 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModular Memory is the Key to Continual Learning Agents
Mar 02, 2026Foundation models have transformed machine learning through large-scale pretraining and increased test-time compute. Despite surpassing human performance in several domains, these models remain fundamentally limited in continuous operation, experience accumulation, and personalization, capabilities that are central to adaptive intelligence. While continual learning research has long targeted these goals, its historical focus on in-weight learning (IWL), i.e., updating a single model's parameters to absorb new knowledge, has rendered catastrophic forgetting a persistent challenge. Our position is that combining the strengths of In-Weight Learning (IWL) and the newly emerged capabilities of In-Context Learning (ICL) through the design of modular memory is the missing piece for continual adaptation at scale. We outline a conceptual framework for modular memory-centric architectures that leverage ICL for rapid adaptation and knowledge accumulation, and IWL for stable updates to model capabilities, charting a practical roadmap toward continually learning agents.
Quantifying the Role of OpenFold Components in Protein Structure Prediction
Nov 06, 2025Models such as AlphaFold2 and OpenFold have transformed protein structure prediction, yet their inner workings remain poorly understood. We present a methodology to systematically evaluate the contribution of individual OpenFold components to structure prediction accuracy. We identify several components that are critical for most proteins, while others vary in importance across proteins. We further show that the contribution of several components is correlated with protein length. These findings provide insight into how OpenFold achieves accurate predictions and highlight directions for interpreting protein prediction networks more broadly.
What could go wrong? Discovering and describing failure modes in computer vision
Aug 08, 2024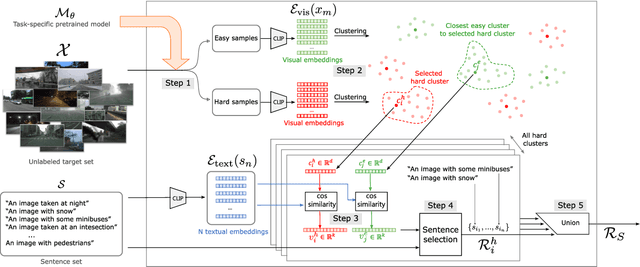
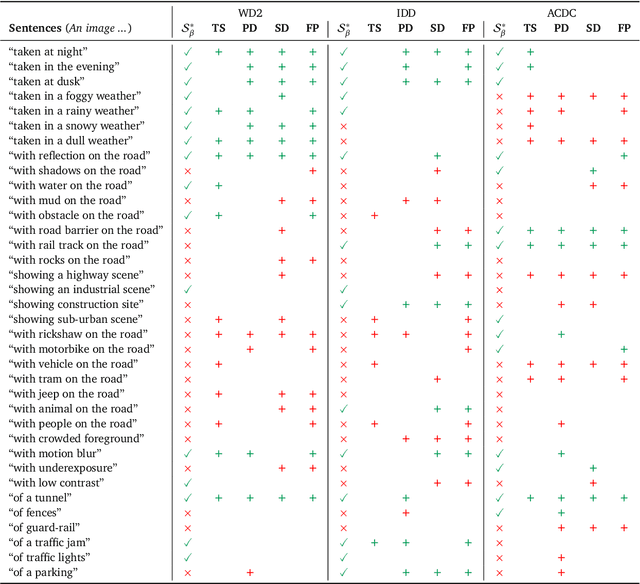
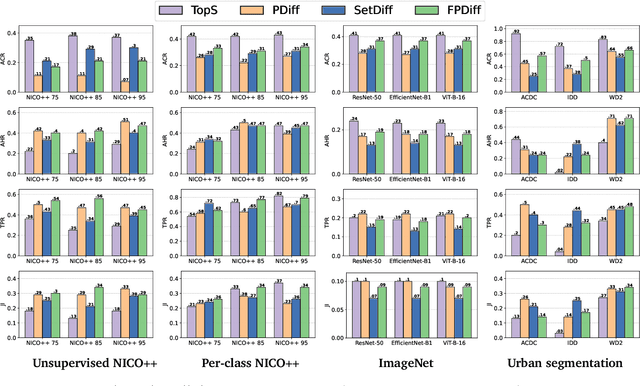

Deep learning models are effective, yet brittle. Even carefully trained, their behavior tends to be hard to predict when confronted with out-of-distribution samples. In this work, our goal is to propose a simple yet effective solution to predict and describe via natural language potential failure modes of computer vision models. Given a pretrained model and a set of samples, our aim is to find sentences that accurately describe the visual conditions in which the model underperforms. In order to study this important topic and foster future research on it, we formalize the problem of Language-Based Error Explainability (LBEE) and propose a set of metrics to evaluate and compare different methods for this task. We propose solutions that operate in a joint vision-and-language embedding space, and can characterize through language descriptions model failures caused, e.g., by objects unseen during training or adverse visual conditions. We experiment with different tasks, such as classification under the presence of dataset bias and semantic segmentation in unseen environments, and show that the proposed methodology isolates nontrivial sentences associated with specific error causes. We hope our work will help practitioners better understand the behavior of models, increasing their overall safety and interpretability.
