 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the challenges to learn from Natural Data Streams
Jan 09, 2023



In real-world contexts, sometimes data are available in form of Natural Data Streams, i.e. data characterized by a streaming nature, unbalanced distribution, data drift over a long time frame and strong correlation of samples in short time ranges. Moreover, a clear separation between the traditional training and deployment phases is usually lacking. This data organization and fruition represents an interesting and challenging scenario for both traditional Machine and Deep Learning algorithms and incremental learning agents, i.e. agents that have the ability to incrementally improve their knowledge through the past experience. In this paper, we investigate the classification performance of a variety of algorithms that belong to various research field, i.e. Continual, Streaming and Online Learning, that receives as training input Natural Data Streams. The experimental validation is carried out on three different datasets, expressly organized to replicate this challenging setting.
Architect, Regularize and Replay (ARR): a Flexible Hybrid Approach for Continual Learning
Jan 06, 2023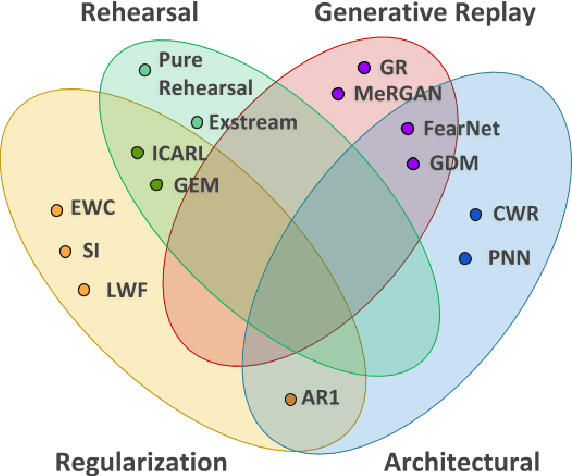
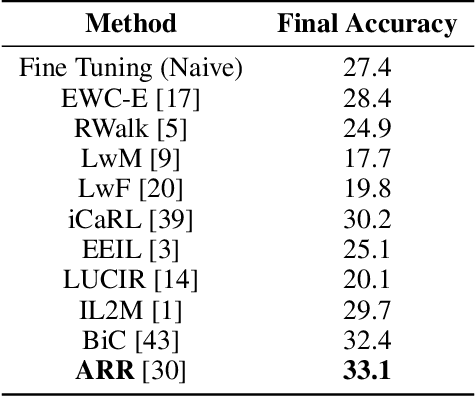
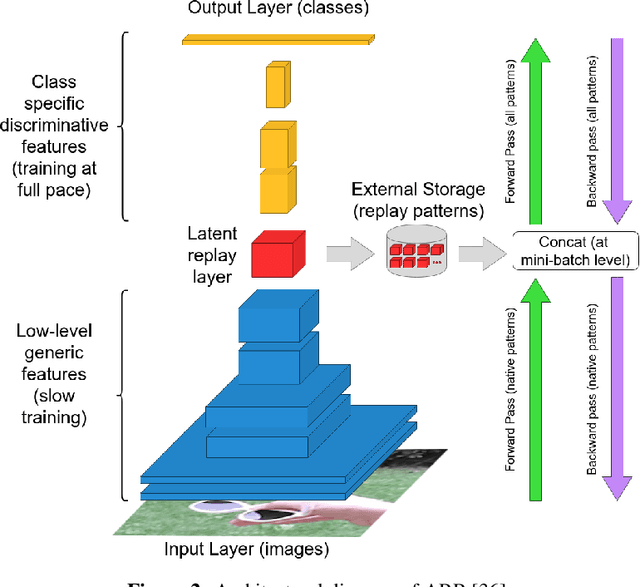
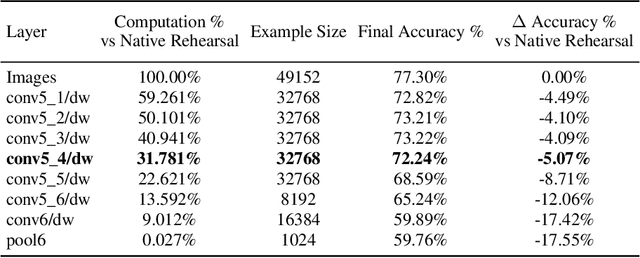
In recent years we have witnessed a renewed interest in machine learning methodologies, especially for deep representation learning, that could overcome basic i.i.d. assumptions and tackle non-stationary environments subject to various distributional shifts or sample selection biases. Within this context, several computational approaches based on architectural priors, regularizers and replay policies have been proposed with different degrees of success depending on the specific scenario in which they were developed and assessed. However, designing comprehensive hybrid solutions that can flexibly and generally be applied with tunable efficiency-effectiveness trade-offs still seems a distant goal. In this paper, we propose "Architect, Regularize and Replay" (ARR), an hybrid generalization of the renowned AR1 algorithm and its variants, that can achieve state-of-the-art results in classic scenarios (e.g. class-incremental learning) but also generalize to arbitrary data streams generated from real-world datasets such as CIFAR-100, CORe50 and ImageNet-1000.
