 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRespecting Temporal-Causal Consistency: Entity-Event Knowledge Graphs for Retrieval-Augmented Generation
Jun 06, 2025

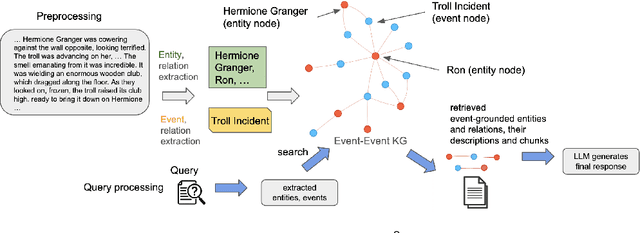
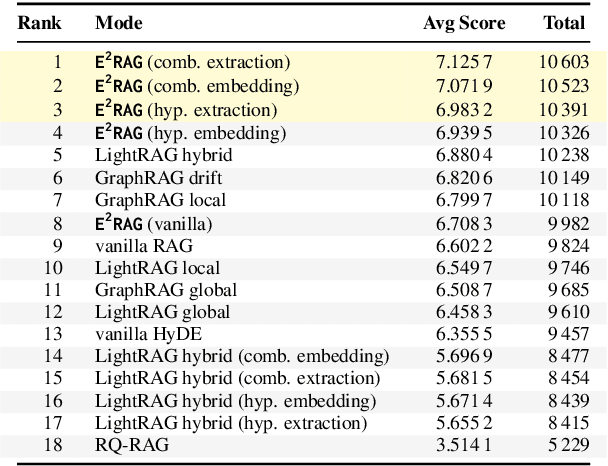
Retrieval-augmented generation (RAG) based on large language models often falters on narrative documents with inherent temporal structures. Standard unstructured RAG methods rely solely on embedding-similarity matching and lack any general mechanism to encode or exploit chronological information, while knowledge graph RAG (KG-RAG) frameworks collapse every mention of an entity into a single node, erasing the evolving context that drives many queries. To formalize this challenge and draw the community's attention, we construct ChronoQA, a robust and discriminative QA benchmark that measures temporal, causal, and character consistency understanding in narrative documents (e.g., novels) under the RAG setting. We then introduce Entity-Event RAG (E^2RAG), a dual-graph framework that keeps separate entity and event subgraphs linked by a bipartite mapping, thereby preserving the temporal and causal facets needed for fine-grained reasoning. Across ChronoQA, our approach outperforms state-of-the-art unstructured and KG-based RAG baselines, with notable gains on causal and character consistency queries. E^2RAG therefore offers a practical path to more context-aware retrieval for tasks that require precise answers grounded in chronological information.
VerIPO: Cultivating Long Reasoning in Video-LLMs via Verifier-Gudied Iterative Policy Optimization
May 25, 2025
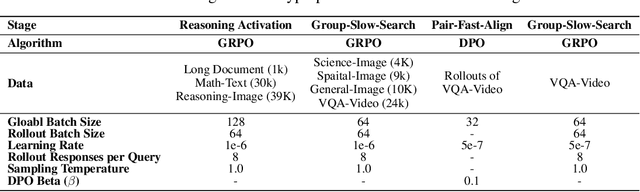

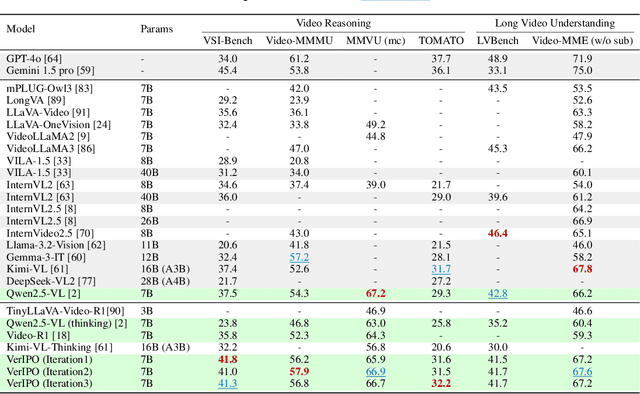
Applying Reinforcement Learning (RL) to Video Large Language Models (Video-LLMs) shows significant promise for complex video reasoning. However, popular Reinforcement Fine-Tuning (RFT) methods, such as outcome-based Group Relative Policy Optimization (GRPO), are limited by data preparation bottlenecks (e.g., noise or high cost) and exhibit unstable improvements in the quality of long chain-of-thoughts (CoTs) and downstream performance.To address these limitations, we propose VerIPO, a Verifier-guided Iterative Policy Optimization method designed to gradually improve video LLMs' capacity for generating deep, long-term reasoning chains. The core component is Rollout-Aware