 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Good Start Matters: Enhancing Continual Learning with Data-Driven Weight Initialization
Mar 09, 2025



To adapt to real-world data streams, continual learning (CL) systems must rapidly learn new concepts while preserving and utilizing prior knowledge. When it comes to adding new information to continually-trained deep neural networks (DNNs), classifier weights for newly encountered categories are typically initialized randomly, leading to high initial training loss (spikes) and instability. Consequently, achieving optimal convergence and accuracy requires prolonged training, increasing computational costs. Inspired by Neural Collapse (NC), we propose a weight initialization strategy to improve learning efficiency in CL. In DNNs trained with mean-squared-error, NC gives rise to a Least-Square (LS) classifier in the last layer, whose weights can be analytically derived from learned features. We leverage this LS formulation to initialize classifier weights in a data-driven manner, aligning them with the feature distribution rather than using random initialization. Our method mitigates initial loss spikes and accelerates adaptation to new tasks. We evaluate our approach in large-scale CL settings, demonstrating faster adaptation and improved CL performance.
Improving Multimodal Large Language Models Using Continual Learning
Oct 25, 2024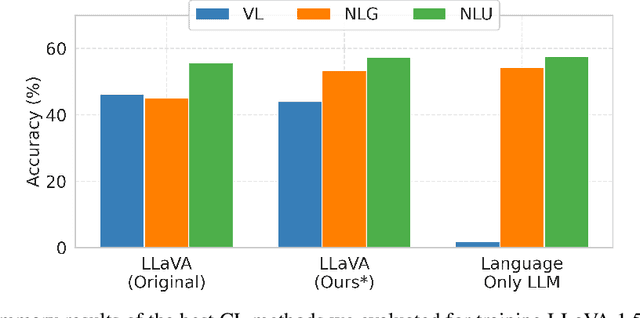
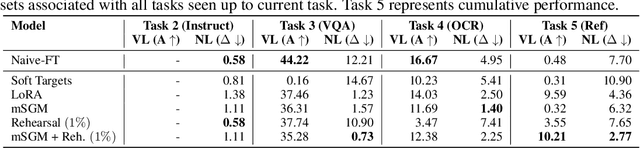
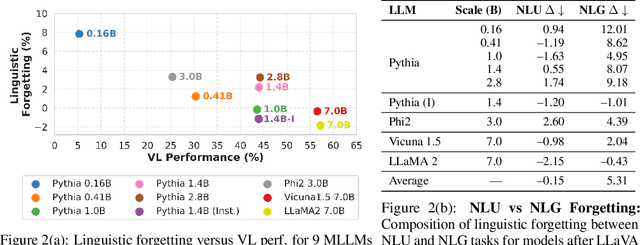
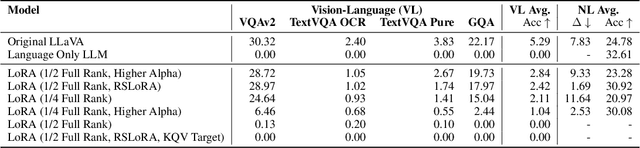
Generative large language models (LLMs) exhibit impressive capabilities, which can be further augmented by integrating a pre-trained vision model into the original LLM to create a multimodal LLM (MLLM). However, this integration often significantly decreases performance on natural language understanding and generation tasks, compared to the original LLM. This study investigates this issue using the LLaVA MLLM, treating the integration as a continual learning problem. We evaluate five continual learning methods to mitigate forgetting and identify a technique that enhances visual understanding while minimizing linguistic performance loss. Our approach reduces linguistic performance degradation by up to 15\% over the LLaVA recipe, while maintaining high multimodal accuracy. We also demonstrate the robustness of our method through continual learning on a sequence of vision-language tasks, effectively preserving linguistic skills while acquiring new multimodal capabilities.
What Variables Affect Out-Of-Distribution Generalization in Pretrained Models?
