 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero shot VLMs for hate meme detection: Are we there yet?
Feb 19, 2024Multimedia content on social media is rapidly evolving, with memes gaining prominence as a distinctive form. Unfortunately, some malicious users exploit memes to target individuals or vulnerable communities, making it imperative to identify and address such instances of hateful memes. Extensive research has been conducted to address this issue by developing hate meme detection models. However, a notable limitation of traditional machine/deep learning models is the requirement for labeled datasets for accurate classification. Recently, the research community has witnessed the emergence of several visual language models that have exhibited outstanding performance across various tasks. In this study, we aim to investigate the efficacy of these visual language models in handling intricate tasks such as hate meme detection. We use various prompt settings to focus on zero-shot classification of hateful/harmful memes. Through our analysis, we observe that large VLMs are still vulnerable for zero-shot hate meme detection.
Low-Resource Counterspeech Generation for Indic Languages: The Case of Bengali and Hindi
Feb 11, 2024With the rise of online abuse, the NLP community has begun investigating the use of neural architectures to generate counterspeech that can "counter" the vicious tone of such abusive speech and dilute/ameliorate their rippling effect over the social network. However, most of the efforts so far have been primarily focused on English. To bridge the gap for low-resource languages such as Bengali and Hindi, we create a benchmark dataset of 5,062 abusive speech/counterspeech pairs, of which 2,460 pairs are in Bengali and 2,602 pairs are in Hindi. We implement several baseline models considering various interlingual transfer mechanisms with different configurations to generate suitable counterspeech to set up an effective benchmark. We observe that the monolingual setup yields the best performance. Further, using synthetic transfer, language models can generate counterspeech to some extent; specifically, we notice that transferability is better when languages belong to the same language family.
BanglaAbuseMeme: A Dataset for Bengali Abusive Meme Classification
Oct 18, 2023



The dramatic increase in the use of social media platforms for information sharing has also fueled a steep growth in online abuse. A simple yet effective way of abusing individuals or communities is by creating memes, which often integrate an image with a short piece of text layered on top of it. Such harmful elements are in rampant use and are a threat to online safety. Hence it is necessary to develop efficient models to detect and flag abusive memes. The problem becomes more challenging in a low-resource setting (e.g., Bengali memes, i.e., images with Bengali text embedded on it) because of the absence of benchmark datasets on which AI models could be trained. In this paper we bridge this gap by building a Bengali meme dataset. To setup an effective benchmark we implement several baseline models for classifying abusive memes using this dataset. We observe that multimodal models that use both textual and visual information outperform unimodal models. Our best-performing model achieves a macro F1 score of 70.51. Finally, we perform a qualitative error analysis of the misclassified memes of the best-performing text-based, image-based and multimodal models.
Evaluating ChatGPT's Performance for Multilingual and Emoji-based Hate Speech Detection
May 23, 2023



Hate speech is a severe issue that affects many online platforms. So far, several studies have been performed to develop robust hate speech detection systems. Large language models like ChatGPT have recently shown a great promise in performing several tasks, including hate speech detection. However, it is crucial to comprehend the limitations of these models to build robust hate speech detection systems. To bridge this gap, our study aims to evaluate the strengths and weaknesses of the ChatGPT model in detecting hate speech at a granular level across 11 languages. Our evaluation employs a series of functionality tests that reveals various intricate failures of the model which the aggregate metrics like macro F1 or accuracy are not able to unfold. In addition, we investigate the influence of complex emotions, such as the use of emojis in hate speech, on the performance of the ChatGPT model. Our analysis highlights the shortcomings of the generative models in detecting certain types of hate speech and highlighting the need for further research and improvements in the workings of these models.
HateMM: A Multi-Modal Dataset for Hate Video Classification
May 06, 2023



