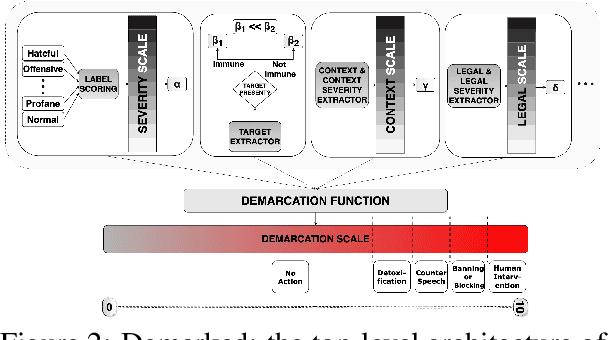

Despite regulations imposed by nations and social media platforms, such as recent EU regulations targeting digital violence, abusive content persists as a significant challenge. Existing approaches primarily rely on binary solutions, such as outright blocking or banning, yet fail to address the complex nature of abusive speech. In this work, we propose a more comprehensive approach called Demarcation scoring abusive speech based on four aspect -- (i) severity scale; (ii) presence of a target; (iii) context scale; (iv) legal scale -- and suggesting more options of actions like detoxification, counter speech generation, blocking, or, as a final measure, human intervention. Through a thorough analysis of abusive speech regulations across diverse jurisdictions, platforms, and research papers we highlight the gap in preventing measures and advocate for tailored proactive steps to combat its multifaceted manifestations. Our work aims to inform future strategies for effectively addressing abusive speech online.
On Zero-Shot Counterspeech Generation by LLMs
Mar 22, 2024With the emergence of numerous Large Language Models (LLM), the usage of such models in various Natural Language Processing (NLP) applications is increasing extensively. Counterspeech generation is one such key task where efforts are made to develop generative models by fine-tuning LLMs with hatespeech - counterspeech pairs, but none of these attempts explores the intrinsic properties of large language models in zero-shot settings. In this work, we present a comprehensive analysis of the performances of four LLMs namely GPT-2, DialoGPT, ChatGPT and FlanT5 in zero-shot settings for counterspeech generation, which is the first of its kind. For GPT-2 and DialoGPT, we further investigate the deviation in performance with respect to the sizes (small, medium, large) of the models. On the other hand, we propose three different prompting strategies for generating different types of counterspeech and analyse the impact of such strategies on the performance of the models. Our analysis shows that there is an improvement in generation quality for two datasets (17%), however the toxicity increase (25%) with increase in model size. Considering type of model, GPT-2 and FlanT5 models are significantly better in terms of counterspeech quality but also have high toxicity as compared to DialoGPT. ChatGPT are much better at generating counter speech than other models across all metrics. In terms of prompting, we find that our proposed strategies help in improving counter speech generation across all the models.
InfFeed: Influence Functions as a Feedback to Improve the Performance of Subjective Tasks
Mar 09, 2024Recently, influence functions present an apparatus for achieving explainability for deep neural models by quantifying the perturbation of individual train instances that might impact a test prediction. Our objectives in this paper are twofold. First we incorporate influence functions as a feedback into the model to improve its performance. Second, in a dataset extension exercise, using influence functions to automatically identify data points that have been initially `silver' annotated by some existing method and need to be cross-checked (and corrected) by annotators to improve the model performance. To meet these objectives, in this paper, we introduce InfFeed, which uses influence functions to compute the influential instances for a target instance. Toward the first objective, we adjust the label of the target instance based on its influencer(s) label. In doing this, InfFeed outperforms the state-of-the-art baselines (including LLMs) by a maximum macro F1-score margin of almost 4% for hate speech classification, 3.5% for stance classification, and 3% for irony and 2% for sarcasm detection. Toward the second objective we show that manually re-annotating only those silver annotated data points in the extension set that have a negative influence can immensely improve the model performance bringing it very close to the scenario where all the data points in the extension set have gold labels. This allows for huge reduction of the number of data points that need to be manually annotated since out of the silver annotated extension dataset, the influence function scheme picks up ~1/1000 points that need manual correction.
Zero shot VLMs for hate meme detection: Are we there yet?
Feb 19, 2024Multimedia content on social media is rapidly evolving, with memes gaining prominence as a distinctive form. Unfortunately, some malicious users exploit memes to target individuals or vulnerable communities, making it imperative to identify and address such instances of hateful memes. Extensive research has been conducted to address this issue by developing hate meme detection models. However, a notable limitation of traditional machine/deep learning models is the requirement for labeled datasets for accurate classification. Recently, the research community has witnessed the emergence of several visual language models that have exhibited outstanding performance across various tasks. In this study, we aim to investigate the efficacy of these visual language models in handling intricate tasks such as hate meme detection. We use various prompt settings to focus on zero-shot classification of hateful/harmful memes. Through our analysis, we observe that large VLMs are still vulnerable for zero-shot hate meme detection.
Low-Resource Counterspeech Generation for Indic Languages: The Case of Bengali and Hindi
Feb 11, 2024With the rise of online abuse, the NLP community has begun investigating the use of neural architectures to generate counterspeech that can "counter" the vicious tone of such abusive speech and dilute/ameliorate their rippling effect over the social network. However, most of the efforts so far have been primarily focused on English. To bridge the gap for low-resource languages such as Bengali and Hindi, we create a benchmark dataset of 5,062 abusive speech/counterspeech pairs, of which 2,460 pairs are in Bengali and 2,602 pairs are in Hindi. We implement several baseline models considering various interlingual transfer mechanisms with different configurations to generate suitable counterspeech to set up an effective benchmark. We observe that the monolingual setup yields the best performance. Further, using synthetic transfer, language models can generate counterspeech to some extent; specifically, we notice that transferability is better when languages belong to the same language family.
Probing LLMs for hate speech detection: strengths and vulnerabilities
Oct 28, 2023



