 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIESTA: Efficient Online Continual Learning with Sleep
Mar 19, 2023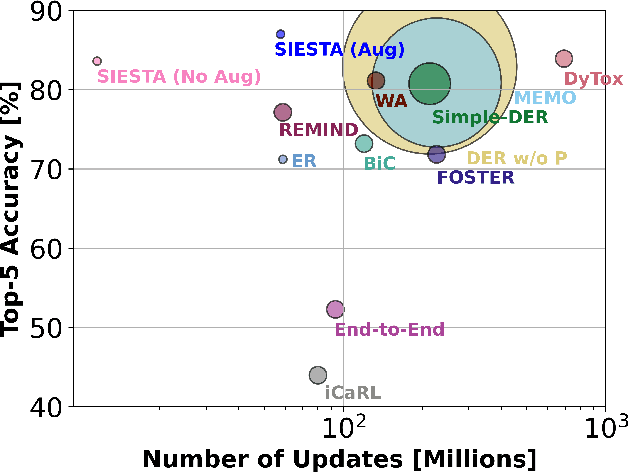
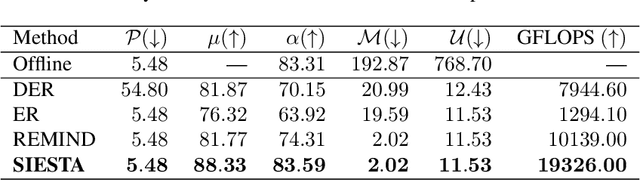
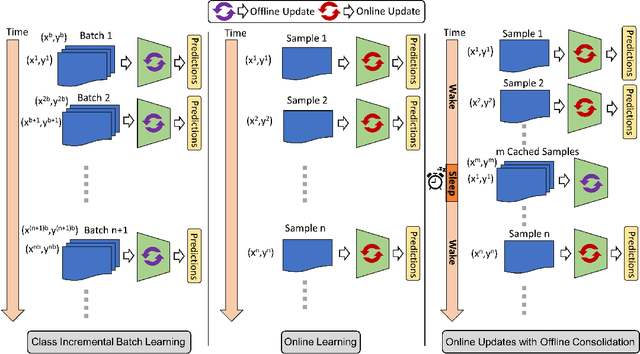

In supervised continual learning, a deep neural network (DNN) is updated with an ever-growing data stream. Unlike the offline setting where data is shuffled, we cannot make any distributional assumptions about the data stream. Ideally, only one pass through the dataset is needed for computational efficiency. However, existing methods are inadequate and make many assumptions that cannot be made for real-world applications, while simultaneously failing to improve computational efficiency. In this paper, we do not propose a novel method. Instead, we present SIESTA, an incremental improvement to the continual learning algorithm REMIND. Unlike REMIND, SIESTA uses a wake/sleep framework for training, which is well aligned to the needs of on-device learning. SIESTA is far more computationally efficient than existing methods, enabling continual learning on ImageNet-1K in under 3 hours on a single GPU; moreover, in the augmentation-free setting it matches the performance of the offline learner, a milestone critical to driving adoption of continual learning in real-world applications.
Are Out-of-Distribution Detection Methods Effective on Large-Scale Datasets?