Generative Negative Replay for Continual Learning
Apr 12, 2022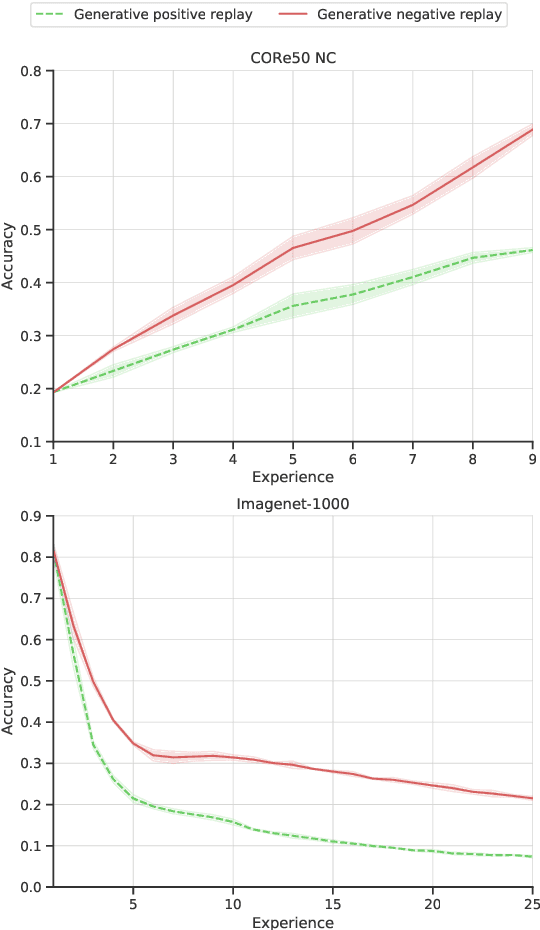
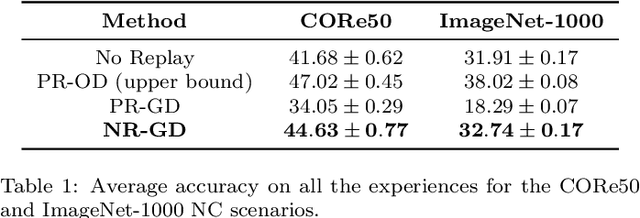

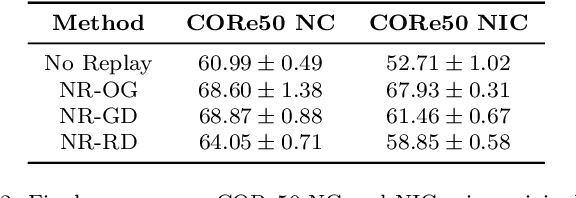
Learning continually is a key aspect of intelligence and a necessary ability to solve many real-life problems. One of the most effective strategies to control catastrophic forgetting, the Achilles' heel of continual learning, is storing part of the old data and replaying them interleaved with new experiences (also known as the replay approach). Generative replay, which is using generative models to provide replay patterns on demand, is particularly intriguing, however, it was shown to be effective mainly under simplified assumptions, such as simple scenarios and low-dimensional data. In this paper, we show that, while the generated data are usually not able to improve the classification accuracy for the old classes, they can be effective as negative examples (or antagonists) to better learn the new classes, especially when the learning experiences are small and contain examples of just one or few classes. The proposed approach is validated on complex class-incremental and data-incremental continual learning scenarios (CORe50 and ImageNet-1000) composed of high-dimensional data and a large number of training experiences: a setup where existing generative replay approaches usually fail.
Is Class-Incremental Enough for Continual Learning?
