 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Facial Expression Recognition: A Benchmark
May 10, 2023
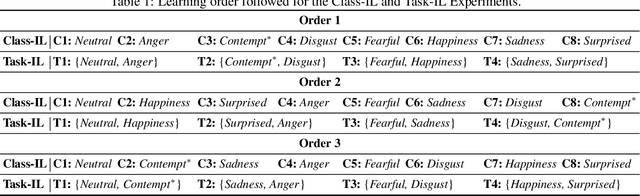
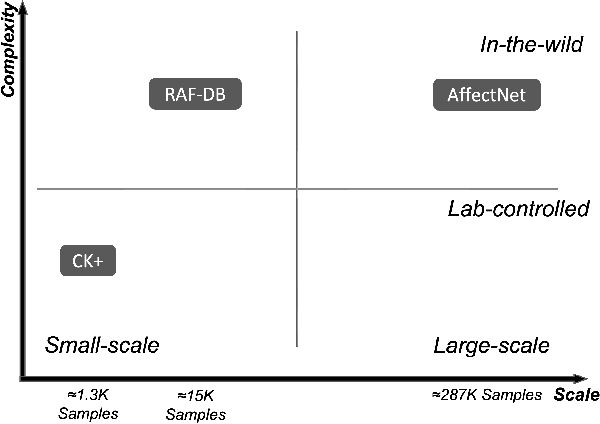

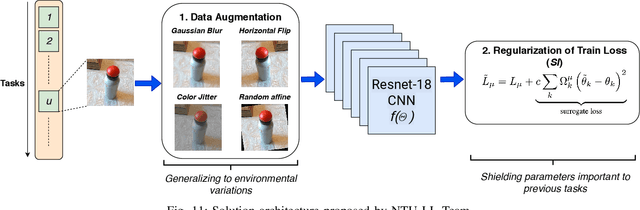
Understanding human affective behaviour, especially in the dynamics of real-world settings, requires Facial Expression Recognition (FER) models to continuously adapt to individual differences in user expression, contextual attributions, and the environment. Current (deep) Machine Learning (ML)-based FER approaches pre-trained in isolation on benchmark datasets fail to capture the nuances of real-world interactions where data is available only incrementally, acquired by the agent or robot during interactions. New learning comes at the cost of previous knowledge, resulting in catastrophic forgetting. Lifelong or Continual Learning (CL), on the other hand, enables adaptability in agents by being sensitive to changing data distributions, integrating new information without interfering with previously learnt knowledge. Positing CL as an effective learning paradigm for FER, this work presents the Continual Facial Expression Recognition (ConFER) benchmark that evaluates popular CL techniques on FER tasks. It presents a comparative analysis of several CL-based approaches on popular FER datasets such as CK+, RAF-DB, and AffectNet and present strategies for a successful implementation of ConFER for Affective Computing (AC) research. CL techniques, under different learning settings, are shown to achieve state-of-the-art (SOTA) performance across several datasets, thus motivating a discussion on the benefits of applying CL principles towards human behaviour understanding, particularly from facial expressions, as well the challenges entailed.
Avalanche: an End-to-End Library for Continual Learning
Apr 01, 2021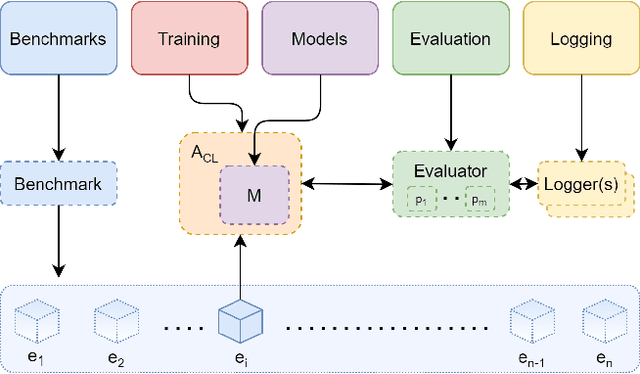


Learning continually from non-stationary data streams is a long-standing goal and a challenging problem in machine learning. Recently, we have witnessed a renewed and fast-growing interest in continual learning, especially within the deep learning community. However, algorithmic solutions are often difficult to re-implement, evaluate and port across different settings, where even results on standard benchmarks are hard to reproduce. In this work, we propose Avalanche, an open-source end-to-end library for continual learning research based on PyTorch. Avalanche is designed to provide a shared and collaborative codebase for fast prototyping, training, and reproducible evaluation of continual learning algorithms.