May 23, 2024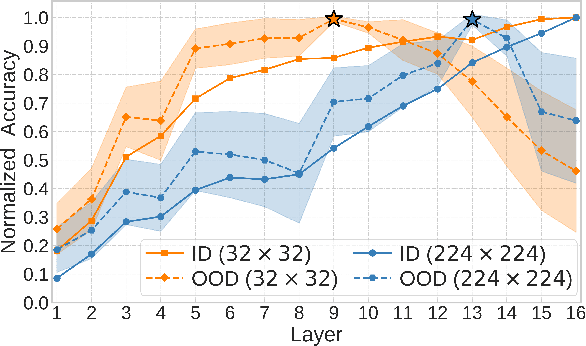
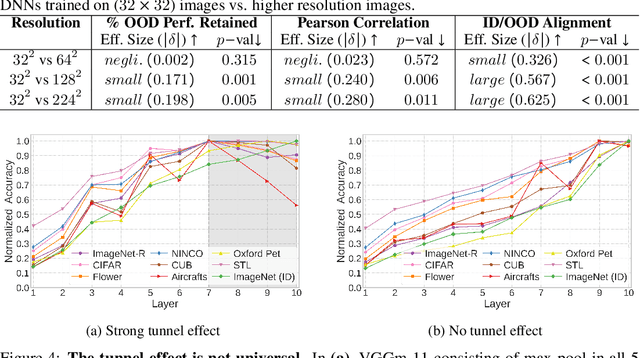

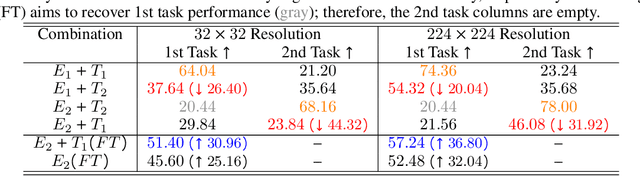
Embeddings produced by pre-trained deep neural networks (DNNs) are widely used; however, their efficacy for downstream tasks can vary widely. We study the factors influencing out-of-distribution (OOD) generalization of pre-trained DNN embeddings through the lens of the tunnel effect hypothesis, which suggests deeper DNN layers compress representations and hinder OOD performance. Contrary to earlier work, we find the tunnel effect is not universal. Based on 10,584 linear probes, we study the conditions that mitigate the tunnel effect by varying DNN architecture, training dataset, image resolution, and augmentations. We quantify each variable's impact using a novel SHAP analysis. Our results emphasize the danger of generalizing findings from toy datasets to broader contexts.
GRASP: A Rehearsal Policy for Efficient Online Continual Learning
Aug 25, 2023



Continual learning (CL) in deep neural networks (DNNs) involves incrementally accumulating knowledge in a DNN from a growing data stream. A major challenge in CL is that non-stationary data streams cause catastrophic forgetting of previously learned abilities. Rehearsal is a popular and effective way to mitigate this problem, which is storing past observations in a buffer and mixing them with new observations during learning. This leads to a question: Which stored samples should be selected for rehearsal? Choosing samples that are best for learning, rather than simply selecting them at random, could lead to significantly faster learning. For class incremental learning, prior work has shown that a simple class balanced random selection policy outperforms more sophisticated methods. Here, we revisit this question by exploring a new sample selection policy called GRASP. GRASP selects the most prototypical (class representative) samples first and then gradually selects less prototypical (harder) examples to update the DNN. GRASP has little additional compute or memory overhead compared to uniform selection, enabling it to scale to large datasets. We evaluate GRASP and other policies by conducting CL experiments on the large-scale ImageNet-1K and Places-LT image classification datasets. GRASP outperforms all other rehearsal policies. Beyond vision, we also demonstrate that GRASP is effective for CL on five text classification datasets.