Recently efforts have been made by social media platforms as well as researchers to detect hateful or toxic language using large language models. However, none of these works aim to use explanation, additional context and victim community information in the detection process. We utilise different prompt variation, input information and evaluate large language models in zero shot setting (without adding any in-context examples). We select three large language models (GPT-3.5, text-davinci and Flan-T5) and three datasets - HateXplain, implicit hate and ToxicSpans. We find that on average including the target information in the pipeline improves the model performance substantially (~20-30%) over the baseline across the datasets. There is also a considerable effect of adding the rationales/explanations into the pipeline (~10-20%) over the baseline across the datasets. In addition, we further provide a typology of the error cases where these large language models fail to (i) classify and (ii) explain the reason for the decisions they take. Such vulnerable points automatically constitute 'jailbreak' prompts for these models and industry scale safeguard techniques need to be developed to make the models robust against such prompts.
HateMM: A Multi-Modal Dataset for Hate Video Classification
May 06, 2023



Hate speech has become one of the most significant issues in modern society, having implications in both the online and the offline world. Due to this, hate speech research has recently gained a lot of traction. However, most of the work has primarily focused on text media with relatively little work on images and even lesser on videos. Thus, early stage automated video moderation techniques are needed to handle the videos that are being uploaded to keep the platform safe and healthy. With a view to detect and remove hateful content from the video sharing platforms, our work focuses on hate video detection using multi-modalities. To this end, we curate ~43 hours of videos from BitChute and manually annotate them as hate or non-hate, along with the frame spans which could explain the labelling decision. To collect the relevant videos we harnessed search keywords from hate lexicons. We observe various cues in images and audio of hateful videos. Further, we build deep learning multi-modal models to classify the hate videos and observe that using all the modalities of the videos improves the overall hate speech detection performance (accuracy=0.798, macro F1-score=0.790) by ~5.7% compared to the best uni-modal model in terms of macro F1 score. In summary, our work takes the first step toward understanding and modeling hateful videos on video hosting platforms such as BitChute.
On the rise of fear speech in online social media
Mar 18, 2023



Recently, social media platforms are heavily moderated to prevent the spread of online hate speech, which is usually fertile in toxic words and is directed toward an individual or a community. Owing to such heavy moderation, newer and more subtle techniques are being deployed. One of the most striking among these is fear speech. Fear speech, as the name suggests, attempts to incite fear about a target community. Although subtle, it might be highly effective, often pushing communities toward a physical conflict. Therefore, understanding their prevalence in social media is of paramount importance. This article presents a large-scale study to understand the prevalence of 400K fear speech and over 700K hate speech posts collected from Gab.com. Remarkably, users posting a large number of fear speech accrue more followers and occupy more central positions in social networks than users posting a large number of hate speech. They can also reach out to benign users more effectively than hate speech users through replies, reposts, and mentions. This connects to the fact that, unlike hate speech, fear speech has almost zero toxic content, making it look plausible. Moreover, while fear speech topics mostly portray a community as a perpetrator using a (fake) chain of argumentation, hate speech topics hurl direct multitarget insults, thus pointing to why general users could be more gullible to fear speech. Our findings transcend even to other platforms (Twitter and Facebook) and thus necessitate using sophisticated moderation policies and mass awareness to combat fear speech.
HateProof: Are Hateful Meme Detection Systems really Robust?
Feb 11, 2023Exploiting social media to spread hate has tremendously increased over the years. Lately, multi-modal hateful content such as memes has drawn relatively more traction than uni-modal content. Moreover, the availability of implicit content payloads makes them fairly challenging to be detected by existing hateful meme detection systems. In this paper, we present a use case study to analyze such systems' vulnerabilities against external adversarial attacks. We find that even very simple perturbations in uni-modal and multi-modal settings performed by humans with little knowledge about the model can make the existing detection models highly vulnerable. Empirically, we find a noticeable performance drop of as high as 10% in the macro-F1 score for certain attacks. As a remedy, we attempt to boost the model's robustness using contrastive learning as well as an adversarial training-based method - VILLA. Using an ensemble of the above two approaches, in two of our high resolution datasets, we are able to (re)gain back the performance to a large extent for certain attacks. We believe that ours is a first step toward addressing this crucial problem in an adversarial setting and would inspire more such investigations in the future.