Dec 06, 2021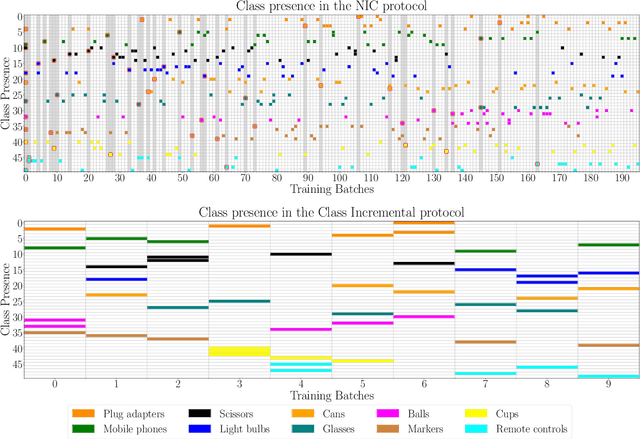
The ability of a model to learn continually can be empirically assessed in different continual learning scenarios. Each scenario defines the constraints and the opportunities of the learning environment. Here, we challenge the current trend in the continual learning literature to experiment mainly on class-incremental scenarios, where classes present in one experience are never revisited. We posit that an excessive focus on this setting may be limiting for future research on continual learning, since class-incremental scenarios artificially exacerbate catastrophic forgetting, at the expense of other important objectives like forward transfer and computational efficiency. In many real-world environments, in fact, repetition of previously encountered concepts occurs naturally and contributes to softening the disruption of previous knowledge. We advocate for a more in-depth study of alternative continual learning scenarios, in which repetition is integrated by design in the stream of incoming information. Starting from already existing proposals, we describe the advantages such class-incremental with repetition scenarios could offer for a more comprehensive assessment of continual learning models.
Continual Learning at the Edge: Real-Time Training on Smartphone Devices
May 24, 2021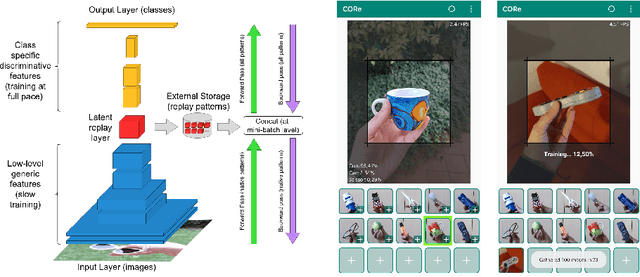


On-device training for personalized learning is a challenging research problem. Being able to quickly adapt deep prediction models at the edge is necessary to better suit personal user needs. However, adaptation on the edge poses some questions on both the efficiency and sustainability of the learning process and on the ability to work under shifting data distributions. Indeed, naively fine-tuning a prediction model only on the newly available data results in catastrophic forgetting, a sudden erasure of previously acquired knowledge. In this paper, we detail the implementation and deployment of a hybrid continual learning strategy (AR1*) on a native Android application for real-time on-device personalization without forgetting. Our benchmark, based on an extension of the CORe50 dataset, shows the efficiency and effectiveness of our solution.
Avalanche: an End-to-End Library for Continual Learning
Apr 01, 2021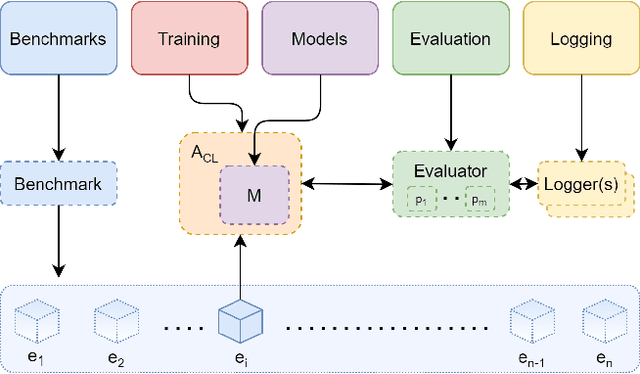

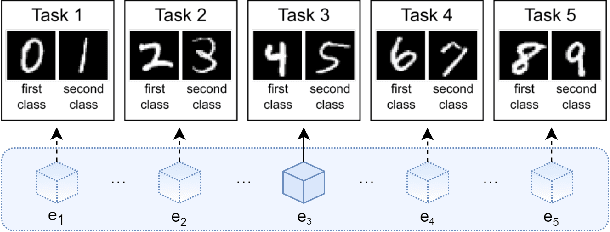

Learning continually from non-stationary data streams is a long-standing goal and a challenging problem in machine learning. Recently, we have witnessed a renewed and fast-growing interest in continual learning, especially within the deep learning community. However, algorithmic solutions are often difficult to re-implement, evaluate and port across different settings, where even results on standard benchmarks are hard to reproduce. In this work, we propose Avalanche, an open-source end-to-end library for continual learning research based on PyTorch. Avalanche is designed to provide a shared and collaborative codebase for fast prototyping, training, and reproducible evaluation of continual learning algorithms.