Verifier, positioned between the GRPO and Direct Preference Optimization (DPO) training phases to form the GRPO-Verifier-DPO training loop. This verifier leverages small LLMs as a judge to assess the reasoning logic of rollouts, enabling the construction of high-quality contrastive data, including reflective and contextually consistent CoTs. These curated preference samples drive the efficient DPO stage (7x faster than GRPO), leading to marked improvements in reasoning chain quality, especially in terms of length and contextual consistency. This training loop benefits from GRPO's expansive search and DPO's targeted optimization. Experimental results demonstrate: 1) Significantly faster and more effective optimization compared to standard GRPO variants, yielding superior performance; 2) Our trained models exceed the direct inference of large-scale instruction-tuned Video-LLMs, producing long and contextually consistent CoTs on diverse video reasoning tasks; and 3) Our model with one iteration outperforms powerful LMMs (e.g., Kimi-VL) and long reasoning models (e.g., Video-R1), highlighting its effectiveness and stability.
Perception, Reason, Think, and Plan: A Survey on Large Multimodal Reasoning Models
May 08, 2025
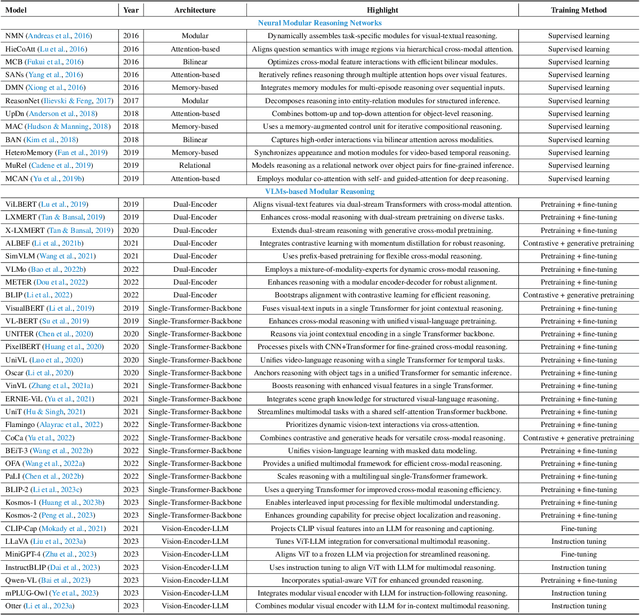
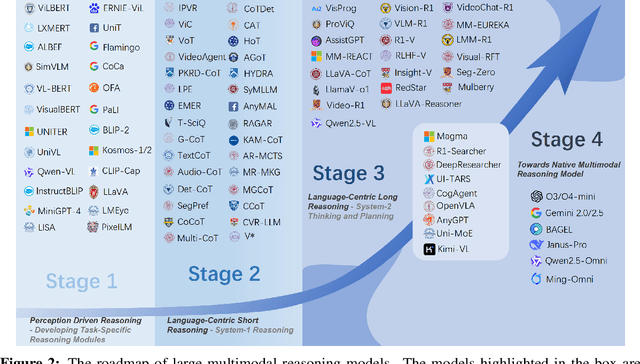
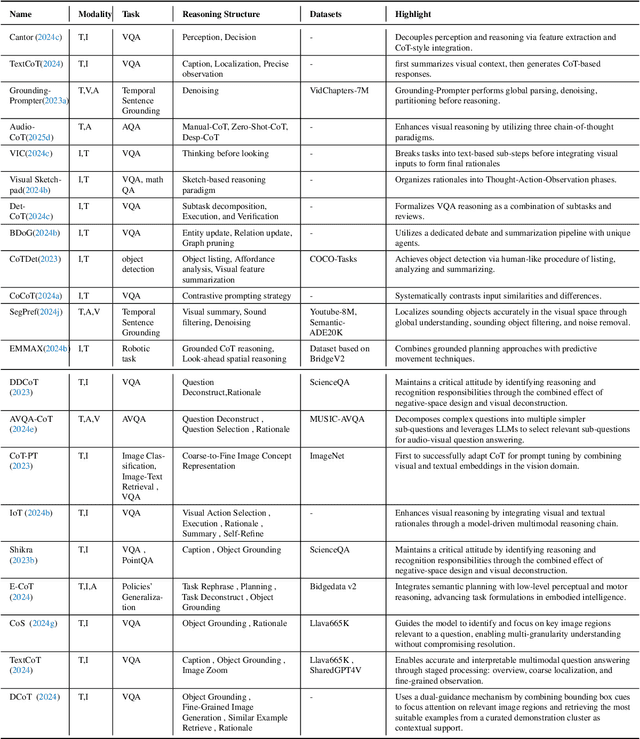
Reasoning lies at the heart of intelligence, shaping the ability to make decisions, draw conclusions, and generalize across domains. In artificial intelligence, as systems increasingly operate in open, uncertain, and multimodal environments, reasoning becomes essential for enabling robust and adaptive behavior. Large Multimodal Reasoning Models (LMRMs) have emerged as a promising paradigm, integrating modalities such as text, images, audio, and video to support complex reasoning capabilities and aiming to achieve comprehensive perception, precise understanding, and deep reasoning. As research advances, multimodal reasoning has rapidly evolved from modular, perception-driven pipelines to unified, language-centric frameworks that offer more coherent cross-modal understanding. While instruction tuning and reinforcement learning have improved model reasoning, significant challenges remain in omni-modal generalization, reasoning depth, and agentic behavior. To address these issues, we present a comprehensive and structured