SHiNe: Semantic Hierarchy Nexus for Open-vocabulary Object Detection
May 16, 2024Open-vocabulary object detection (OvOD) has transformed detection into a language-guided task, empowering users to freely define their class vocabularies of interest during inference. However, our initial investigation indicates that existing OvOD detectors exhibit significant variability when dealing with vocabularies across various semantic granularities, posing a concern for real-world deployment. To this end, we introduce Semantic Hierarchy Nexus (SHiNe), a novel classifier that uses semantic knowledge from class hierarchies. It runs offline in three steps: i) it retrieves relevant super-/sub-categories from a hierarchy for each target class; ii) it integrates these categories into hierarchy-aware sentences; iii) it fuses these sentence embeddings to generate the nexus classifier vector. Our evaluation on various detection benchmarks demonstrates that SHiNe enhances robustness across diverse vocabulary granularities, achieving up to +31.9% mAP50 with ground truth hierarchies, while retaining improvements using hierarchies generated by large language models. Moreover, when applied to open-vocabulary classification on ImageNet-1k, SHiNe improves the CLIP zero-shot baseline by +2.8% accuracy. SHiNe is training-free and can be seamlessly integrated with any off-the-shelf OvOD detector, without incurring additional computational overhead during inference. The code is open source.
PANDAS: Prototype-based Novel Class Discovery and Detection
Feb 27, 2024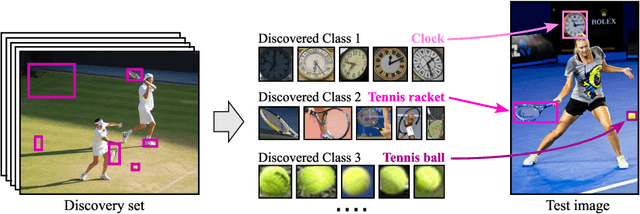
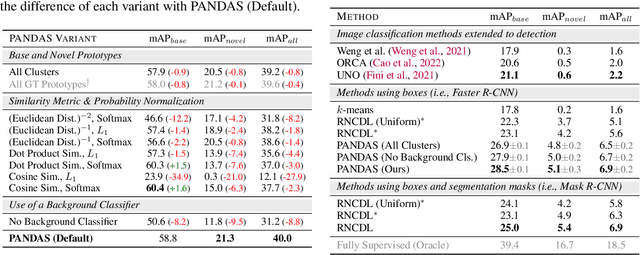
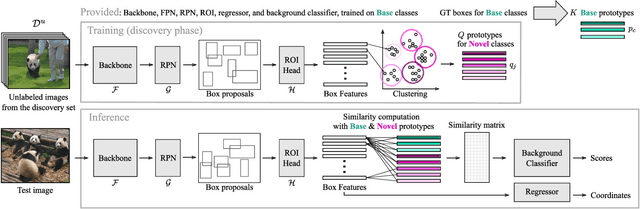

Object detectors are typically trained once and for all on a fixed set of classes. However, this closed-world assumption is unrealistic in practice, as new classes will inevitably emerge after the detector is deployed in the wild. In this work, we look at ways to extend a detector trained for a set of base classes so it can i) spot the presence of novel classes, and ii) automatically enrich its repertoire to be able to detect those newly discovered classes together with the base ones. We propose PANDAS, a method for novel class discovery and detection. It discovers clusters representing novel classes from unlabeled data, and represents old and new classes with prototypes. During inference, a distance-based classifier uses these prototypes to assign a label to each detected object instance. The simplicity of our method makes it widely applicable. We experimentally demonstrate the effectiveness of PANDAS on the VOC 2012 and COCO-to-LVIS benchmarks. It performs favorably against the state of the art for this task while being computationally more affordable.
