 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarially Robust Neural Legal Judgement Systems
Jul 31, 2023Legal judgment prediction is the task of predicting the outcome of court cases on a given text description of facts of cases. These tasks apply Natural Language Processing (NLP) techniques to predict legal judgment results based on facts. Recently, large-scale public datasets and NLP models have increased research in areas related to legal judgment prediction systems. For such systems to be practically helpful, they should be robust from adversarial attacks. Previous works mainly focus on making a neural legal judgement system; however, significantly less or no attention has been given to creating a robust Legal Judgement Prediction(LJP) system. We implemented adversarial attacks on early existing LJP systems and found that none of them could handle attacks. In this work, we proposed an approach for making robust LJP systems. Extensive experiments on three legal datasets show significant improvements in our approach over the state-of-the-art LJP system in handling adversarial attacks. To the best of our knowledge, we are the first to increase the robustness of early-existing LJP systems.
HateMM: A Multi-Modal Dataset for Hate Video Classification
May 06, 2023



Hate speech has become one of the most significant issues in modern society, having implications in both the online and the offline world. Due to this, hate speech research has recently gained a lot of traction. However, most of the work has primarily focused on text media with relatively little work on images and even lesser on videos. Thus, early stage automated video moderation techniques are needed to handle the videos that are being uploaded to keep the platform safe and healthy. With a view to detect and remove hateful content from the video sharing platforms, our work focuses on hate video detection using multi-modalities. To this end, we curate ~43 hours of videos from BitChute and manually annotate them as hate or non-hate, along with the frame spans which could explain the labelling decision. To collect the relevant videos we harnessed search keywords from hate lexicons. We observe various cues in images and audio of hateful videos. Further, we build deep learning multi-modal models to classify the hate videos and observe that using all the modalities of the videos improves the overall hate speech detection performance (accuracy=0.798, macro F1-score=0.790) by ~5.7% compared to the best uni-modal model in terms of macro F1 score. In summary, our work takes the first step toward understanding and modeling hateful videos on video hosting platforms such as BitChute.
VizAI : Selecting Accurate Visualizations of Numerical Data
Nov 07, 2021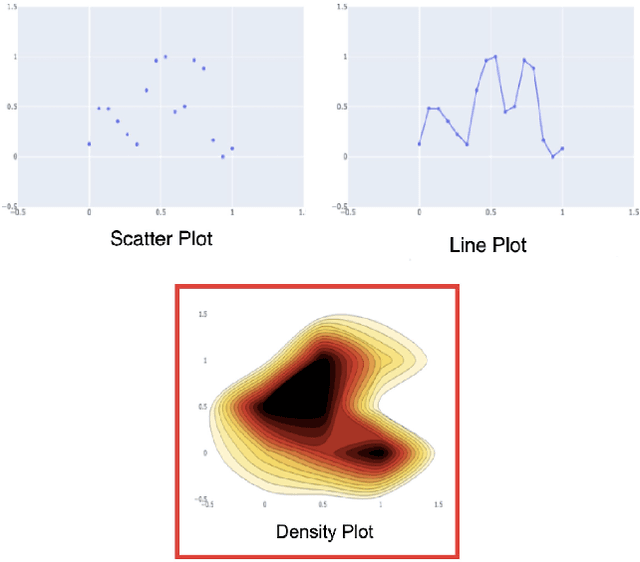
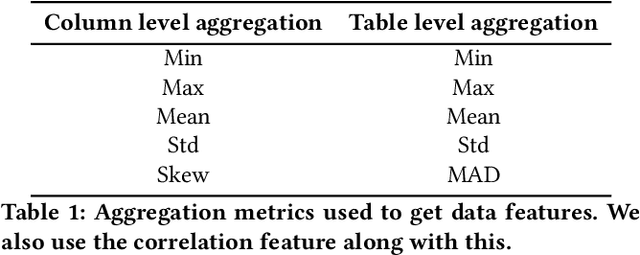
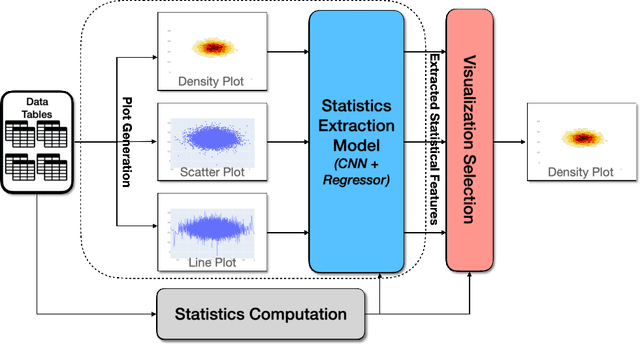

A good data visualization is not only a distortion-free graphical representation of data but also a way to reveal underlying statistical properties of the data. Despite its common use across various stages of data analysis, selecting a good visualization often is a manual process involving many iterations. Recently there has been interest in reducing this effort by developing models that can recommend visualizations, but they are of limited use since they require large training samples (data and visualization pairs) and focus primarily on the design aspects rather than on assessing the effectiveness of the selected visualization. In this paper, we present VizAI, a generative-discriminative framework that first generates various statistical properties of the data from a number of alternative visualizations of the data. It is linked to a discriminative model that selects the visualization that best matches the true statistics of the data being visualized. VizAI can easily be trained with minimal supervision and adapts to settings with varying degrees of supervision easily. Using crowd-sourced judgements and a large repository of publicly available visualizations, we demonstrate that VizAI outperforms the state of the art methods that learn to recommend visualizations.