CVPR 2020 Continual Learning in Computer Vision Competition: Approaches, Results, Current Challenges and Future Directions
Sep 14, 2020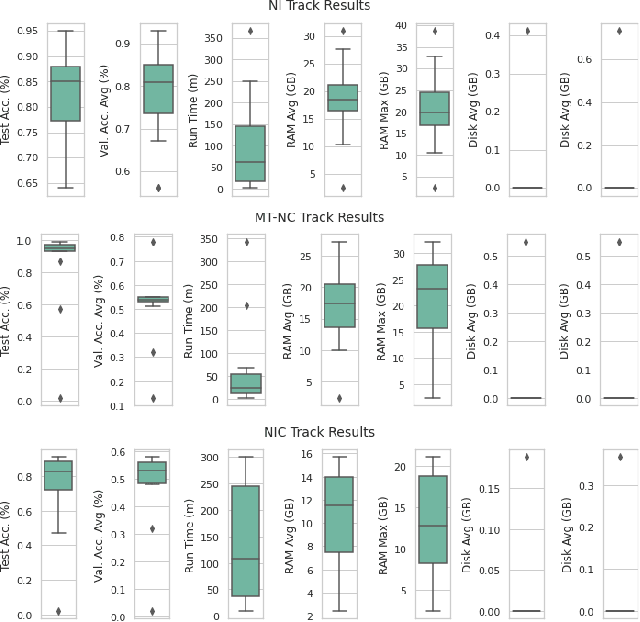

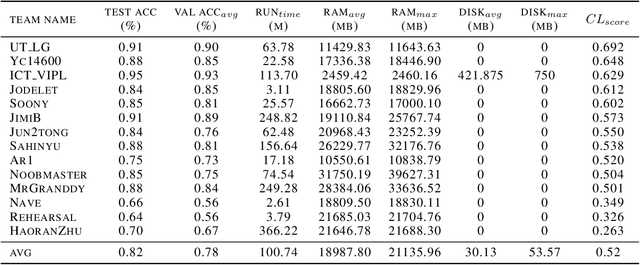
In the last few years, we have witnessed a renewed and fast-growing interest in continual learning with deep neural networks with the shared objective of making current AI systems more adaptive, efficient and autonomous. However, despite the significant and undoubted progress of the field in addressing the issue of catastrophic forgetting, benchmarking different continual learning approaches is a difficult task by itself. In fact, given the proliferation of different settings, training and evaluation protocols, metrics and nomenclature, it is often tricky to properly characterize a continual learning algorithm, relate it to other solutions and gauge its real-world applicability. The first Continual Learning in Computer Vision challenge held at CVPR in 2020 has been one of the first opportunities to evaluate different continual learning algorithms on a common hardware with a large set of shared evaluation metrics and 3 different settings based on the realistic CORe50 video benchmark. In this paper, we report the main results of the competition, which counted more than 79 teams registered, 11 finalists and 2300$ in prizes. We also summarize the winning approaches, current challenges and future research directions.
IROS 2019 Lifelong Robotic Vision Challenge -- Lifelong Object Recognition Report
Apr 26, 2020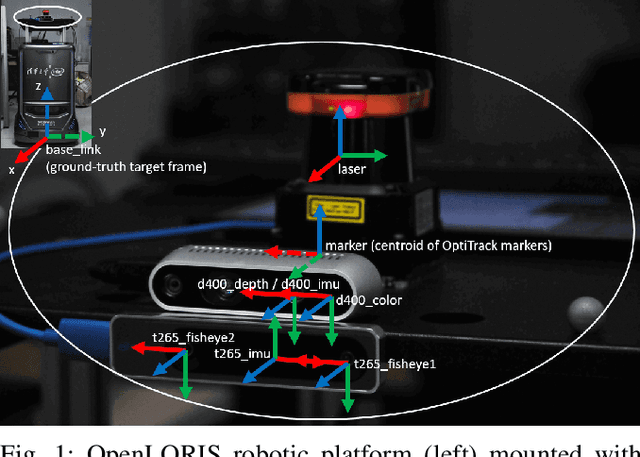
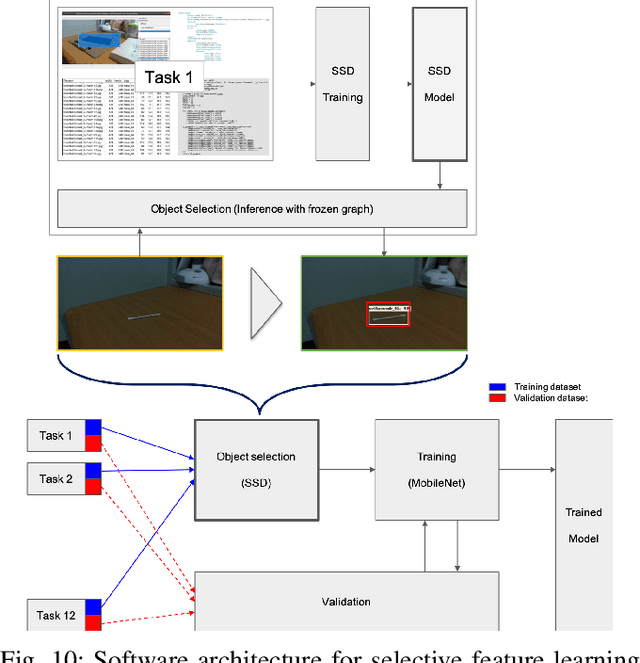

This report summarizes IROS 2019-Lifelong Robotic Vision Competition (Lifelong Object Recognition Challenge) with methods and results from the top $8$ finalists (out of over~$150$ teams). The competition dataset (L)ifel(O)ng (R)obotic V(IS)ion (OpenLORIS) - Object Recognition (OpenLORIS-object) is designed for driving lifelong/continual learning research and application in robotic vision domain, with everyday objects in home, office, campus, and mall scenarios. The dataset explicitly quantifies the variants of illumination, object occlusion, object size, camera-object distance/angles, and clutter information. Rules are designed to quantify the learning capability of the robotic vision system when faced with the objects appearing in the dynamic environments in the contest. Individual reports, dataset information, rules, and released source code can be found at the project homepage: "https://lifelong-robotic-vision.github.io/competition/".
