 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Unknown Objects to Construct Labeled-Unlabeled Meta-Relationships for Zero-Shot Object Navigation
May 27, 2024Zero-shot object navigation (ZSON) addresses situation where an agent navigates to an unseen object that does not present in the training set. Previous works mainly train agent using seen objects with known labels, and ignore the seen objects without labels. In this paper, we introduce seen objects without labels, herein termed as ``unknown objects'', into training procedure to enrich the agent's knowledge base with distinguishable but previously overlooked information. Furthermore, we propose the label-wise meta-correlation module (LWMCM) to harness relationships among objects with and without labels, and obtain enhanced objects information. Specially, we propose target feature generator (TFG) to generate the features representation of the unlabeled target objects. Subsequently, the unlabeled object identifier (UOI) module assesses whether the unlabeled target object appears in the current observation frame captured by the camera and produces an adapted target features representation specific to the observed context. In meta contrastive feature modifier (MCFM), the target features is modified via approaching the features of objects within the observation frame while distancing itself from features of unobserved objects. Finally, the meta object-graph learner (MOGL) module is utilized to calculate the relationships among objects based on the features. Experiments conducted on AI2THOR and RoboTHOR platforms demonstrate the effectiveness of our proposed method.
Temporal-Spatial Object Relations Modeling for Vision-and-Language Navigation
Mar 23, 2024Vision-and-Language Navigation (VLN) is a challenging task where an agent is required to navigate to a natural language described location via vision observations. The navigation abilities of the agent can be enhanced by the relations between objects, which are usually learned using internal objects or external datasets. The relationships between internal objects are modeled employing graph convolutional network (GCN) in traditional studies. However, GCN tends to be shallow, limiting its modeling ability. To address this issue, we utilize a cross attention mechanism to learn the connections between objects over a trajectory, which takes temporal continuity into account, termed as Temporal Object Relations (TOR). The external datasets have a gap with the navigation environment, leading to inaccurate modeling of relations. To avoid this problem, we construct object connections based on observations from all viewpoints in the navigational environment, which ensures complete spatial coverage and eliminates the gap, called Spatial Object Relations (SOR). Additionally, we observe that agents may repeatedly visit the same location during navigation, significantly hindering their performance. For resolving this matter, we introduce the Turning Back Penalty (TBP) loss function, which penalizes the agent's repetitive visiting behavior, substantially reducing the navigational distance. Experimental results on the REVERIE, SOON, and R2R datasets demonstrate the effectiveness of the proposed method.
CPCL: Cross-Modal Prototypical Contrastive Learning for Weakly Supervised Text-based Person Re-Identification
Jan 18, 2024Weakly supervised text-based person re-identification (TPRe-ID) seeks to retrieve images of a target person using textual descriptions, without relying on identity annotations and is more challenging and practical. The primary challenge is the intra-class differences, encompassing intra-modal feature variations and cross-modal semantic gaps. Prior works have focused on instance-level samples and ignored prototypical features of each person which are intrinsic and invariant. Toward this, we propose a Cross-Modal Prototypical Contrastive Learning (CPCL) method. In practice, the CPCL introduces the CLIP model to weakly supervised TPRe-ID for the first time, mapping visual and textual instances into a shared latent space. Subsequently, the proposed Prototypical Multi-modal Memory (PMM) module captures associations between heterogeneous modalities of image-text pairs belonging to the same person through the Hybrid Cross-modal Matching (HCM) module in a many-to-many mapping fashion. Moreover, the Outlier Pseudo Label Mining (OPLM) module further distinguishes valuable outlier samples from each modality, enhancing the creation of more reliable clusters by mining implicit relationships between image-text pairs. Experimental results demonstrate that our proposed CPCL attains state-of-the-art performance on all three public datasets, with a significant improvement of 11.58%, 8.77% and 5.25% in Rank@1 accuracy on CUHK-PEDES, ICFG-PEDES and RSTPReid datasets, respectively. The code is available at https://github.com/codeGallery24/CPCL.
