 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARBOR: Online Process Rewards via a Reusable Rubric Buffer for Search Agents
Jun 02, 2026LLM-based search agents are trained predominantly with outcome-only reward, leaving the search process itself unsupervised. This signal degenerates on outcome-homogeneous groups where all sampled trajectories share the same correctness, yielding zero within-group advantage and no gradient. Existing process supervision either trains a costly verifier or generates per-query rubrics that are inconsistent across queries and discarded after one use. We propose ARBOR (Adaptive Rubric Buffer for Online Reward), a reusable process-reward framework that maintains a rubric memory shared across queries. Query-local drafts induced from contrastive trajectories are admitted, consolidated into cross-query common rubrics, and retired as the policy evolves. A small active subset of common rubrics scores trajectories via sparse pairwise judging, and the resulting scores are added to the base reward, providing process-level gradient even when outcome reward is uniform. ARBOR consistently outperforms GRPO and DAPO baselines on four multi-hop QA benchmarks, raising average LLM-judge accuracy by up to 4.2 points and converting up to 42% of otherwise-zero-gradient training groups into informative ones.
Demystifying Multimodal Biomolecular Co-design With Intrinsic Geodesic Coupling
Jun 01, 2026Biomolecules such as proteins and small-molecule ligands play a central role in biological systems, arising from the tight interplay between sequence and three-dimensional structure. Recent generative models for biomolecular co-design aim to capture this interplay by jointly modeling coupled modalities. However, existing approaches largely adopt a parallel execution of marginal generative processes, implicitly enforcing fixed synchronous coupling. We argue that a critical but overlooked degree of freedom lies in how these marginal processes are temporally coupled during training and generation, where inappropriate coupling can introduce high-variance supervision and inconsistent intermediate states, affecting modality consistency. To address this, we introduce GeoCoupling, a systematic framework that optimizes for temporal couplings between heterogeneous modalities. Empirical results across structure-based drug design and unconditional protein design demonstrate the learned couplings consistently outperform synchronous and randomly coupled baselines, yielding biomolecules with improved physical validity and diversity.
IndustryBench: Probing the Industrial Knowledge Boundaries of LLMs
May 11, 2026In industrial procurement, an LLM answer is useful only if it survives a standards check: recommended material must match operating condition, every parameter must respect a regulated threshold, and no procedure may contradict a safety clause. Partial correctness can mask safety-critical contradictions that aggregate LLM benchmarks rarely capture. We introduce IndustryBench, a 2,049-item benchmark for industrial procurement QA in Chinese, grounded in Chinese national standards (GB/T) and structured industrial product records, organized by seven capability dimensions, ten industry categories, and panel-derived difficulty tiers, with item-aligned English, Russian, and Vietnamese renderings. Our construction pipeline rejects 70.3% of LLM-generated candidates at a search-based external-verification stage, calibrating how unreliable industrial QA remains after LLM-only filtering.Our evaluation decouples raw correctness, scored by a Qwen3-Max judge validated at $κ_w = 0.798$ against a domain expert, from a separate safety-violation (SV) check against source texts. Across 17 models in Chinese and an 8-model intersection over four languages, we find: (i) the best system reaches only 2.083 on the 0--3 rubric, leaving substantial headroom; (ii) Standards & Terminology is the most persistent capability weakness and survives item-aligned translation; (iii) extended reasoning lowers safety-adjusted scores for 12 of 13 models, primarily by introducing unsupported safety-critical details into longer final answers; and (iv) safety-violation rates reshuffle the leaderboard -- GPT-5.4 climbs from rank 6 to rank 3 after SV adjustment, while Kimi-k2.5-1T-A32B drops seven positions.Industrial LLM evaluation therefore requires source-grounded, safety-aware diagnosis rather than aggregate accuracy. We release IndustryBench with all prompts, scoring scripts, and dataset documentation.
A Multimodal Dataset for Visually Grounded Ambiguity in Machine Translation
May 03, 2026Ambiguity resolution is a key challenge in multimodal machine translation (MMT), where models must genuinely leverage visual input to map an ambiguous expression to its intended meaning. Although prior work has proposed disambiguation-oriented benchmarks that provide supportive evidence for the role of vision, we observe substantial issues in data quality and a mismatch with translation scenarios. Moreover, existing ambiguity-oriented evaluations are not well suited to broader ambiguity types in open-ended translation. To address these limitations, we present VIDA (Visually-Dependent Ambiguity), a dataset of 2,500 carefully curated instances in which resolving an annotated ambiguous source span requires visual evidence. We further propose Disambiguation-Centric Metrics that use an LLM-as-a-judge classifier to verify whether annotated ambiguous expressions are resolved correctly at the span level. Experiments with two state-of-the-art Large Vision Language Models under vanilla inference, supervised fine-tuning (SFT), and our chain-of-thought SFT (CoT-SFT) show that while SFT improves overall translation quality, CoT-SFT yields more consistent gains in disambiguation accuracy, especially on out-of-distribution subsets, indicating a stronger generalization for resolving diverse ambiguity types.