Hate speech has become one of the most significant issues in modern society, having implications in both the online and the offline world. Due to this, hate speech research has recently gained a lot of traction. However, most of the work has primarily focused on text media with relatively little work on images and even lesser on videos. Thus, early stage automated video moderation techniques are needed to handle the videos that are being uploaded to keep the platform safe and healthy. With a view to detect and remove hateful content from the video sharing platforms, our work focuses on hate video detection using multi-modalities. To this end, we curate ~43 hours of videos from BitChute and manually annotate them as hate or non-hate, along with the frame spans which could explain the labelling decision. To collect the relevant videos we harnessed search keywords from hate lexicons. We observe various cues in images and audio of hateful videos. Further, we build deep learning multi-modal models to classify the hate videos and observe that using all the modalities of the videos improves the overall hate speech detection performance (accuracy=0.798, macro F1-score=0.790) by ~5.7% compared to the best uni-modal model in terms of macro F1 score. In summary, our work takes the first step toward understanding and modeling hateful videos on video hosting platforms such as BitChute.
HateProof: Are Hateful Meme Detection Systems really Robust?
Feb 11, 2023Exploiting social media to spread hate has tremendously increased over the years. Lately, multi-modal hateful content such as memes has drawn relatively more traction than uni-modal content. Moreover, the availability of implicit content payloads makes them fairly challenging to be detected by existing hateful meme detection systems. In this paper, we present a use case study to analyze such systems' vulnerabilities against external adversarial attacks. We find that even very simple perturbations in uni-modal and multi-modal settings performed by humans with little knowledge about the model can make the existing detection models highly vulnerable. Empirically, we find a noticeable performance drop of as high as 10% in the macro-F1 score for certain attacks. As a remedy, we attempt to boost the model's robustness using contrastive learning as well as an adversarial training-based method - VILLA. Using an ensemble of the above two approaches, in two of our high resolution datasets, we are able to (re)gain back the performance to a large extent for certain attacks. We believe that ours is a first step toward addressing this crucial problem in an adversarial setting and would inspire more such investigations in the future.
Hate Speech and Offensive Language Detection in Bengali
Oct 07, 2022



Social media often serves as a breeding ground for various hateful and offensive content. Identifying such content on social media is crucial due to its impact on the race, gender, or religion in an unprejudiced society. However, while there is extensive research in hate speech detection in English, there is a gap in hateful content detection in low-resource languages like Bengali. Besides, a current trend on social media is the use of Romanized Bengali for regular interactions. To overcome the existing research's limitations, in this study, we develop an annotated dataset of 10K Bengali posts consisting of 5K actual and 5K Romanized Bengali tweets. We implement several baseline models for the classification of such hateful posts. We further explore the interlingual transfer mechanism to boost classification performance. Finally, we perform an in-depth error analysis by looking into the misclassified posts by the models. While training actual and Romanized datasets separately, we observe that XLM-Roberta performs the best. Further, we witness that on joint training and few-shot training, MuRIL outperforms other models by interpreting the semantic expressions better. We make our code and dataset public for others.
Which one is more toxic? Findings from Jigsaw Rate Severity of Toxic Comments
Jun 27, 2022
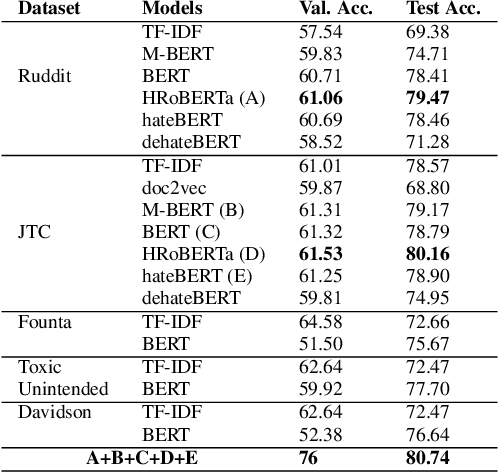
The proliferation of online hate speech has necessitated the creation of algorithms which can detect toxicity. Most of the past research focuses on this detection as a classification task, but assigning an absolute toxicity label is often tricky. Hence, few of the past works transform the same task into a regression. This paper shows the comparative evaluation of different transformers and traditional machine learning models on a recently released toxicity severity measurement dataset by Jigsaw. We further demonstrate the issues with the model predictions using explainability analysis.
HateCheckHIn: Evaluating Hindi Hate Speech Detection Models
Apr 30, 2022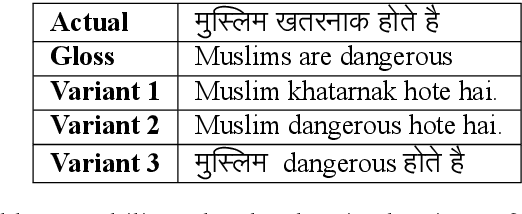
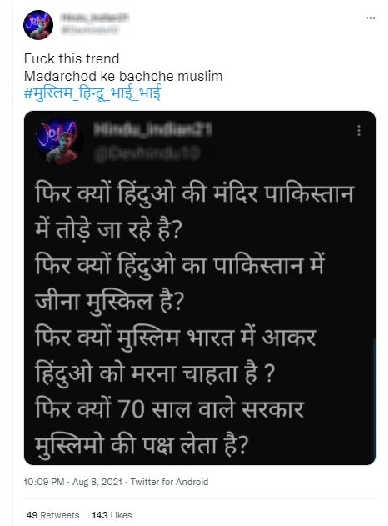