Online Continual Learning on Sequences
Mar 20, 2020Online continual learning (OCL) refers to the ability of a system to learn over time from a continuous stream of data without having to revisit previously encountered training samples. Learning continually in a single data pass is crucial for agents and robots operating in changing environments and required to acquire, fine-tune, and transfer increasingly complex representations from non-i.i.d. input distributions. Machine learning models that address OCL must alleviate \textit{catastrophic forgetting} in which hidden representations are disrupted or completely overwritten when learning from streams of novel input. In this chapter, we summarize and discuss recent deep learning models that address OCL on sequential input through the use (and combination) of synaptic regularization, structural plasticity, and experience replay. Different implementations of replay have been proposed that alleviate catastrophic forgetting in connectionists architectures via the re-occurrence of (latent representations of) input sequences and that functionally resemble mechanisms of hippocampal replay in the mammalian brain. Empirical evidence shows that architectures endowed with experience replay typically outperform architectures without in (online) incremental learning tasks.
Human Action Recognition and Assessment via Deep Neural Network Self-Organization
Feb 16, 2020
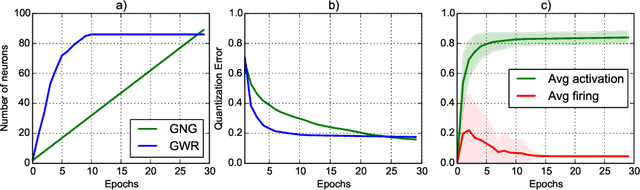
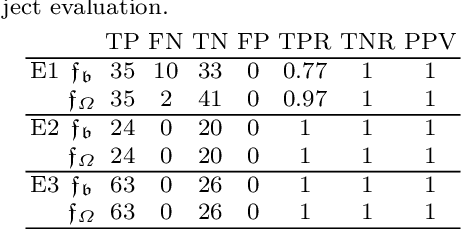
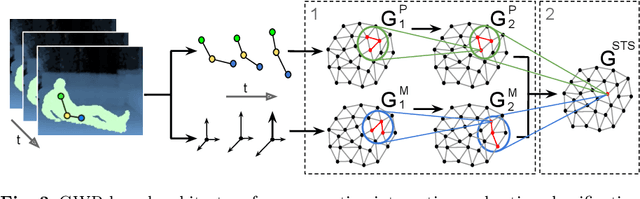
The robust recognition and assessment of human actions are crucial in human-robot interaction (HRI) domains. While state-of-the-art models of action perception show remarkable results in large-scale action datasets, they mostly lack the flexibility, robustness, and scalability needed to operate in natural HRI scenarios which require the continuous acquisition of sensory information as well as the classification or assessment of human body patterns in real time. In this chapter, I introduce a set of hierarchical models for the learning and recognition of actions from depth maps and RGB images through the use of neural network self-organization. A particularity of these models is the use of growing self-organizing networks that quickly adapt to non-stationary distributions and implement dedicated mechanisms for continual learning from temporally correlated input.