Overcoming the Stability Gap in Continual Learning
Jun 02, 2023



In many real-world applications, deep neural networks are retrained from scratch as a dataset grows in size. Given the computational expense for retraining networks, it has been argued that continual learning could make updating networks more efficient. An obstacle to achieving this goal is the stability gap, which refers to an observation that when updating on new data, performance on previously learned data degrades before recovering. Addressing this problem would enable continual learning to learn new data with fewer network updates, resulting in increased computational efficiency. We study how to mitigate the stability gap in rehearsal (or experience replay), a widely employed continual learning method. We test a variety of hypotheses to understand why the stability gap occurs. This leads us to discover a method that vastly reduces this gap. In experiments on a large-scale incremental class learning setting, we are able to significantly reduce the number of network updates to recover performance. Our work has the potential to advance the state-of-the-art in continual learning for real-world applications along with reducing the carbon footprint required to maintain updated neural networks.
How Efficient Are Today's Continual Learning Algorithms?
Apr 03, 2023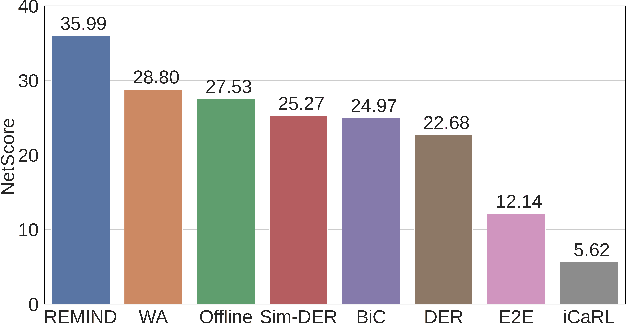
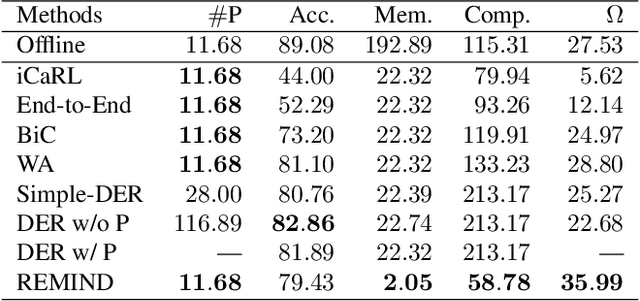
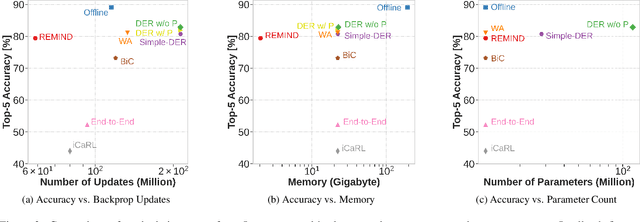
Supervised Continual learning involves updating a deep neural network (DNN) from an ever-growing stream of labeled data. While most work has focused on overcoming catastrophic forgetting, one of the major motivations behind continual learning is being able to efficiently update a network with new information, rather than retraining from scratch on the training dataset as it grows over time. Despite recent continual learning methods largely solving the catastrophic forgetting problem, there has been little attention paid to the efficiency of these algorithms. Here, we study recent methods for incremental class learning and illustrate that many are highly inefficient in terms of compute, memory, and storage. Some methods even require more compute than training from scratch! We argue that for continual learning to have real-world applicability, the research community cannot ignore the resources used by these algorithms. There is more to continual learning than mitigating catastrophic forgetting.