Tracking Fast by Learning Slow: An Event-based Speed Adaptive Hand Tracker Leveraging Knowledge in RGB Domain
Feb 28, 20233D hand tracking methods based on monocular RGB videos are easily affected by motion blur, while event camera, a sensor with high temporal resolution and dynamic range, is naturally suitable for this task with sparse output and low power consumption. However, obtaining 3D annotations of fast-moving hands is difficult for constructing event-based hand-tracking datasets. In this paper, we provided an event-based speed adaptive hand tracker (ESAHT) to solve the hand tracking problem based on event camera. We enabled a CNN model trained on a hand tracking dataset with slow motion, which enabled the model to leverage the knowledge of RGB-based hand tracking solutions, to work on fast hand tracking tasks. To realize our solution, we constructed the first 3D hand tracking dataset captured by an event camera in a real-world environment, figured out two data augment methods to narrow the domain gap between slow and fast motion data, developed a speed adaptive event stream segmentation method to handle hand movements in different moving speeds, and introduced a new event-to-frame representation method adaptive to event streams with different lengths. Experiments showed that our solution outperformed RGB-based as well as previous event-based solutions in fast hand tracking tasks, and our codes and dataset will be publicly available.
Multi-modal estimation of the properties of containers and their content: survey and evaluation
Jul 27, 2021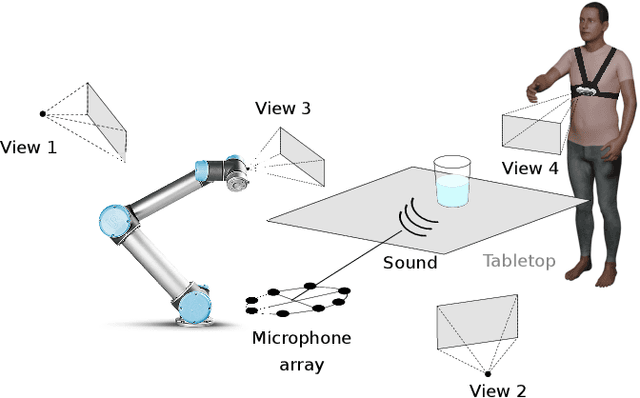


Acoustic and visual sensing can support the contactless estimation of the weight of a container and the amount of its content when the container is manipulated by a person. However, transparencies (both of the container and of the content) and the variability of materials, shapes and sizes make this problem challenging. In this paper, we present an open benchmarking framework and an in-depth comparative analysis of recent methods that estimate the capacity of a container, as well as the type, mass, and amount of its content. These methods use learned and handcrafted features, such as mel-frequency cepstrum coefficients, zero-crossing rate, spectrograms, with different types of classifiers to estimate the type and amount of the content with acoustic data, and geometric approaches with visual data to determine the capacity of the container. Results on a newly distributed dataset show that audio alone is a strong modality and methods achieves a weighted average F1-score up to 81% and 97% for content type and level classification, respectively. Estimating the container capacity with vision-only approaches and filling mass with multi-modal, multi-stage algorithms reaches up to 65% weighted average capacity and mass scores.