Rethinking Continual Learning for Autonomous Agents and Robots
Jul 02, 2019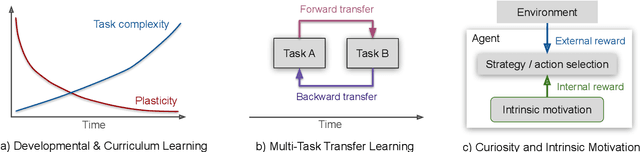
Continual learning refers to the ability of a biological or artificial system to seamlessly learn from continuous streams of information while preventing catastrophic forgetting, i.e., a condition in which new incoming information strongly interferes with previously learned representations. Since it is unrealistic to provide artificial agents with all the necessary prior knowledge to effectively operate in real-world conditions, they must exhibit a rich set of learning capabilities enabling them to interact in complex environments with the aim to process and make sense of continuous streams of (often uncertain) information. While the vast majority of continual learning models are designed to alleviate catastrophic forgetting on simplified classification tasks, here we focus on continual learning for autonomous agents and robots required to operate in much more challenging experimental settings. In particular, we discuss well-established biological learning factors such as developmental and curriculum learning, transfer learning, and intrinsic motivation and their computational counterparts for modeling the progressive acquisition of increasingly complex knowledge and skills in a continual fashion.
A Personalized Affective Memory Neural Model for Improving Emotion Recognition
Apr 23, 2019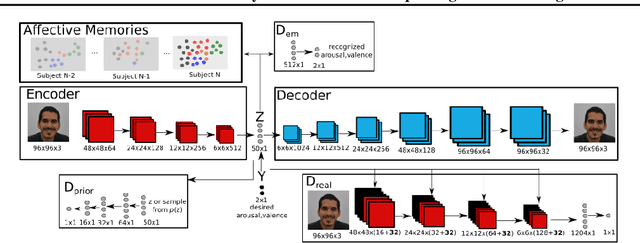

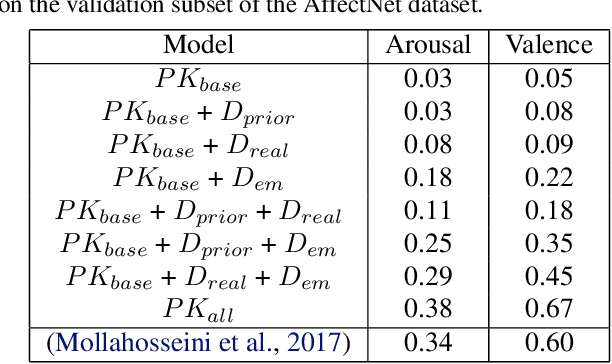
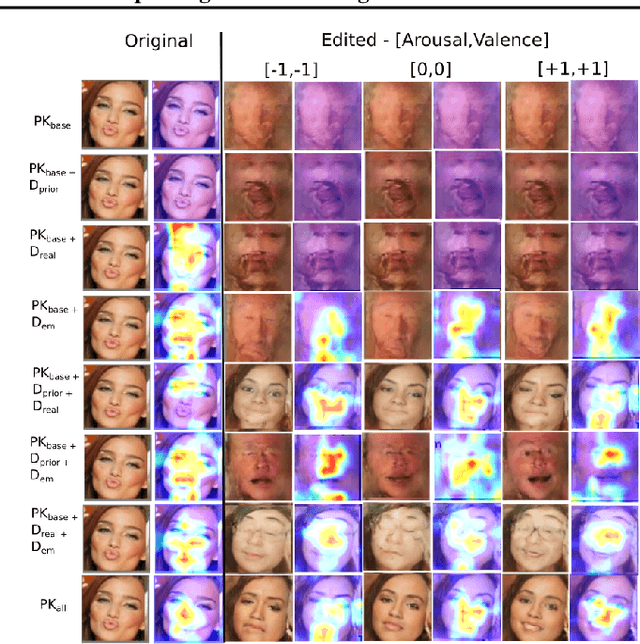
Recent models of emotion recognition strongly rely on supervised deep learning solutions for the distinction of general emotion expressions. However, they are not reliable when recognizing online and personalized facial expressions, e.g., for person-specific affective understanding. In this paper, we present a neural model based on a conditional adversarial autoencoder to learn how to represent and edit general emotion expressions. We then propose Grow-When-Required networks as personalized affective memories to learn individualized aspects of emotion expressions. Our model achieves state-of-the-art performance on emotion recognition when evaluated on \textit{in-the-wild} datasets. Furthermore, our experiments include ablation studies and neural visualizations in order to explain the behavior of our model.