SIESTA: Efficient Online Continual Learning with Sleep
Mar 19, 2023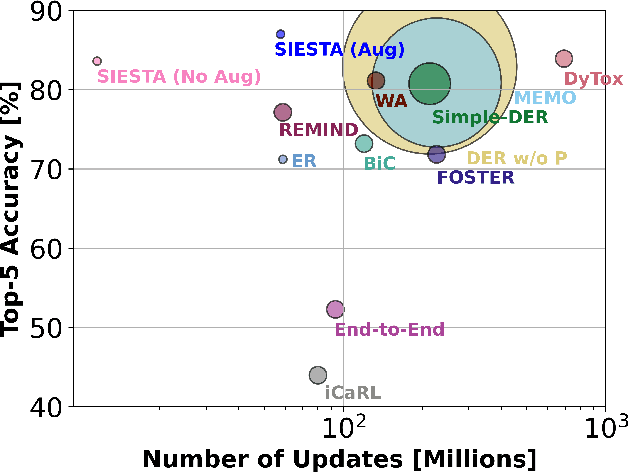
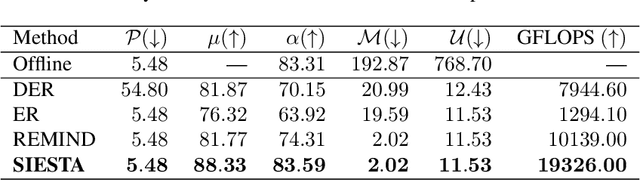
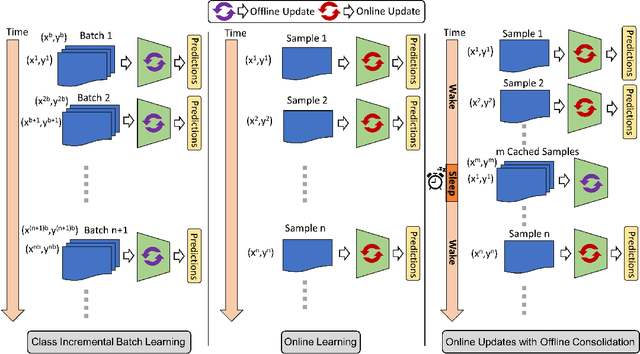

In supervised continual learning, a deep neural network (DNN) is updated with an ever-growing data stream. Unlike the offline setting where data is shuffled, we cannot make any distributional assumptions about the data stream. Ideally, only one pass through the dataset is needed for computational efficiency. However, existing methods are inadequate and make many assumptions that cannot be made for real-world applications, while simultaneously failing to improve computational efficiency. In this paper, we do not propose a novel method. Instead, we present SIESTA, an incremental improvement to the continual learning algorithm REMIND. Unlike REMIND, SIESTA uses a wake/sleep framework for training, which is well aligned to the needs of on-device learning. SIESTA is far more computationally efficient than existing methods, enabling continual learning on ImageNet-1K in under 3 hours on a single GPU; moreover, in the augmentation-free setting it matches the performance of the offline learner, a milestone critical to driving adoption of continual learning in real-world applications.
Inner Cell Mass and Trophectoderm Segmentation in Human Blastocyst Images using Deep Neural Network
Aug 19, 2020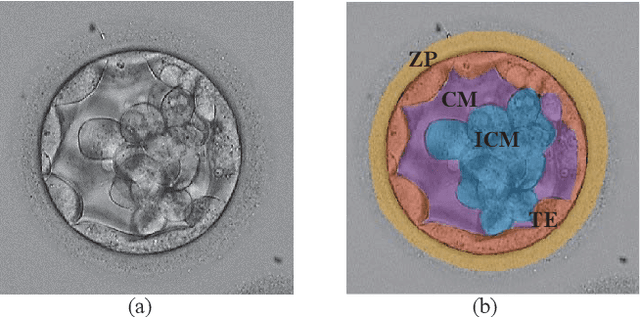


Embryo quality assessment based on morphological attributes is important for achieving higher pregnancy rates from in vitro fertilization (IVF). The accurate segmentation of the embryo's inner cell mass (ICM) and trophectoderm epithelium (TE) is important, as these parameters can help to predict the embryo viability and live birth potential. However, segmentation of the ICM and TE is difficult due to variations in their shape and similarities in their textures, both with each other and with their surroundings. To tackle this problem, a deep neural network (DNN) based segmentation approach was implemented. The DNN can identify the ICM region with 99.1% accuracy, 94.9% precision, 93.8% recall, a 94.3% Dice Coefficient, and a 89.3% Jaccard Index. It can extract the TE region with 98.3% accuracy, 91.8% precision, 93.2% recall, a 92.5% Dice Coefficient, and a 85.3% Jaccard Index.