SemEval-2026 Task 9: Detecting Multilingual, Multicultural and Multievent Online Polarization
Apr 08, 2026We present SemEval-2026 Task 9, a shared task on online polarization detection, covering 22 languages and comprising over 110K annotated instances. Each data instance is multi-labeled with the presence of polarization, polarization type, and polarization manifestation. Participants were asked to predict labels in three sub-tasks: (1) detecting the presence of polarization, (2) identifying the type of polarization, and (3) recognizing the polarization manifestation. The three tasks attracted over 1,000 participants worldwide and more than 10k submission on Codabench. We received final submissions from 67 teams and 73 system description papers. We report the baseline results and analyze the performance of the best-performing systems, highlighting the most common approaches and the most effective methods across different subtasks and languages. The dataset of this task is publicly available.
Rethinking Multilingual Vision-Language Translation: Dataset, Evaluation, and Adaptation
Jun 13, 2025Vision-Language Translation (VLT) is a challenging task that requires accurately recognizing multilingual text embedded in images and translating it into the target language with the support of visual context. While recent Large Vision-Language Models (LVLMs) have demonstrated strong multilingual and visual understanding capabilities, there is a lack of systematic evaluation and understanding of their performance on VLT. In this work, we present a comprehensive study of VLT from three key perspectives: data quality, model architecture, and evaluation metrics. (1) We identify critical limitations in existing datasets, particularly in semantic and cultural fidelity, and introduce AibTrans -- a multilingual, parallel, human-verified dataset with OCR-corrected annotations. (2) We benchmark 11 commercial LVLMs/LLMs and 6 state-of-the-art open-source models across end-to-end and cascaded architectures, revealing their OCR dependency and contrasting generation versus reasoning behaviors. (3) We propose Density-Aware Evaluation to address metric reliability issues under varying contextual complexity, introducing the DA Score as a more robust measure of translation quality. Building upon these findings, we establish a new evaluation benchmark for VLT. Notably, we observe that fine-tuning LVLMs on high-resource language pairs degrades cross-lingual performance, and we propose a balanced multilingual fine-tuning strategy that effectively adapts LVLMs to VLT without sacrificing their generalization ability.
Prosody-Adaptable Audio Codecs for Zero-Shot Voice Conversion via In-Context Learning
May 21, 2025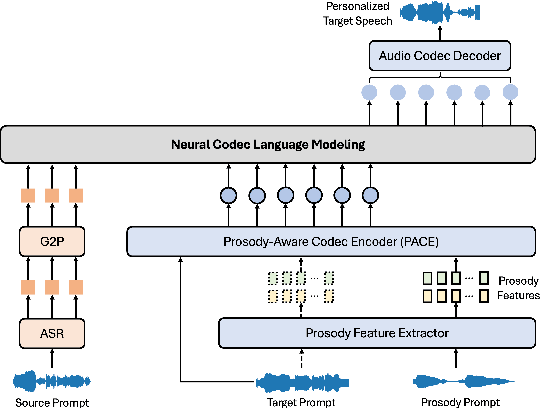

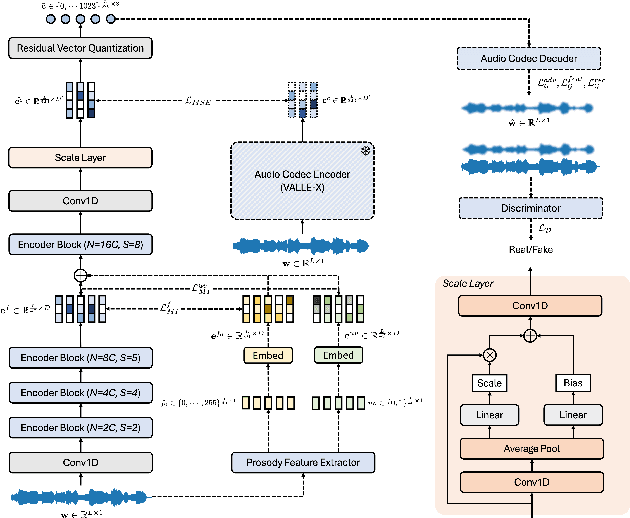
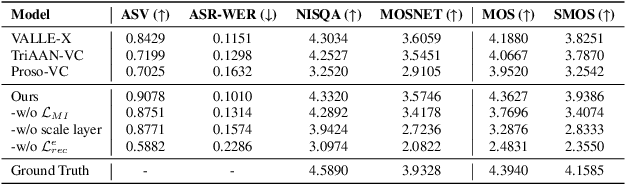
Recent advances in discrete audio codecs have significantly improved speech representation modeling, while codec language models have enabled in-context learning for zero-shot speech synthesis. Inspired by this, we propose a voice conversion (VC) model within the VALLE-X framework, leveraging its strong in-context learning capabilities for speaker adaptation. To enhance prosody control, we introduce a prosody-aware audio codec encoder (PACE) module, which isolates and refines prosody from other sources, improving expressiveness and control. By integrating PACE into our VC model, we achieve greater flexibility in prosody manipulation while preserving speaker timbre. Experimental evaluation results demonstrate that our approach outperforms baseline VC systems in prosody preservation, timbre consistency, and overall naturalness, surpassing baseline VC systems.