On the role of neurogenesis in overcoming catastrophic forgetting
Nov 30, 2018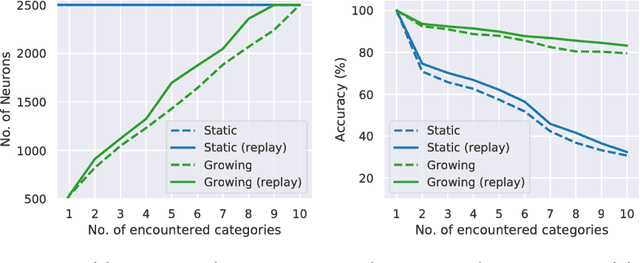


Lifelong learning capabilities are crucial for artificial autonomous agents operating on real-world data, which is typically non-stationary and temporally correlated. In this work, we demonstrate that dynamically grown networks outperform static networks in incremental learning scenarios, even when bounded by the same amount of memory in both cases. Learning is unsupervised in our models, a condition that additionally makes training more challenging whilst increasing the realism of the study, since humans are able to learn without dense manual annotation. Our results on artificial neural networks reinforce that structural plasticity constitutes effective prevention against catastrophic forgetting in non-stationary environments, as well as empirically supporting the importance of neurogenesis in the mammalian brain.
Lifelong Learning of Spatiotemporal Representations with Dual-Memory Recurrent Self-Organization
Oct 30, 2018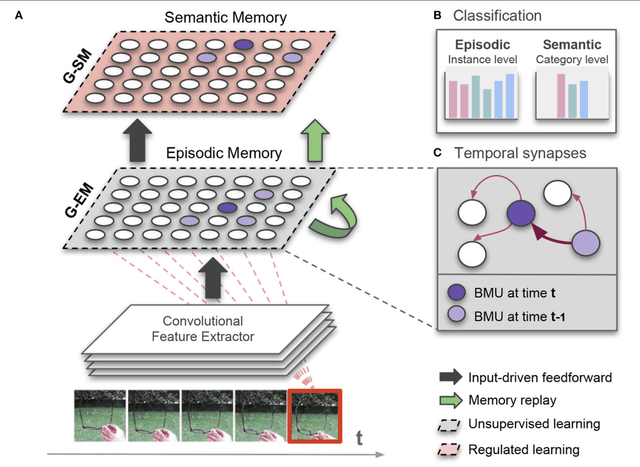



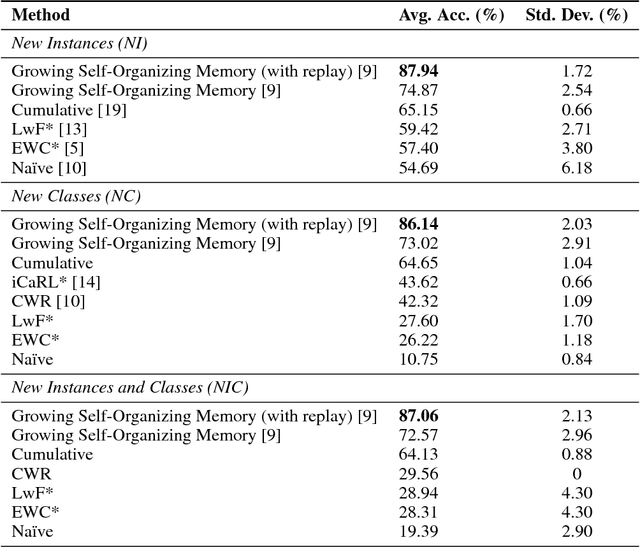
Artificial autonomous agents and robots interacting in complex environments are required to continually acquire and fine-tune knowledge over sustained periods of time. The ability to learn from continuous streams of information is referred to as lifelong learning and represents a long-standing challenge for neural network models due to catastrophic forgetting. Computational models of lifelong learning typically alleviate catastrophic forgetting in experimental scenarios with given datasets of static images and limited complexity, thereby differing significantly from the conditions artificial agents are exposed to. In more natural settings, sequential information may become progressively available over time and access to previous experience may be restricted. In this paper, we propose a dual-memory self-organizing architecture for lifelong learning scenarios. The architecture comprises two growing recurrent networks with the complementary tasks of learning object instances (episodic memory) and categories (semantic memory). Both growing networks can expand in response to novel sensory experience: the episodic memory learns fine-grained spatiotemporal representations of object instances in an unsupervised fashion while the semantic memory uses task-relevant signals to regulate structural plasticity levels and develop more compact representations from episodic experience. For the consolidation of knowledge in the absence of external sensory input, the episodic memory periodically replays trajectories of neural reactivations. We evaluate the proposed model on the CORe50 benchmark dataset for continuous object recognition, showing that we significantly outperform current methods of lifelong learning in three different incremental learning scenarios