Oct 30, 2019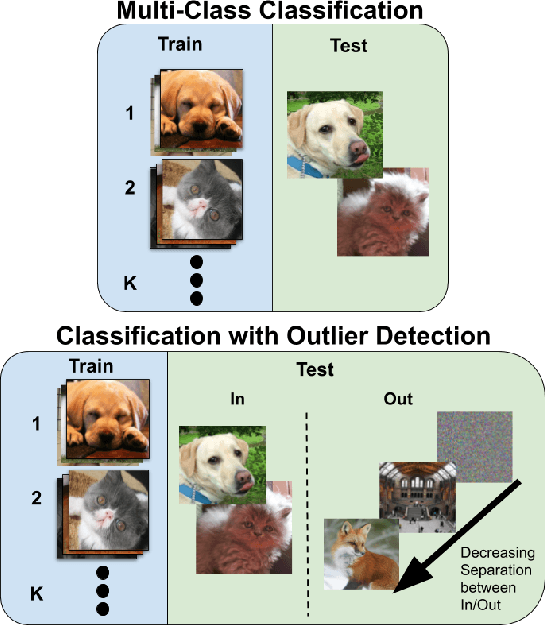

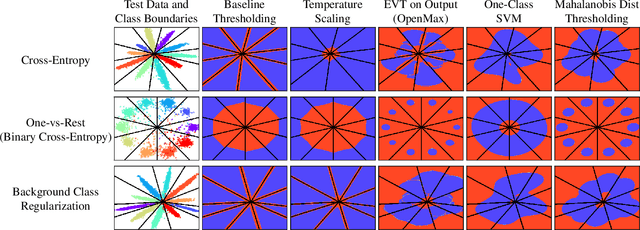
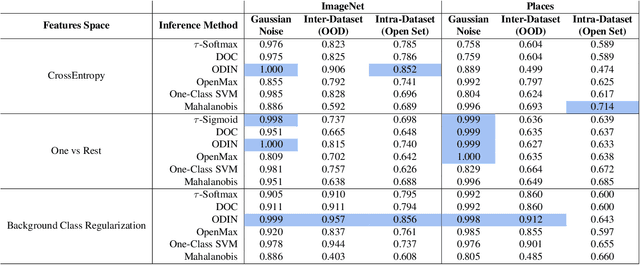
Supervised classification methods often assume the train and test data distributions are the same and that all classes in the test set are present in the training set. However, deployed classifiers often require the ability to recognize inputs from outside the training set as unknowns. This problem has been studied under multiple paradigms including out-of-distribution detection and open set recognition. For convolutional neural networks, there have been two major approaches: 1) inference methods to separate knowns from unknowns and 2) feature space regularization strategies to improve model robustness to outlier inputs. There has been little effort to explore the relationship between the two approaches and directly compare performance on anything other than small-scale datasets that have at most 100 categories. Using ImageNet-1K and Places-434, we identify novel combinations of regularization and specialized inference methods that perform best across multiple outlier detection problems of increasing difficulty level. We found that input perturbation and temperature scaling yield the best performance on large scale datasets regardless of the feature space regularization strategy. Improving the feature space by regularizing against a background class can be helpful if an appropriate background class can be found, but this is impractical for large scale image classification datasets.
Continual Lifelong Learning with Neural Networks: A Review
Jul 07, 2018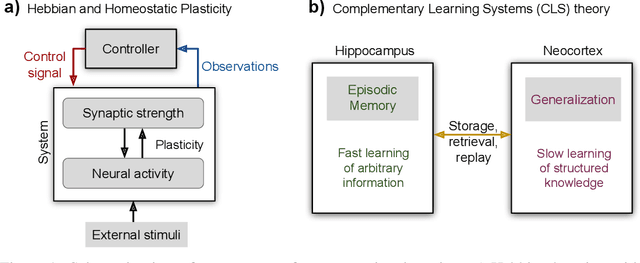
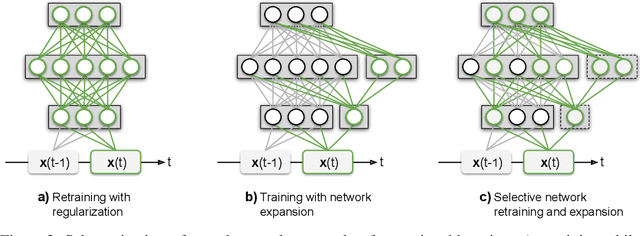

Humans and animals have the ability to continually acquire and fine-tune knowledge throughout their lifespan. This ability, referred to as lifelong learning, is mediated by a rich set of neurocognitive mechanisms that together contribute to the development and specialization of our sensorimotor skills as well as to the long-term memory consolidation and retrieval without catastrophic forgetting. Consequently, lifelong learning capabilities are crucial for computational learning systems and autonomous agents interacting in the real world and processing continuous streams of information. However, lifelong learning remains a long-standing challenge for machine learning and neural network models since the continual acquisition of incrementally available information from non-stationary data distributions generally leads to catastrophic forgetting or interference. This limitation represents a major drawback also for state-of-the-art deep and shallow neural network models that typically learn representations from stationary batches of training data, thus without accounting for situations in which the number of tasks is not known a priori and the information becomes incrementally available over time. In this review, we critically summarize the main challenges linked to lifelong learning for artificial learning systems and compare existing neural network approaches that alleviate, to different extents, catastrophic forgetting. Although significant advances have been made in domain-specific learning with neural networks, extensive research efforts are required for the development of robust lifelong learning on autonomous agents and robots. We discuss well-established and emerging research motivated by lifelong learning factors in biological systems such as neurosynaptic plasticity, multi-task transfer learning, intrinsically motivated exploration, and crossmodal learning.