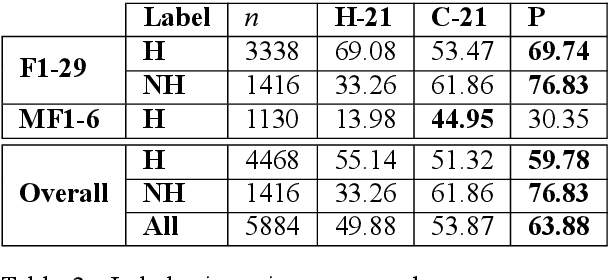
Due to the sheer volume of online hate, the AI and NLP communities have started building models to detect such hateful content. Recently, multilingual hate is a major emerging challenge for automated detection where code-mixing or more than one language have been used for conversation in social media. Typically, hate speech detection models are evaluated by measuring their performance on the held-out test data using metrics such as accuracy and F1-score. While these metrics are useful, it becomes difficult to identify using them where the model is failing, and how to resolve it. To enable more targeted diagnostic insights of such multilingual hate speech models, we introduce a set of functionalities for the purpose of evaluation. We have been inspired to design this kind of functionalities based on real-world conversation on social media. Considering Hindi as a base language, we craft test cases for each functionality. We name our evaluation dataset HateCheckHIn. To illustrate the utility of these functionalities , we test state-of-the-art transformer based m-BERT model and the Perspective API.
Data Bootstrapping Approaches to Improve Low Resource Abusive Language Detection for Indic Languages
Apr 26, 2022


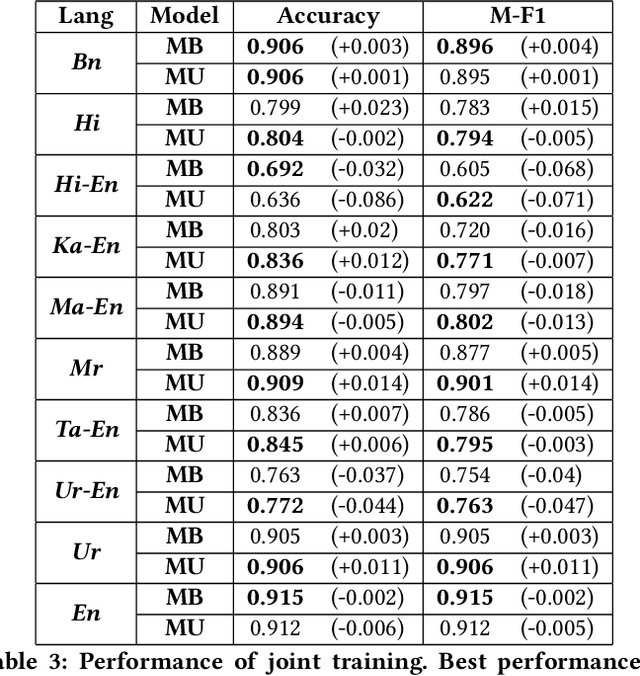
Abusive language is a growing concern in many social media platforms. Repeated exposure to abusive speech has created physiological effects on the target users. Thus, the problem of abusive language should be addressed in all forms for online peace and safety. While extensive research exists in abusive speech detection, most studies focus on English. Recently, many smearing incidents have occurred in India, which provoked diverse forms of abusive speech in online space in various languages based on the geographic location. Therefore it is essential to deal with such malicious content. In this paper, to bridge the gap, we demonstrate a large-scale analysis of multilingual abusive speech in Indic languages. We examine different interlingual transfer mechanisms and observe the performance of various multilingual models for abusive speech detection for eight different Indic languages. We also experiment to show how robust these models are on adversarial attacks. Finally, we conduct an in-depth error analysis by looking into the models' misclassified posts across various settings. We have made our code and models public for other researchers.