Chinese Toxic Language Mitigation via Sentiment Polarity Consistent Rewrites
May 21, 2025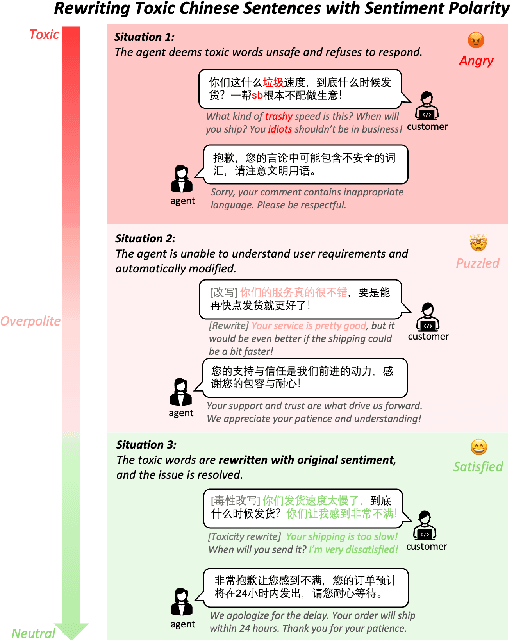
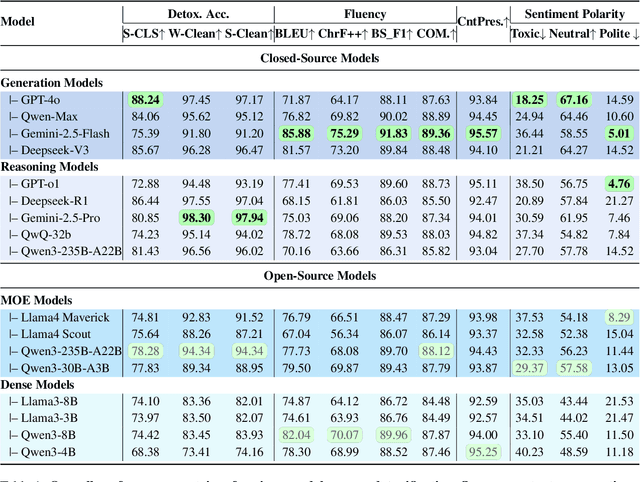
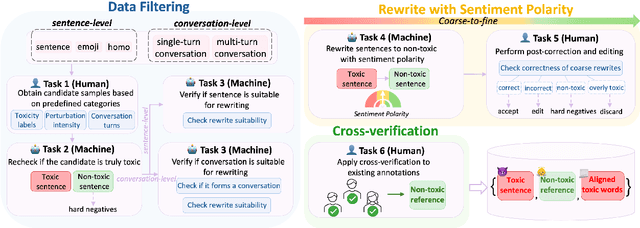
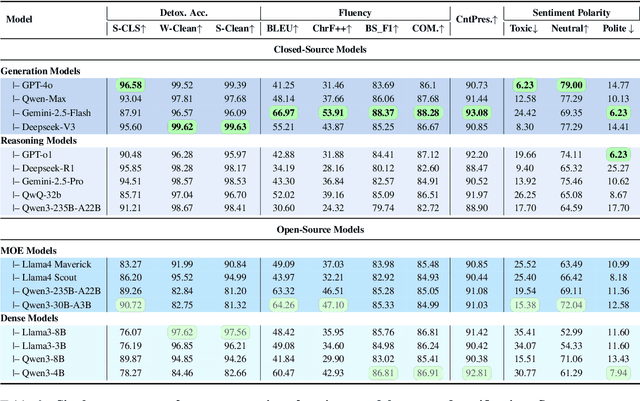
Detoxifying offensive language while preserving the speaker's original intent is a challenging yet critical goal for improving the quality of online interactions. Although large language models (LLMs) show promise in rewriting toxic content, they often default to overly polite rewrites, distorting the emotional tone and communicative intent. This problem is especially acute in Chinese, where toxicity often arises implicitly through emojis, homophones, or discourse context. We present ToxiRewriteCN, the first Chinese detoxification dataset explicitly designed to preserve sentiment polarity. The dataset comprises 1,556 carefully annotated triplets, each containing a toxic sentence, a sentiment-aligned non-toxic rewrite, and labeled toxic spans. It covers five real-world scenarios: standard expressions, emoji-induced and homophonic toxicity, as well as single-turn and multi-turn dialogues. We evaluate 17 LLMs, including commercial and open-source models with variant architectures, across four dimensions: detoxification accuracy, fluency, content preservation, and sentiment polarity. Results show that while commercial and MoE models perform best overall, all models struggle to balance safety with emotional fidelity in more subtle or context-heavy settings such as emoji, homophone, and dialogue-based inputs. We release ToxiRewriteCN to support future research on controllable, sentiment-aware detoxification for Chinese.
Perception, Reason, Think, and Plan: A Survey on Large Multimodal Reasoning Models
May 08, 2025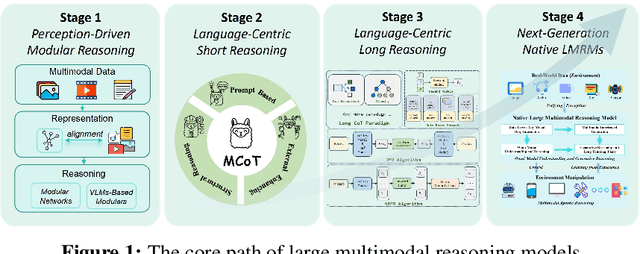
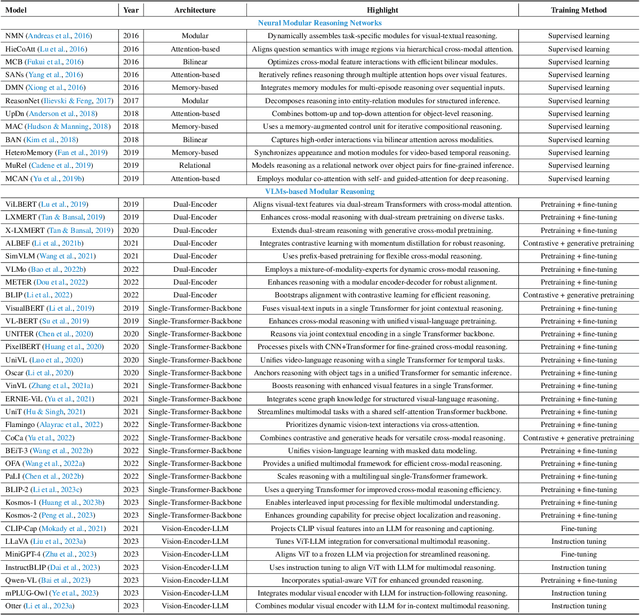
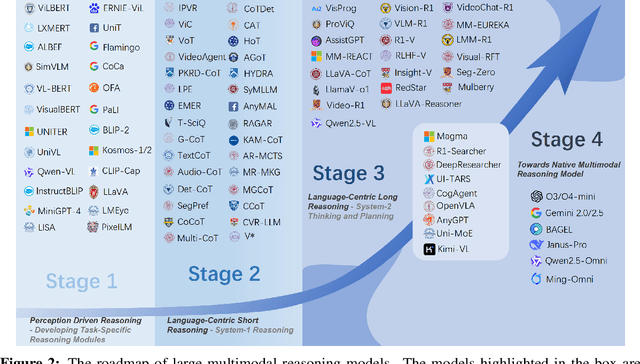