Algorithms for Semantic Segmentation of Multispectral Remote Sensing Imagery using Deep Learning
May 01, 2018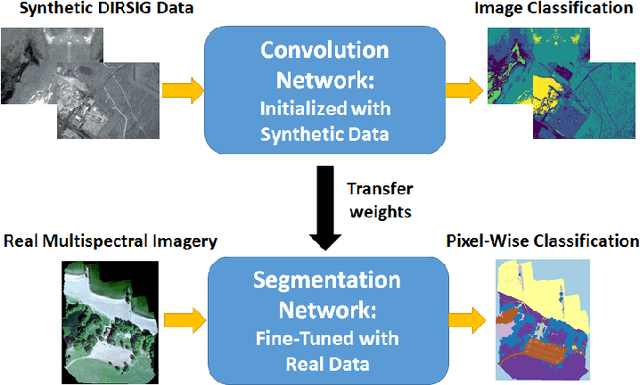

Deep convolutional neural networks (DCNNs) have been used to achieve state-of-the-art performance on many computer vision tasks (e.g., object recognition, object detection, semantic segmentation) thanks to a large repository of annotated image data. Large labeled datasets for other sensor modalities, e.g., multispectral imagery (MSI), are not available due to the large cost and manpower required. In this paper, we adapt state-of-the-art DCNN frameworks in computer vision for semantic segmentation for MSI imagery. To overcome label scarcity for MSI data, we substitute real MSI for generated synthetic MSI in order to initialize a DCNN framework. We evaluate our network initialization scheme on the new RIT-18 dataset that we present in this paper. This dataset contains very-high resolution MSI collected by an unmanned aircraft system. The models initialized with synthetic imagery were less prone to over-fitting and provide a state-of-the-art baseline for future work.
* 45 pages
EarthMapper: A Tool Box for the Semantic Segmentation of Remote Sensing Imagery
Apr 01, 2018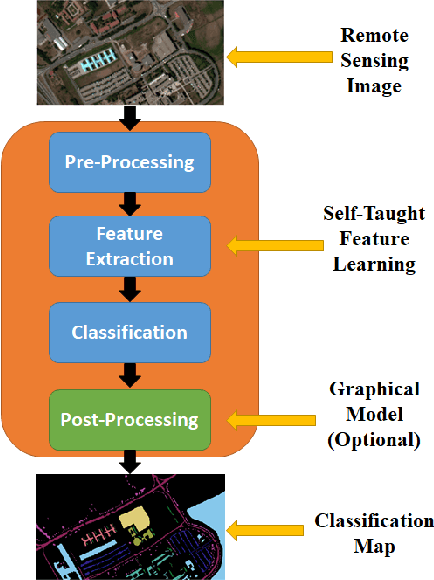
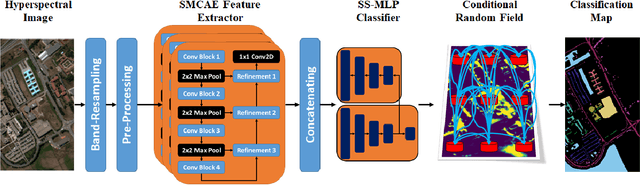
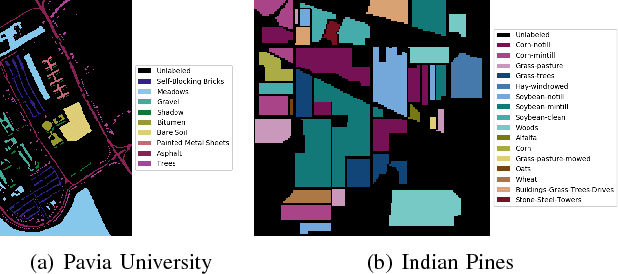