survey of multimodal reasoning research, organized around a four-stage developmental roadmap that reflects the field's shifting design philosophies and emerging capabilities. First, we review early efforts based on task-specific modules, where reasoning was implicitly embedded across stages of representation, alignment, and fusion. Next, we examine recent approaches that unify reasoning into multimodal LLMs, with advances such as Multimodal Chain-of-Thought (MCoT) and multimodal reinforcement learning enabling richer and more structured reasoning chains. Finally, drawing on empirical insights from challenging benchmarks and experimental cases of OpenAI O3 and O4-mini, we discuss the conceptual direction of native large multimodal reasoning models (N-LMRMs), which aim to support scalable, agentic, and adaptive reasoning and planning in complex, real-world environments.
KIMAs: A Configurable Knowledge Integrated Multi-Agent System
Feb 13, 2025Knowledge-intensive conversations supported by large language models (LLMs) have become one of the most popular and helpful applications that can assist people in different aspects. Many current knowledge-intensive applications are centered on retrieval-augmented generation (RAG) techniques. While many open-source RAG frameworks facilitate the development of RAG-based applications, they often fall short in handling practical scenarios complicated by heterogeneous data in topics and formats, conversational context management, and the requirement of low-latency response times. This technical report presents a configurable knowledge integrated multi-agent system, KIMAs, to address these challenges. KIMAs features a flexible and configurable system for integrating diverse knowledge sources with 1) context management and query rewrite mechanisms to improve retrieval accuracy and multi-turn conversational coherency, 2) efficient knowledge routing and retrieval, 3) simple but effective filter and reference generation mechanisms, and 4) optimized parallelizable multi-agent pipeline execution. Our work provides a scalable framework for advancing the deployment of LLMs in real-world settings. To show how KIMAs can help developers build knowledge-intensive applications with different scales and emphases, we demonstrate how we configure the system to three applications already running in practice with reliable performance.