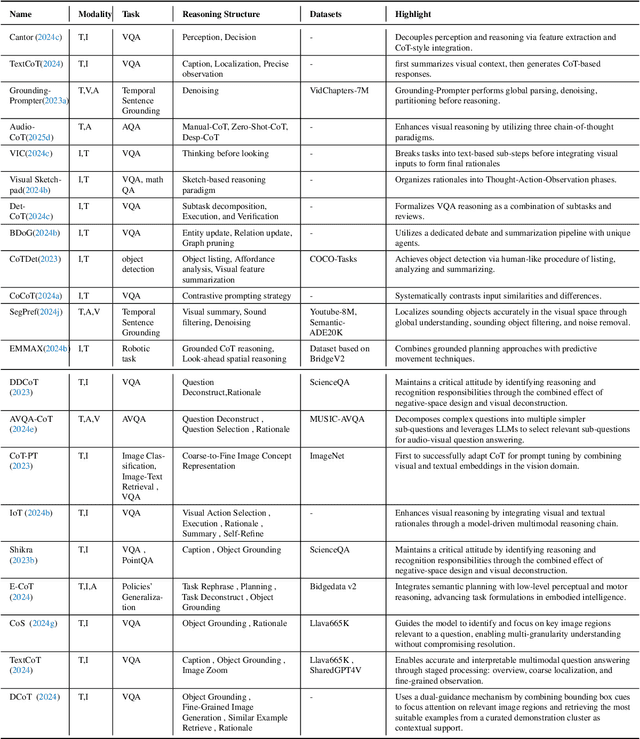
Reasoning lies at the heart of intelligence, shaping the ability to make decisions, draw conclusions, and generalize across domains. In artificial intelligence, as systems increasingly operate in open, uncertain, and multimodal environments, reasoning becomes essential for enabling robust and adaptive behavior. Large Multimodal Reasoning Models (LMRMs) have emerged as a promising paradigm, integrating modalities such as text, images, audio, and video to support complex reasoning capabilities and aiming to achieve comprehensive perception, precise understanding, and deep reasoning. As research advances, multimodal reasoning has rapidly evolved from modular, perception-driven pipelines to unified, language-centric frameworks that offer more coherent cross-modal understanding. While instruction tuning and reinforcement learning have improved model reasoning, significant challenges remain in omni-modal generalization, reasoning depth, and agentic behavior. To address these issues, we present a comprehensive and structured survey of multimodal reasoning research, organized around a four-stage developmental roadmap that reflects the field's shifting design philosophies and emerging capabilities. First, we review early efforts based on task-specific modules, where reasoning was implicitly embedded across stages of representation, alignment, and fusion. Next, we examine recent approaches that unify reasoning into multimodal LLMs, with advances such as Multimodal Chain-of-Thought (MCoT) and multimodal reinforcement learning enabling richer and more structured reasoning chains. Finally, drawing on empirical insights from challenging benchmarks and experimental cases of OpenAI O3 and O4-mini, we discuss the conceptual direction of native large multimodal reasoning models (N-LMRMs), which aim to support scalable, agentic, and adaptive reasoning and planning in complex, real-world environments.