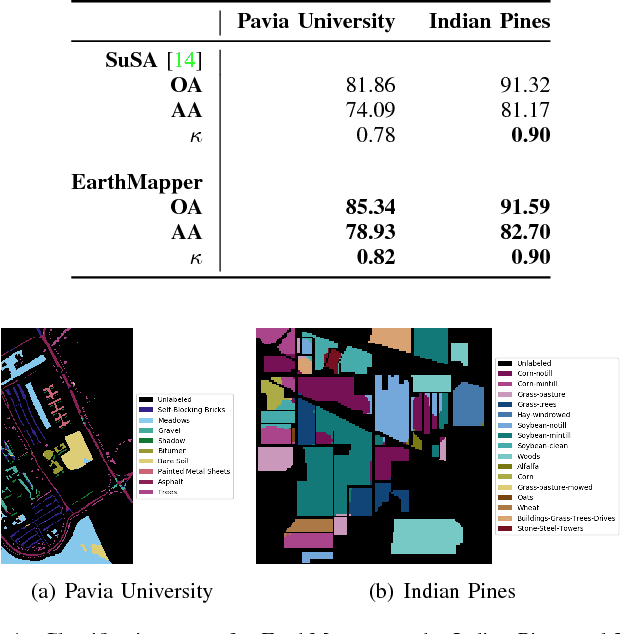
Deep learning continues to push state-of-the-art performance for the semantic segmentation of color (i.e., RGB) imagery; however, the lack of annotated data for many remote sensing sensors (i.e. hyperspectral imagery (HSI)) prevents researchers from taking advantage of this recent success. Since generating sensor specific datasets is time intensive and cost prohibitive, remote sensing researchers have embraced deep unsupervised feature extraction. Although these methods have pushed state-of-the-art performance on current HSI benchmarks, many of these tools are not readily accessible to many researchers. In this letter, we introduce a software pipeline, which we call EarthMapper, for the semantic segmentation of non-RGB remote sensing imagery. It includes self-taught spatial-spectral feature extraction, various standard and deep learning classifiers, and undirected graphical models for post-processing. We evaluated EarthMapper on the Indian Pines and Pavia University datasets and have released this code for public use.
Low-Shot Learning for the Semantic Segmentation of Remote Sensing Imagery
Mar 26, 2018
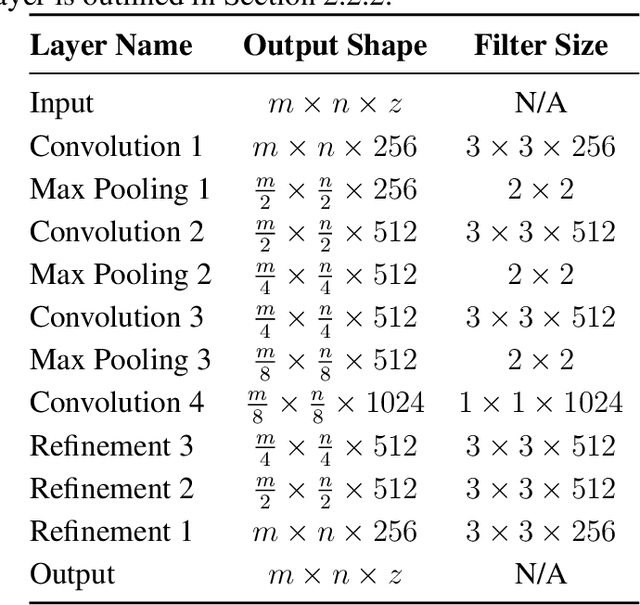
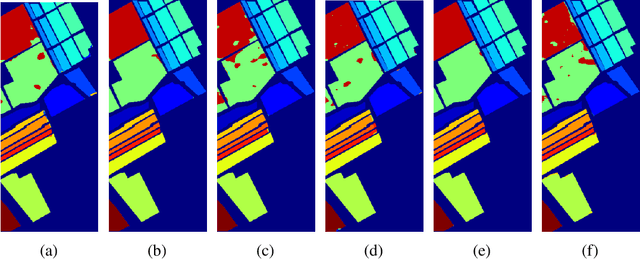
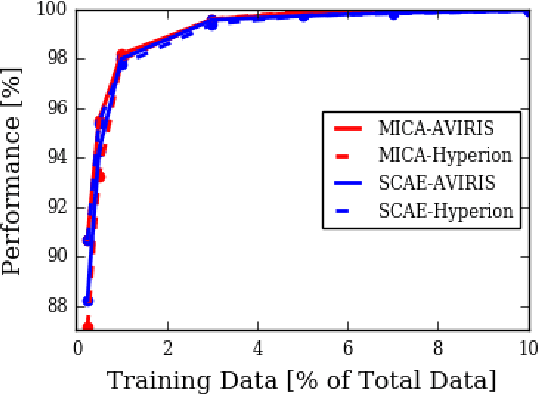
