 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Variables Affect Out-Of-Distribution Generalization in Pretrained Models?
May 23, 2024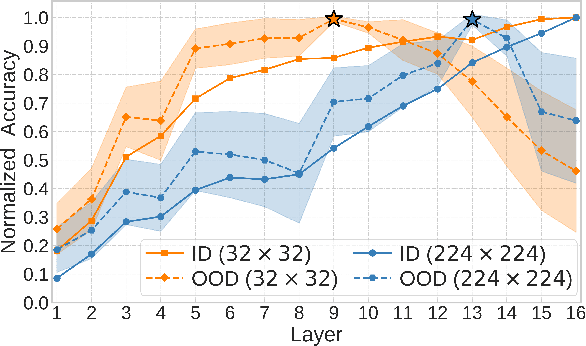
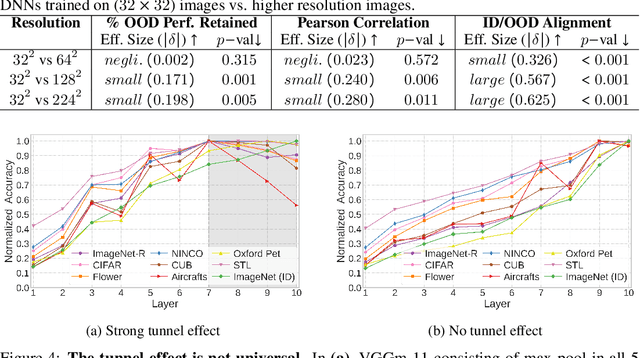

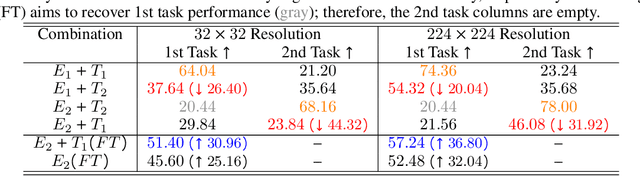
Embeddings produced by pre-trained deep neural networks (DNNs) are widely used; however, their efficacy for downstream tasks can vary widely. We study the factors influencing out-of-distribution (OOD) generalization of pre-trained DNN embeddings through the lens of the tunnel effect hypothesis, which suggests deeper DNN layers compress representations and hinder OOD performance. Contrary to earlier work, we find the tunnel effect is not universal. Based on 10,584 linear probes, we study the conditions that mitigate the tunnel effect by varying DNN architecture, training dataset, image resolution, and augmentations. We quantify each variable's impact using a novel SHAP analysis. Our results emphasize the danger of generalizing findings from toy datasets to broader contexts.
GRASP: A Rehearsal Policy for Efficient Online Continual Learning
Aug 25, 2023