Continual Learning: Applications and the Road Forward
Nov 21, 2023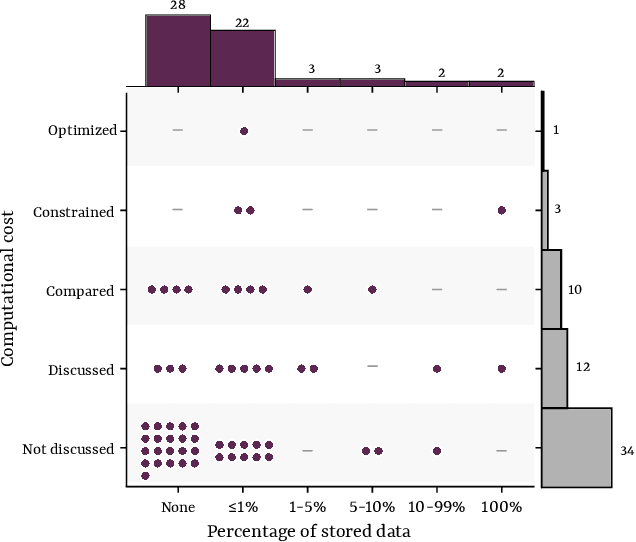
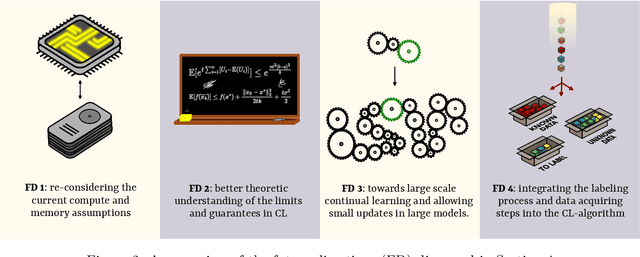
Continual learning is a sub-field of machine learning, which aims to allow machine learning models to continuously learn on new data, by accumulating knowledge without forgetting what was learned in the past. In this work, we take a step back, and ask: "Why should one care about continual learning in the first place?". We set the stage by surveying recent continual learning papers published at three major machine learning conferences, and show that memory-constrained settings dominate the field. Then, we discuss five open problems in machine learning, and even though they seem unrelated to continual learning at first sight, we show that continual learning will inevitably be part of their solution. These problems are model-editing, personalization, on-device learning, faster (re-)training and reinforcement learning. Finally, by comparing the desiderata from these unsolved problems and the current assumptions in continual learning, we highlight and discuss four future directions for continual learning research. We hope that this work offers an interesting perspective on the future of continual learning, while displaying its potential value and the paths we have to pursue in order to make it successful. This work is the result of the many discussions the authors had at the Dagstuhl seminar on Deep Continual Learning, in March 2023.
How Efficient Are Today's Continual Learning Algorithms?
Apr 03, 2023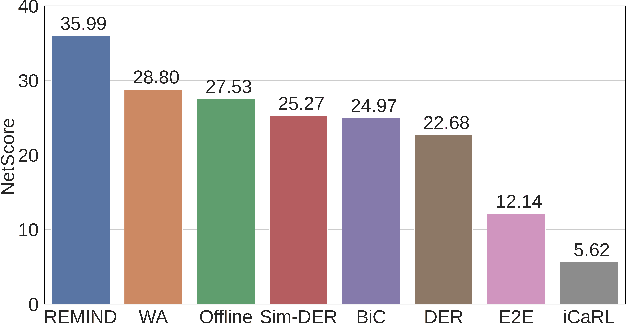
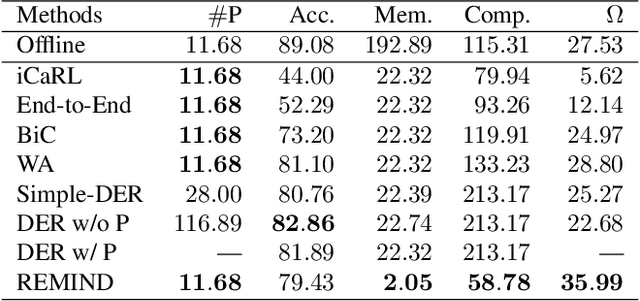
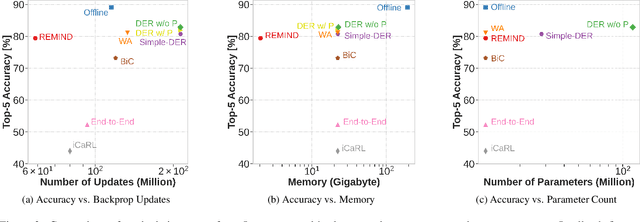
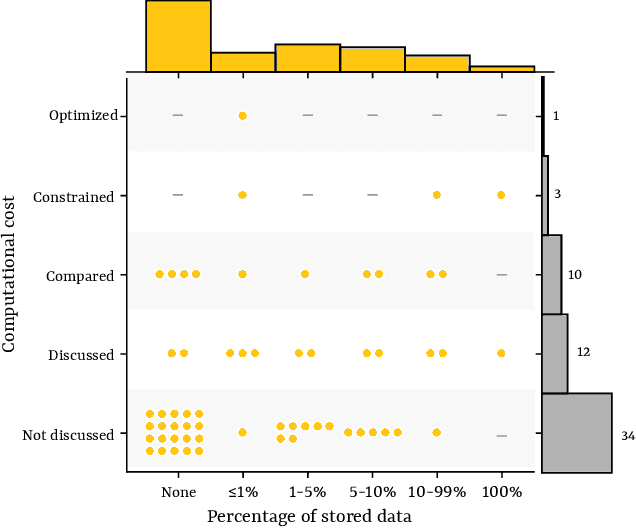