IROS 2019 Lifelong Robotic Vision Challenge -- Lifelong Object Recognition Report
Apr 26, 2020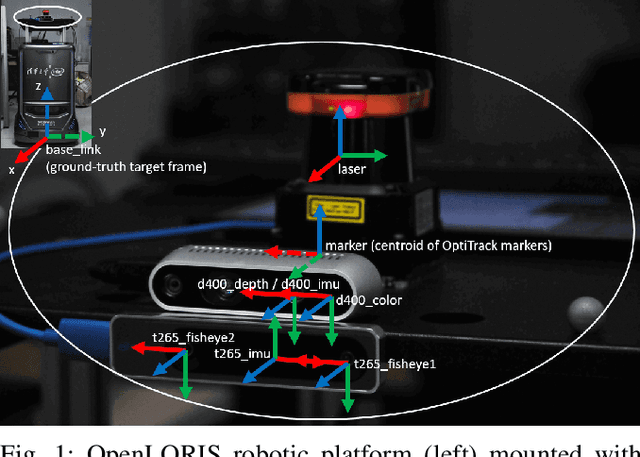
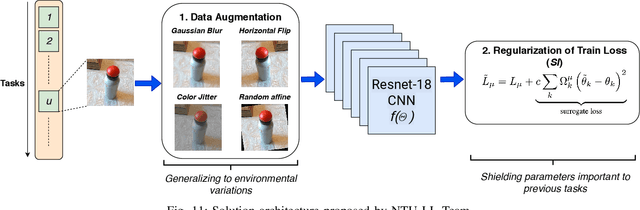

This report summarizes IROS 2019-Lifelong Robotic Vision Competition (Lifelong Object Recognition Challenge) with methods and results from the top $8$ finalists (out of over~$150$ teams). The competition dataset (L)ifel(O)ng (R)obotic V(IS)ion (OpenLORIS) - Object Recognition (OpenLORIS-object) is designed for driving lifelong/continual learning research and application in robotic vision domain, with everyday objects in home, office, campus, and mall scenarios. The dataset explicitly quantifies the variants of illumination, object occlusion, object size, camera-object distance/angles, and clutter information. Rules are designed to quantify the learning capability of the robotic vision system when faced with the objects appearing in the dynamic environments in the contest. Individual reports, dataset information, rules, and released source code can be found at the project homepage: "https://lifelong-robotic-vision.github.io/competition/".
OpenLORIS-Object: A Dataset and Benchmark towards Lifelong Object Recognition
Nov 15, 2019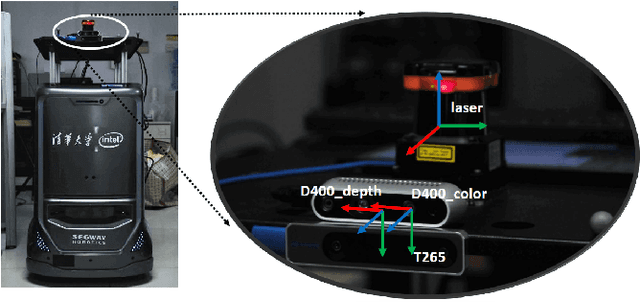


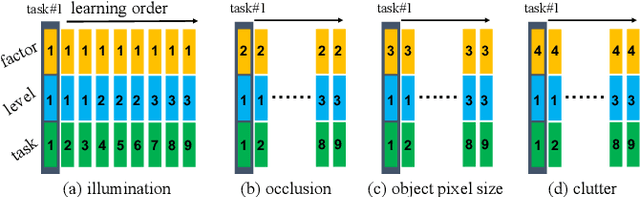
The recent breakthroughs in computer vision have benefited from the availability of large representative datasets (e.g. ImageNet and COCO) for training. Yet, robotic vision poses unique challenges for applying visual algorithms developed from these standard computer vision datasets due to their implicit assumption over non-varying distributions for a fixed set of tasks. Fully retraining models each time a new task becomes available is infeasible due to computational, storage and sometimes privacy issues, while na\"{i}ve incremental strategies have been shown to suffer from catastrophic forgetting. It is crucial for the robots to operate continuously under open-set and detrimental conditions with adaptive visual perceptual systems, where lifelong learning is a fundamental capability. However, very few datasets and benchmarks are available to evaluate and compare emerging techniques. To fill this gap, we provide a new lifelong robotic vision dataset ("OpenLORIS-Object") collected via RGB-D cameras mounted on mobile robots. The dataset embeds the challenges faced by a robot in the real-life application and provides new benchmarks for validating lifelong object recognition algorithms. Moreover, we have provided a testbed of $9$ state-of-the-art lifelong learning algorithms. Each of them involves $48$ tasks with $4$ evaluation metrics over the OpenLORIS-Object dataset. The results demonstrate that the object recognition task in the ever-changing difficulty environments is far from being solved and the bottlenecks are at the forward/backward transfer designs. Our dataset and benchmark are publicly available at \href{https://lifelong-robotic-vision.github.io/dataset/Data_Object-Recognition.html}{\underline{this url}}.