Continual learning (CL) in deep neural networks (DNNs) involves incrementally accumulating knowledge in a DNN from a growing data stream. A major challenge in CL is that non-stationary data streams cause catastrophic forgetting of previously learned abilities. Rehearsal is a popular and effective way to mitigate this problem, which is storing past observations in a buffer and mixing them with new observations during learning. This leads to a question: Which stored samples should be selected for rehearsal? Choosing samples that are best for learning, rather than simply selecting them at random, could lead to significantly faster learning. For class incremental learning, prior work has shown that a simple class balanced random selection policy outperforms more sophisticated methods. Here, we revisit this question by exploring a new sample selection policy called GRASP. GRASP selects the most prototypical (class representative) samples first and then gradually selects less prototypical (harder) examples to update the DNN. GRASP has little additional compute or memory overhead compared to uniform selection, enabling it to scale to large datasets. We evaluate GRASP and other policies by conducting CL experiments on the large-scale ImageNet-1K and Places-LT image classification datasets. GRASP outperforms all other rehearsal policies. Beyond vision, we also demonstrate that GRASP is effective for CL on five text classification datasets.
How Efficient Are Today's Continual Learning Algorithms?
Apr 03, 2023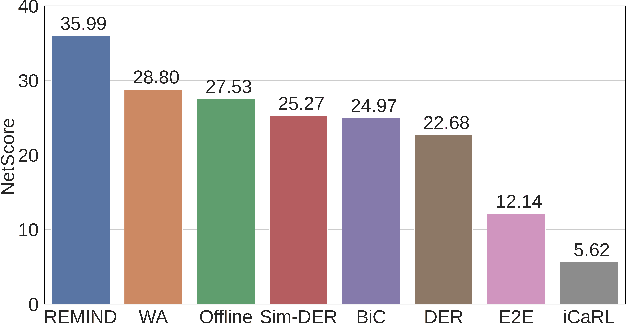
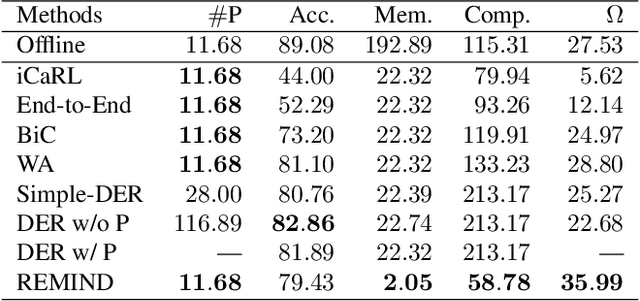
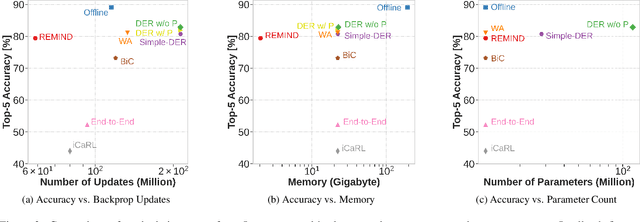
Supervised Continual learning involves updating a deep neural network (DNN) from an ever-growing stream of labeled data. While most work has focused on overcoming catastrophic forgetting, one of the major motivations behind continual learning is being able to efficiently update a network with new information, rather than retraining from scratch on the training dataset as it grows over time. Despite recent continual learning methods largely solving the catastrophic forgetting problem, there has been little attention paid to the efficiency of these algorithms. Here, we study recent methods for incremental class learning and illustrate that many are highly inefficient in terms of compute, memory, and storage. Some methods even require more compute than training from scratch! We argue that for continual learning to have real-world applicability, the research community cannot ignore the resources used by these algorithms. There is more to continual learning than mitigating catastrophic forgetting.
SIESTA: Efficient Online Continual Learning with Sleep
Mar 19, 2023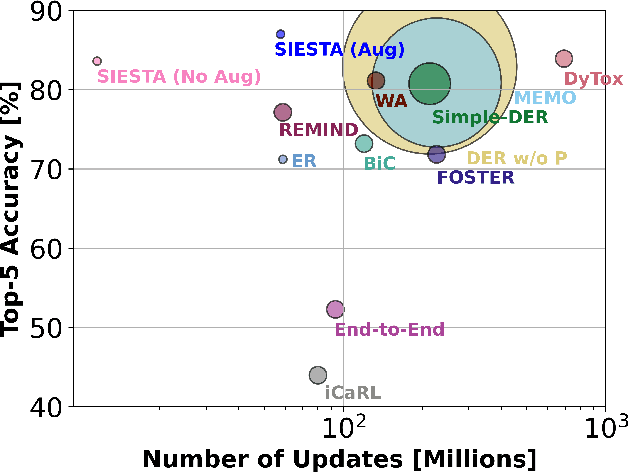
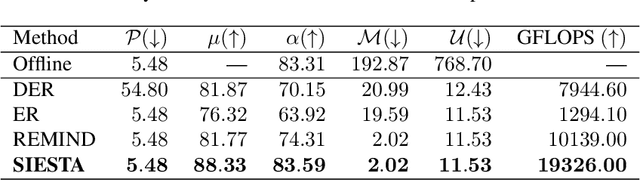
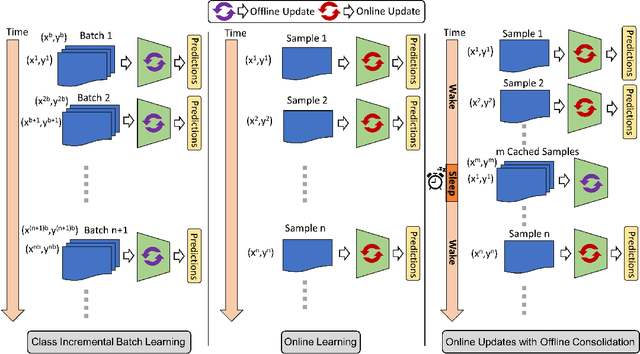