Talk to Right Specialists: Routing and Planning in Multi-agent System for Question Answering
Jan 14, 2025



Leveraging large language models (LLMs), an agent can utilize retrieval-augmented generation (RAG) techniques to integrate external knowledge and increase the reliability of its responses. Current RAG-based agents integrate single, domain-specific knowledge sources, limiting their ability and leading to hallucinated or inaccurate responses when addressing cross-domain queries. Integrating multiple knowledge bases into a unified RAG-based agent raises significant challenges, including increased retrieval overhead and data sovereignty when sensitive data is involved. In this work, we propose RopMura, a novel multi-agent system that addresses these limitations by incorporating highly efficient routing and planning mechanisms. RopMura features two key components: a router that intelligently selects the most relevant agents based on knowledge boundaries and a planner that decomposes complex multi-hop queries into manageable steps, allowing for coordinating cross-domain responses. Experimental results demonstrate that RopMura effectively handles both single-hop and multi-hop queries, with the routing mechanism enabling precise answers for single-hop queries and the combined routing and planning mechanisms achieving accurate, multi-step resolutions for complex queries.
Make LLMs better zero-shot reasoners: Structure-orientated autonomous reasoning
Oct 18, 2024


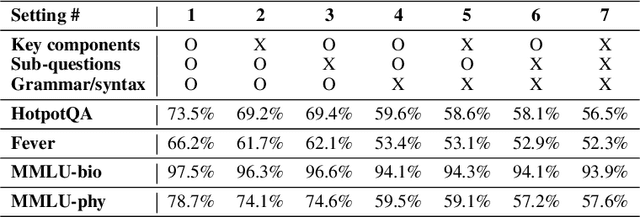
Zero-shot reasoning methods with Large Language Models (LLMs) offer significant advantages including great generalization to novel tasks and reduced dependency on human-crafted examples. However, the current zero-shot methods still have limitations in complex tasks, e.g., answering questions that require multi-step reasoning. In this paper, we address this limitation by introducing a novel structure-oriented analysis method to help LLMs better understand the question and guide the problem-solving process of LLMs. We first demonstrate how the existing reasoning strategies, Chain-of-Thought and ReAct, can benefit from our structure-oriented analysis. In addition to empirical investigations, we leverage the probabilistic graphical model to theoretically explain why our structure-oriented analysis can improve the LLM reasoning process. To further improve the reliability in complex question-answering tasks, we propose a multi-agent reasoning system, Structure-oriented Autonomous Reasoning Agents (SARA), that can better enforce the reasoning process following our structure-oriented analysis by refinement techniques and is equipped with external knowledge retrieval capability to reduce factual errors. Extensive experiments verify the effectiveness of the proposed reasoning system. Surprisingly, in some cases, the system even surpasses few-shot methods. Finally, the system not only improves reasoning accuracy in complex tasks but also demonstrates robustness against potential attacks that corrupt the reasoning process.
FedBiOT: LLM Local Fine-tuning in Federated Learning without Full Model
Jun 25, 2024



Large language models (LLMs) show amazing performance on many domain-specific tasks after fine-tuning with some appropriate data. However, many domain-specific data are privately distributed across multiple owners. Thus, this dilemma raises the interest in how to perform LLM fine-tuning in federated learning (FL). However, confronted with limited computation and communication capacities, FL clients struggle to fine-tune an LLM effectively. To this end, we introduce FedBiOT, a resource-efficient LLM fine-tuning approach to FL. Specifically, our method involves the server generating a compressed LLM and aligning its performance with the full model. Subsequently, the clients fine-tune a lightweight yet important part of the compressed model, referred to as an adapter. Notice that as the server has no access to the private data owned by the clients, the data used for alignment by the server has a different distribution from the one used for fine-tuning by clients. We formulate the problem into a bi-level optimization problem to minimize the negative effect of data discrepancy and derive the updating rules for the server and clients. We conduct extensive experiments on LLaMA-2, empirically showing that the adapter has exceptional performance when reintegrated into the global LLM. The results also indicate that the proposed FedBiOT significantly reduces resource consumption compared to existing benchmarks, all while achieving comparable performance levels.