The Bitter Lesson Learned from 2,000+ Multilingual Benchmarks
Apr 22, 2025



As large language models (LLMs) continue to advance in linguistic capabilities, robust multilingual evaluation has become essential for promoting equitable technological progress. This position paper examines over 2,000 multilingual (non-English) benchmarks from 148 countries, published between 2021 and 2024, to evaluate past, present, and future practices in multilingual benchmarking. Our findings reveal that, despite significant investments amounting to tens of millions of dollars, English remains significantly overrepresented in these benchmarks. Additionally, most benchmarks rely on original language content rather than translations, with the majority sourced from high-resource countries such as China, India, Germany, the UK, and the USA. Furthermore, a comparison of benchmark performance with human judgments highlights notable disparities. STEM-related tasks exhibit strong correlations with human evaluations (0.70 to 0.85), while traditional NLP tasks like question answering (e.g., XQuAD) show much weaker correlations (0.11 to 0.30). Moreover, translating English benchmarks into other languages proves insufficient, as localized benchmarks demonstrate significantly higher alignment with local human judgments (0.68) than their translated counterparts (0.47). This underscores the importance of creating culturally and linguistically tailored benchmarks rather than relying solely on translations. Through this comprehensive analysis, we highlight six key limitations in current multilingual evaluation practices, propose the guiding principles accordingly for effective multilingual benchmarking, and outline five critical research directions to drive progress in the field. Finally, we call for a global collaborative effort to develop human-aligned benchmarks that prioritize real-world applications.