In supervised continual learning, a deep neural network (DNN) is updated with an ever-growing data stream. Unlike the offline setting where data is shuffled, we cannot make any distributional assumptions about the data stream. Ideally, only one pass through the dataset is needed for computational efficiency. However, existing methods are inadequate and make many assumptions that cannot be made for real-world applications, while simultaneously failing to improve computational efficiency. In this paper, we do not propose a novel method. Instead, we present SIESTA, an incremental improvement to the continual learning algorithm REMIND. Unlike REMIND, SIESTA uses a wake/sleep framework for training, which is well aligned to the needs of on-device learning. SIESTA is far more computationally efficient than existing methods, enabling continual learning on ImageNet-1K in under 3 hours on a single GPU; moreover, in the augmentation-free setting it matches the performance of the offline learner, a milestone critical to driving adoption of continual learning in real-world applications.
Self-Supervised Training Enhances Online Continual Learning
Mar 25, 2021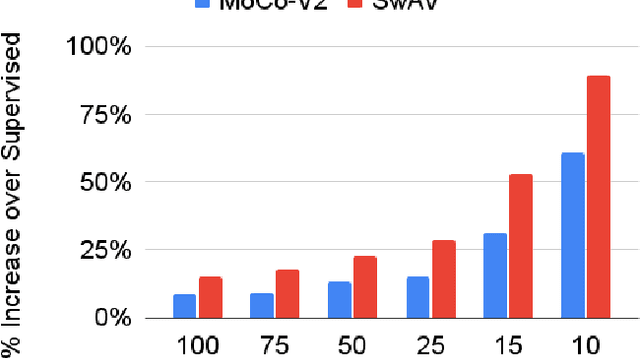

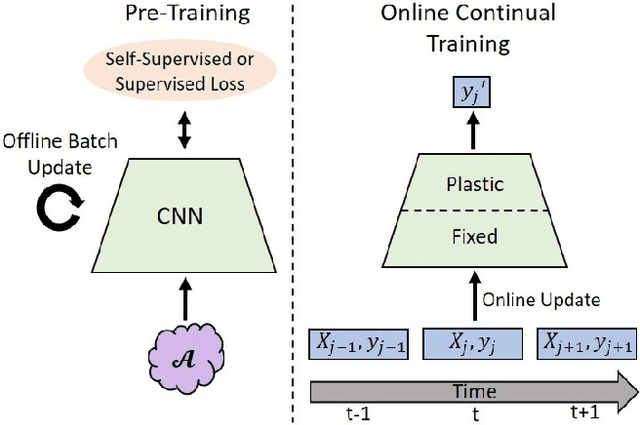

In continual learning, a system must incrementally learn from a non-stationary data stream without catastrophic forgetting. Recently, multiple methods have been devised for incrementally learning classes on large-scale image classification tasks, such as ImageNet. State-of-the-art continual learning methods use an initial supervised pre-training phase, in which the first 10% - 50% of the classes in a dataset are used to learn representations in an offline manner before continual learning of new classes begins. We hypothesize that self-supervised pre-training could yield features that generalize better than supervised learning, especially when the number of samples used for pre-training is small. We test this hypothesis using the self-supervised MoCo-V2 and SwAV algorithms. On ImageNet, we find that both outperform supervised pre-training considerably for online continual learning, and the gains are larger when fewer samples are available. Our findings are consistent across three continual learning algorithms. Our best system achieves a 14.95% relative increase in top-1 accuracy on class incremental ImageNet over the prior state of the art for online continual learning.