 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMake LLMs better zero-shot reasoners: Structure-orientated autonomous reasoning
Oct 18, 2024


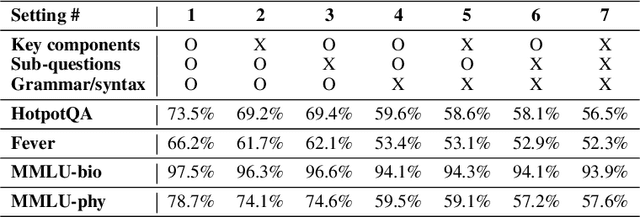
Zero-shot reasoning methods with Large Language Models (LLMs) offer significant advantages including great generalization to novel tasks and reduced dependency on human-crafted examples. However, the current zero-shot methods still have limitations in complex tasks, e.g., answering questions that require multi-step reasoning. In this paper, we address this limitation by introducing a novel structure-oriented analysis method to help LLMs better understand the question and guide the problem-solving process of LLMs. We first demonstrate how the existing reasoning strategies, Chain-of-Thought and ReAct, can benefit from our structure-oriented analysis. In addition to empirical investigations, we leverage the probabilistic graphical model to theoretically explain why our structure-oriented analysis can improve the LLM reasoning process. To further improve the reliability in complex question-answering tasks, we propose a multi-agent reasoning system, Structure-oriented Autonomous Reasoning Agents (SARA), that can better enforce the reasoning process following our structure-oriented analysis by refinement techniques and is equipped with external knowledge retrieval capability to reduce factual errors. Extensive experiments verify the effectiveness of the proposed reasoning system. Surprisingly, in some cases, the system even surpasses few-shot methods. Finally, the system not only improves reasoning accuracy in complex tasks but also demonstrates robustness against potential attacks that corrupt the reasoning process.
Leveraging Unknown Objects to Construct Labeled-Unlabeled Meta-Relationships for Zero-Shot Object Navigation
May 27, 2024Zero-shot object navigation (ZSON) addresses situation where an agent navigates to an unseen object that does not present in the training set. Previous works mainly train agent using seen objects with known labels, and ignore the seen objects without labels. In this paper, we introduce seen objects without labels, herein termed as ``unknown objects'', into training procedure to enrich the agent's knowledge base with distinguishable but previously overlooked information. Furthermore, we propose the label-wise meta-correlation module (LWMCM) to harness relationships among objects with and without labels, and obtain enhanced objects information. Specially, we propose target feature generator (TFG) to generate the features representation of the unlabeled target objects. Subsequently, the unlabeled object identifier (UOI) module assesses whether the unlabeled target object appears in the current observation frame captured by the camera and produces an adapted target features representation specific to the observed context. In meta contrastive feature modifier (MCFM), the target features is modified via approaching the features of objects within the observation frame while distancing itself from features of unobserved objects. Finally, the meta object-graph learner (MOGL) module is utilized to calculate the relationships among objects based on the features. Experiments conducted on AI2THOR and RoboTHOR platforms demonstrate the effectiveness of our proposed method.