Supervised Continual learning involves updating a deep neural network (DNN) from an ever-growing stream of labeled data. While most work has focused on overcoming catastrophic forgetting, one of the major motivations behind continual learning is being able to efficiently update a network with new information, rather than retraining from scratch on the training dataset as it grows over time. Despite recent continual learning methods largely solving the catastrophic forgetting problem, there has been little attention paid to the efficiency of these algorithms. Here, we study recent methods for incremental class learning and illustrate that many are highly inefficient in terms of compute, memory, and storage. Some methods even require more compute than training from scratch! We argue that for continual learning to have real-world applicability, the research community cannot ignore the resources used by these algorithms. There is more to continual learning than mitigating catastrophic forgetting.
SIESTA: Efficient Online Continual Learning with Sleep
Mar 19, 2023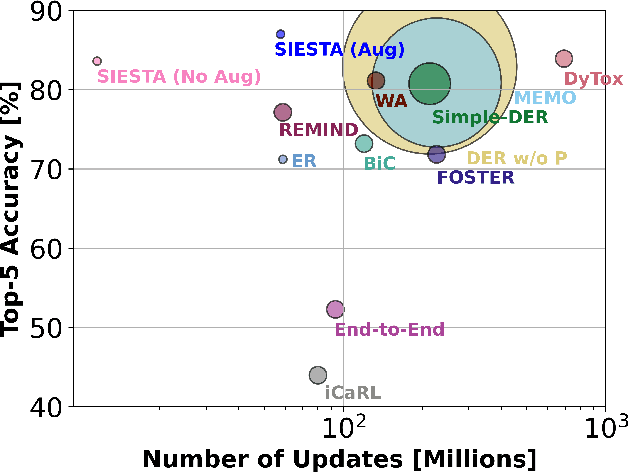
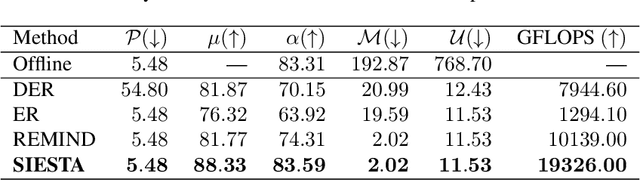
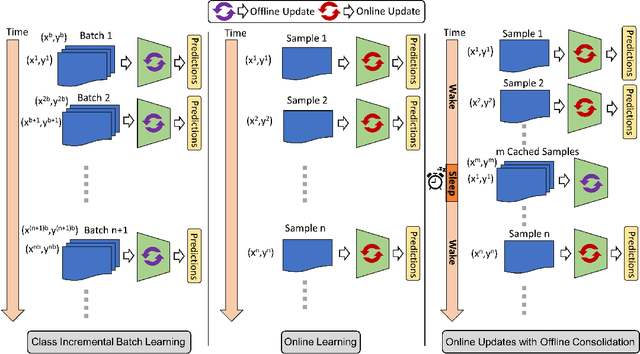

In supervised continual learning, a deep neural network (DNN) is updated with an ever-growing data stream. Unlike the offline setting where data is shuffled, we cannot make any distributional assumptions about the data stream. Ideally, only one pass through the dataset is needed for computational efficiency. However, existing methods are inadequate and make many assumptions that cannot be made for real-world applications, while simultaneously failing to improve computational efficiency. In this paper, we do not propose a novel method. Instead, we present SIESTA, an incremental improvement to the continual learning algorithm REMIND. Unlike REMIND, SIESTA uses a wake/sleep framework for training, which is well aligned to the needs of on-device learning. SIESTA is far more computationally efficient than existing methods, enabling continual learning on ImageNet-1K in under 3 hours on a single GPU; moreover, in the augmentation-free setting it matches the performance of the offline learner, a milestone critical to driving adoption of continual learning in real-world applications.