IROS 2019 Lifelong Robotic Vision Challenge -- Lifelong Object Recognition Report
Apr 26, 2020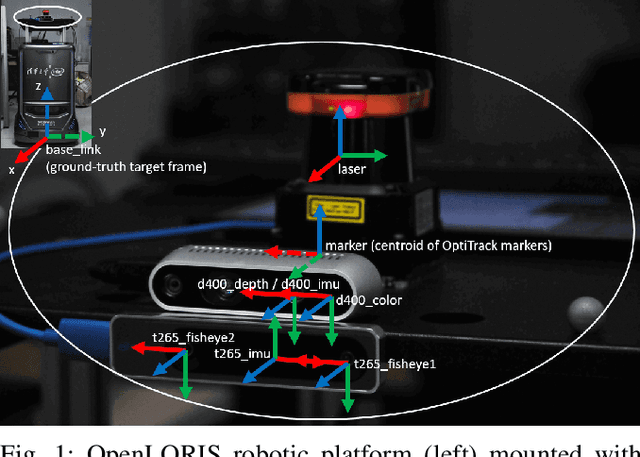
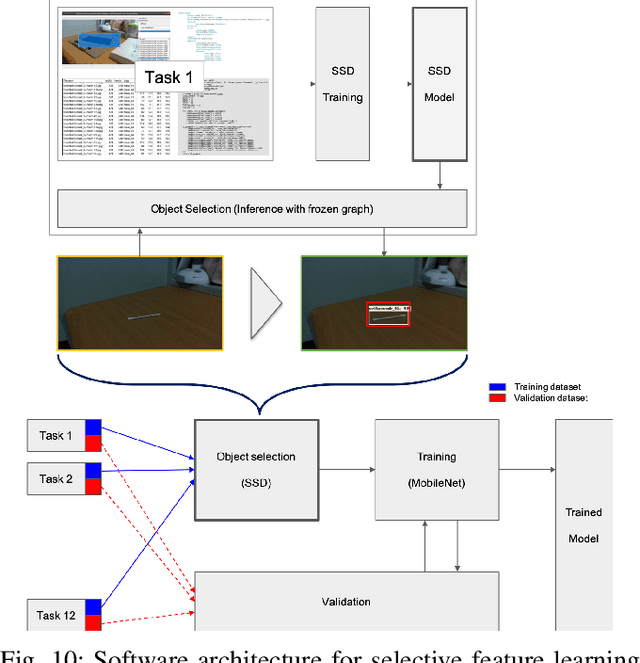
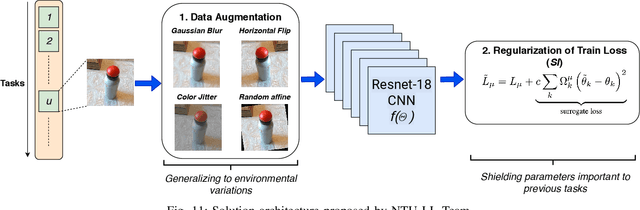

This report summarizes IROS 2019-Lifelong Robotic Vision Competition (Lifelong Object Recognition Challenge) with methods and results from the top $8$ finalists (out of over~$150$ teams). The competition dataset (L)ifel(O)ng (R)obotic V(IS)ion (OpenLORIS) - Object Recognition (OpenLORIS-object) is designed for driving lifelong/continual learning research and application in robotic vision domain, with everyday objects in home, office, campus, and mall scenarios. The dataset explicitly quantifies the variants of illumination, object occlusion, object size, camera-object distance/angles, and clutter information. Rules are designed to quantify the learning capability of the robotic vision system when faced with the objects appearing in the dynamic environments in the contest. Individual reports, dataset information, rules, and released source code can be found at the project homepage: "https://lifelong-robotic-vision.github.io/competition/".