Image Segmentation of Zona-Ablated Human Blastocysts
Aug 19, 2020

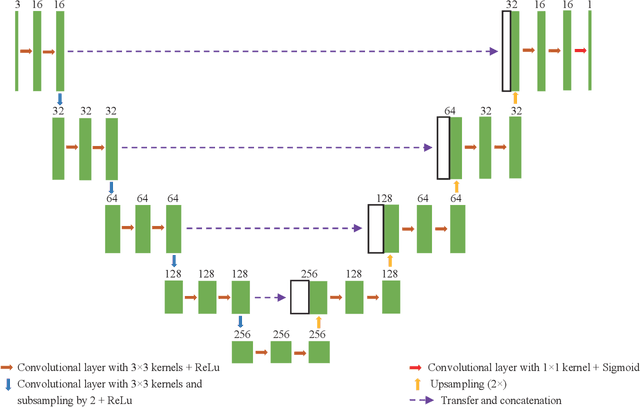
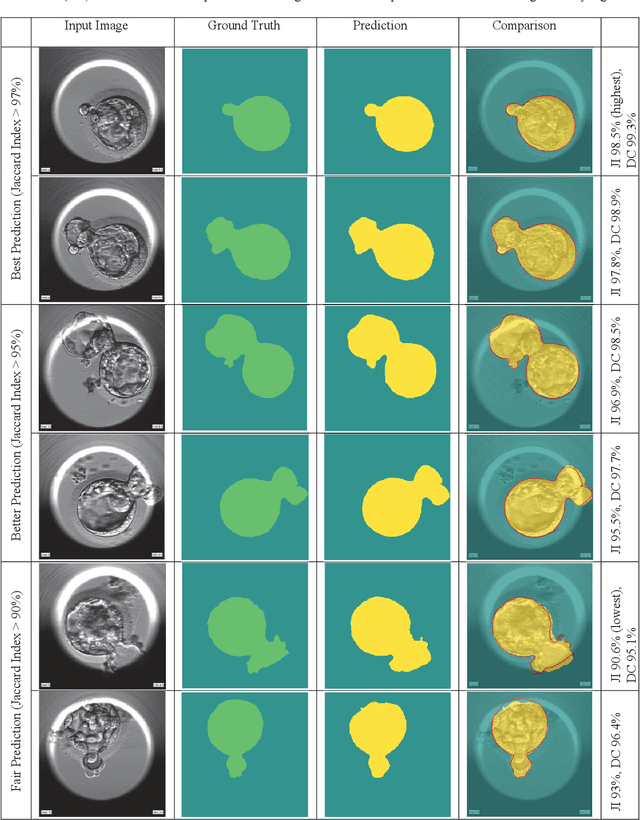
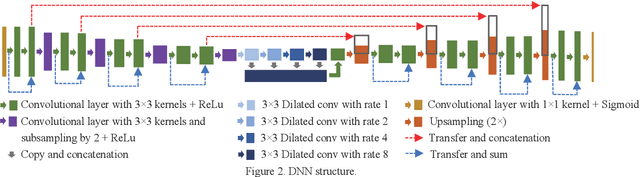
Automating human preimplantation embryo grading offers the potential for higher success rates with in vitro fertilization (IVF) by providing new quantitative and objective measures of embryo quality. Current IVF procedures typically use only qualitative manual grading, which is limited in the identification of genetically abnormal embryos. The automatic quantitative assessment of blastocyst expansion can potentially improve sustained pregnancy rates and reduce health risks from abnormal pregnancies through a more accurate identification of genetic abnormality. The expansion rate of a blastocyst is an important morphological feature to determine the quality of a developing embryo. In this work, a deep learning based human blastocyst image segmentation method is presented, with the goal of facilitating the challenging task of segmenting irregularly shaped blastocysts. The type of blastocysts evaluated here has undergone laser ablation of the zona pellucida, which is required prior to trophectoderm biopsy. This complicates the manual measurements of the expanded blastocyst's size, which shows a correlation with genetic abnormalities. The experimental results on the test set demonstrate segmentation greatly improves the accuracy of expansion measurements, resulting in up to 99.4% accuracy, 98.1% precision, 98.8% recall, a 98.4% Dice Coefficient, and a 96.9% Jaccard Index.