System Design for an Integrated Lifelong Reinforcement Learning Agent for Real-Time Strategy Games
Dec 08, 2022

As Artificial and Robotic Systems are increasingly deployed and relied upon for real-world applications, it is important that they exhibit the ability to continually learn and adapt in dynamically-changing environments, becoming Lifelong Learning Machines. Continual/lifelong learning (LL) involves minimizing catastrophic forgetting of old tasks while maximizing a model's capability to learn new tasks. This paper addresses the challenging lifelong reinforcement learning (L2RL) setting. Pushing the state-of-the-art forward in L2RL and making L2RL useful for practical applications requires more than developing individual L2RL algorithms; it requires making progress at the systems-level, especially research into the non-trivial problem of how to integrate multiple L2RL algorithms into a common framework. In this paper, we introduce the Lifelong Reinforcement Learning Components Framework (L2RLCF), which standardizes L2RL systems and assimilates different continual learning components (each addressing different aspects of the lifelong learning problem) into a unified system. As an instantiation of L2RLCF, we develop a standard API allowing easy integration of novel lifelong learning components. We describe a case study that demonstrates how multiple independently-developed LL components can be integrated into a single realized system. We also introduce an evaluation environment in order to measure the effect of combining various system components. Our evaluation environment employs different LL scenarios (sequences of tasks) consisting of Starcraft-2 minigames and allows for the fair, comprehensive, and quantitative comparison of different combinations of components within a challenging common evaluation environment.
Online Continual Learning for Embedded Devices
Mar 21, 2022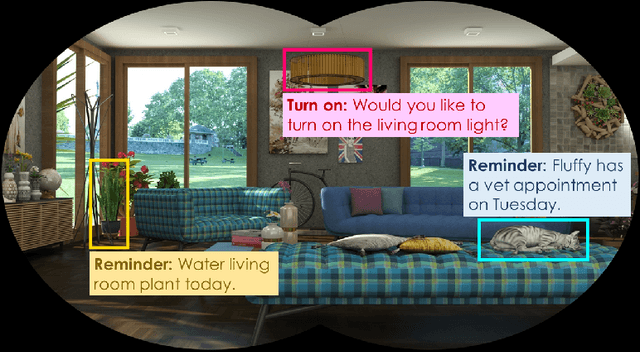
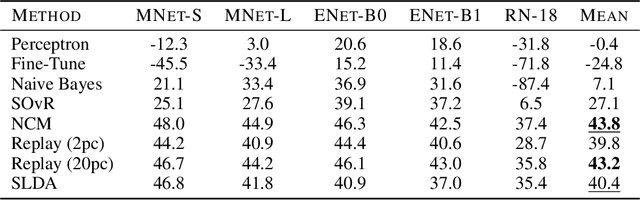

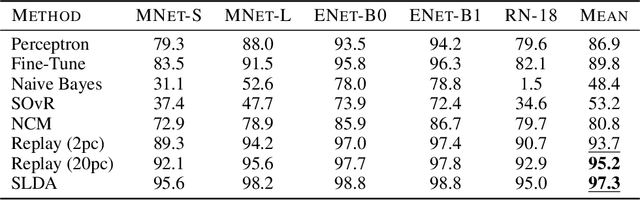
Real-time on-device continual learning is needed for new applications such as home robots, user personalization on smartphones, and augmented/virtual reality headsets. However, this setting poses unique challenges: embedded devices have limited memory and compute capacity and conventional machine learning models suffer from catastrophic forgetting when updated on non-stationary data streams. While several online continual learning models have been developed, their effectiveness for embedded applications has not been rigorously studied. In this paper, we first identify criteria that online continual learners must meet to effectively perform real-time, on-device learning. We then study the efficacy of several online continual learning methods when used with mobile neural networks. We measure their performance, memory usage, compute requirements, and ability to generalize to out-of-domain inputs.