 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSee, Explain, and Intervene: A Few-Shot Multimodal Agent Framework for Hateful Meme Moderation
Jan 08, 2026In this work, we examine hateful memes from three complementary angles - how to detect them, how to explain their content and how to intervene them prior to being posted - by applying a range of strategies built on top of generative AI models. To the best of our knowledge, explanation and intervention have typically been studied separately from detection, which does not reflect real-world conditions. Further, since curating large annotated datasets for meme moderation is prohibitively expensive, we propose a novel framework that leverages task-specific generative multimodal agents and the few-shot adaptability of large multimodal models to cater to different types of memes. We believe this is the first work focused on generalizable hateful meme moderation under limited data conditions, and has strong potential for deployment in real-world production scenarios. Warning: Contains potentially toxic contents.
ToxicTAGS: Decoding Toxic Memes with Rich Tag Annotations
Aug 06, 2025



The 2025 Global Risks Report identifies state-based armed conflict and societal polarisation among the most pressing global threats, with social media playing a central role in amplifying toxic discourse. Memes, as a widely used mode of online communication, often serve as vehicles for spreading harmful content. However, limitations in data accessibility and the high cost of dataset curation hinder the development of robust meme moderation systems. To address this challenge, in this work, we introduce a first-of-its-kind dataset of 6,300 real-world meme-based posts annotated in two stages: (i) binary classification into toxic and normal, and (ii) fine-grained labelling of toxic memes as hateful, dangerous, or offensive. A key feature of this dataset is that it is enriched with auxiliary metadata of socially relevant tags, enhancing the context of each meme. In addition, we propose a tag generation module that produces socially grounded tags, because most in-the-wild memes often do not come with tags. Experimental results show that incorporating these tags substantially enhances the performance of state-of-the-art VLMs detection tasks. Our contributions offer a novel and scalable foundation for improved content moderation in multimodal online environments.
NLP for Social Good: A Survey of Challenges, Opportunities, and Responsible Deployment
May 28, 2025



Recent advancements in large language models (LLMs) have unlocked unprecedented possibilities across a range of applications. However, as a community, we believe that the field of Natural Language Processing (NLP) has a growing need to approach deployment with greater intentionality and responsibility. In alignment with the broader vision of AI for Social Good (Toma\v{s}ev et al., 2020), this paper examines the role of NLP in addressing pressing societal challenges. Through a cross-disciplinary analysis of social goals and emerging risks, we highlight promising research directions and outline challenges that must be addressed to ensure responsible and equitable progress in NLP4SG research.
Multilingual and Explainable Text Detoxification with Parallel Corpora
Dec 16, 2024Even with various regulations in place across countries and social media platforms (Government of India, 2021; European Parliament and Council of the European Union, 2022, digital abusive speech remains a significant issue. One potential approach to address this challenge is automatic text detoxification, a text style transfer (TST) approach that transforms toxic language into a more neutral or non-toxic form. To date, the availability of parallel corpora for the text detoxification task (Logachevavet al., 2022; Atwell et al., 2022; Dementievavet al., 2024a) has proven to be crucial for state-of-the-art approaches. With this work, we extend parallel text detoxification corpus to new languages -- German, Chinese, Arabic, Hindi, and Amharic -- testing in the extensive multilingual setup TST baselines. Next, we conduct the first of its kind an automated, explainable analysis of the descriptive features of both toxic and non-toxic sentences, diving deeply into the nuances, similarities, and differences of toxicity and detoxification across 9 languages. Finally, based on the obtained insights, we experiment with a novel text detoxification method inspired by the Chain-of-Thoughts reasoning approach, enhancing the prompting process through clustering on relevant descriptive attributes.
Demarked: A Strategy for Enhanced Abusive Speech Moderation through Counterspeech, Detoxification, and Message Management
Jun 27, 2024
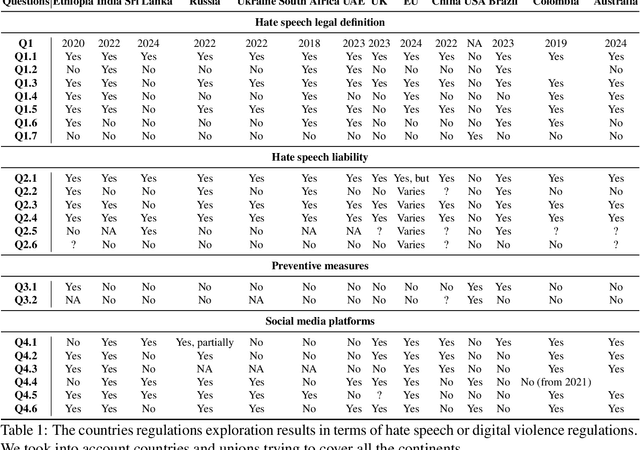
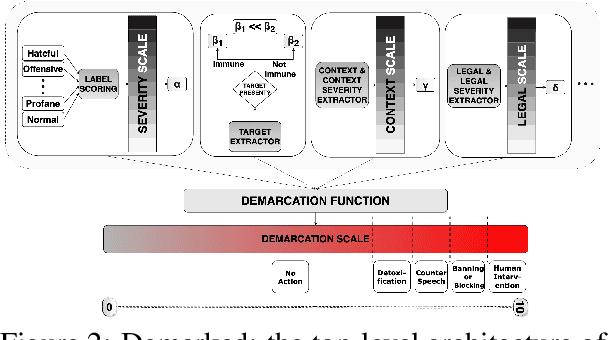

Despite regulations imposed by nations and social media platforms, such as recent EU regulations targeting digital violence, abusive content persists as a significant challenge. Existing approaches primarily rely on binary solutions, such as outright blocking or banning, yet fail to address the complex nature of abusive speech. In this work, we propose a more comprehensive approach called Demarcation scoring abusive speech based on four aspect -- (i) severity scale; (ii) presence of a target; (iii) context scale; (iv) legal scale -- and suggesting more options of actions like detoxification, counter speech generation, blocking, or, as a final measure, human intervention. Through a thorough analysis of abusive speech regulations across diverse jurisdictions, platforms, and research papers we highlight the gap in preventing measures and advocate for tailored proactive steps to combat its multifaceted manifestations. Our work aims to inform future strategies for effectively addressing abusive speech online.
Zero shot VLMs for hate meme detection: Are we there yet?
Feb 19, 2024Multimedia content on social media is rapidly evolving, with memes gaining prominence as a distinctive form. Unfortunately, some malicious users exploit memes to target individuals or vulnerable communities, making it imperative to identify and address such instances of hateful memes. Extensive research has been conducted to address this issue by developing hate meme detection models. However, a notable limitation of traditional machine/deep learning models is the requirement for labeled datasets for accurate classification. Recently, the research community has witnessed the emergence of several visual language models that have exhibited outstanding performance across various tasks. In this study, we aim to investigate the efficacy of these visual language models in handling intricate tasks such as hate meme detection. We use various prompt settings to focus on zero-shot classification of hateful/harmful memes. Through our analysis, we observe that large VLMs are still vulnerable for zero-shot hate meme detection.