Improving LoRA in Privacy-preserving Federated Learning
Mar 18, 2024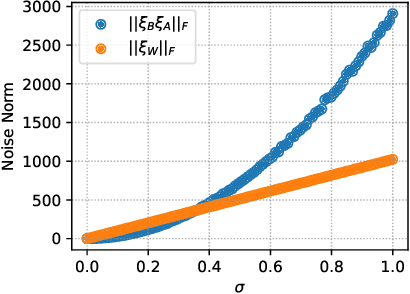



Low-rank adaptation (LoRA) is one of the most popular task-specific parameter-efficient fine-tuning (PEFT) methods on pre-trained language models for its good performance and computational efficiency. LoRA injects a product of two trainable rank decomposition matrices over the top of each frozen pre-trained model module. However, when applied in the setting of privacy-preserving federated learning (FL), LoRA may become unstable due to the following facts: 1) the effects of data heterogeneity and multi-step local updates are non-negligible, 2) additive noise enforced on updating gradients to guarantee differential privacy (DP) can be amplified and 3) the final performance is susceptible to hyper-parameters. A key factor leading to these phenomena is the discordance between jointly optimizing the two low-rank matrices by local clients and separately aggregating them by the central server. Thus, this paper proposes an efficient and effective version of LoRA, Federated Freeze A LoRA (FFA-LoRA), to alleviate these challenges and further halve the communication cost of federated fine-tuning LLMs. The core idea of FFA-LoRA is to fix the randomly initialized non-zero matrices and only fine-tune the zero-initialized matrices. Compared to LoRA, FFA-LoRA is motivated by practical and theoretical benefits in privacy-preserved FL. Our experiments demonstrate that FFA-LoRA provides more consistent performance with better computational efficiency over vanilla LoRA in various FL tasks.
A Bargaining-based Approach for Feature Trading in Vertical Federated Learning
Feb 23, 2024Vertical Federated Learning (VFL) has emerged as a popular machine learning paradigm, enabling model training across the data and the task parties with different features about the same user set while preserving data privacy. In production environment, VFL usually involves one task party and one data party. Fair and economically efficient feature trading is crucial to the commercialization of VFL, where the task party is considered as the data consumer who buys the data party's features. However, current VFL feature trading practices often price the data party's data as a whole and assume transactions occur prior to the performing VFL. Neglecting the performance gains resulting from traded features may lead to underpayment and overpayment issues. In this study, we propose a bargaining-based feature trading approach in VFL to encourage economically efficient transactions. Our model incorporates performance gain-based pricing, taking into account the revenue-based optimization objectives of both parties. We analyze the proposed bargaining model under perfect and imperfect performance information settings, proving the existence of an equilibrium that optimizes the parties' objectives. Moreover, we develop performance gain estimation-based bargaining strategies for imperfect performance information scenarios and discuss potential security issues and solutions. Experiments on three real-world datasets demonstrate the effectiveness of the proposed bargaining model.
AgentScope: A Flexible yet Robust Multi-Agent Platform
Feb 21, 2024With the rapid advancement of Large Language Models (LLMs), significant progress has been made in multi-agent applications. However, the complexities in coordinating agents' cooperation and LLMs' erratic performance pose notable challenges in developing robust and efficient multi-agent applications. To tackle these challenges, we propose AgentScope, a developer-centric multi-agent platform with message exchange as its core communication mechanism. Together with abundant syntactic tools, built-in resources, and user-friendly interactions, our communication mechanism significantly reduces the barriers to both development and understanding. Towards robust and flexible multi-agent application, AgentScope provides both built-in and customizable fault tolerance mechanisms while it is also armed with system-level supports for multi-modal data generation, storage and transmission. Additionally, we design an actor-based distribution framework, enabling easy conversion between local and distributed deployments and automatic parallel optimization without extra effort. With these features, AgentScope empowers developers to build applications that fully realize the potential of intelligent agents. We have released AgentScope at https://github.com/modelscope/agentscope, and hope AgentScope invites wider participation and innovation in this fast-moving field.