Recent advances in computer vision using deep learning with RGB imagery (e.g., object recognition and detection) have been made possible thanks to the development of large annotated RGB image datasets. In contrast, multispectral image (MSI) and hyperspectral image (HSI) datasets contain far fewer labeled images, in part due to the wide variety of sensors used. These annotations are especially limited for semantic segmentation, or pixel-wise classification, of remote sensing imagery because it is labor intensive to generate image annotations. Low-shot learning algorithms can make effective inferences despite smaller amounts of annotated data. In this paper, we study low-shot learning using self-taught feature learning for semantic segmentation. We introduce 1) an improved self-taught feature learning framework for HSI and MSI data and 2) a semi-supervised classification algorithm. When these are combined, they achieve state-of-the-art performance on remote sensing datasets that have little annotated training data available. These low-shot learning frameworks will reduce the manual image annotation burden and improve semantic segmentation performance for remote sensing imagery.
FearNet: Brain-Inspired Model for Incremental Learning
Feb 23, 2018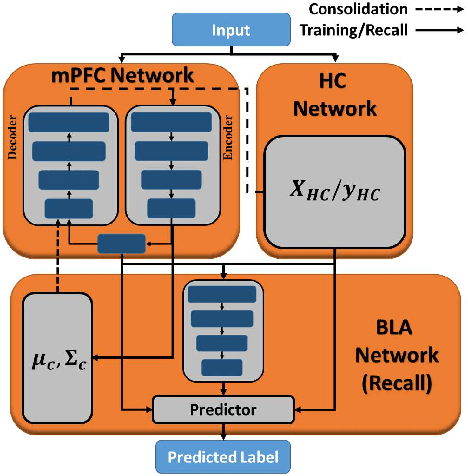
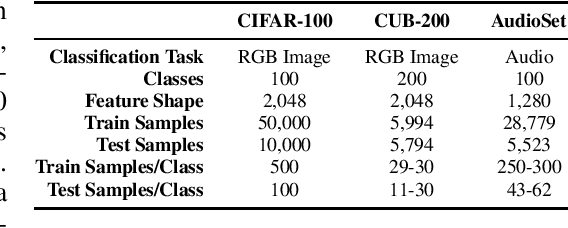
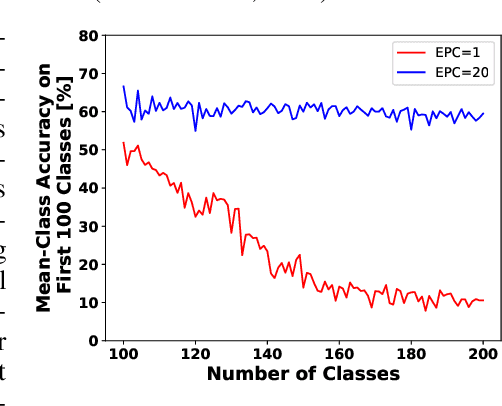
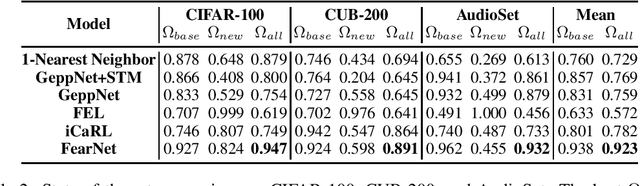
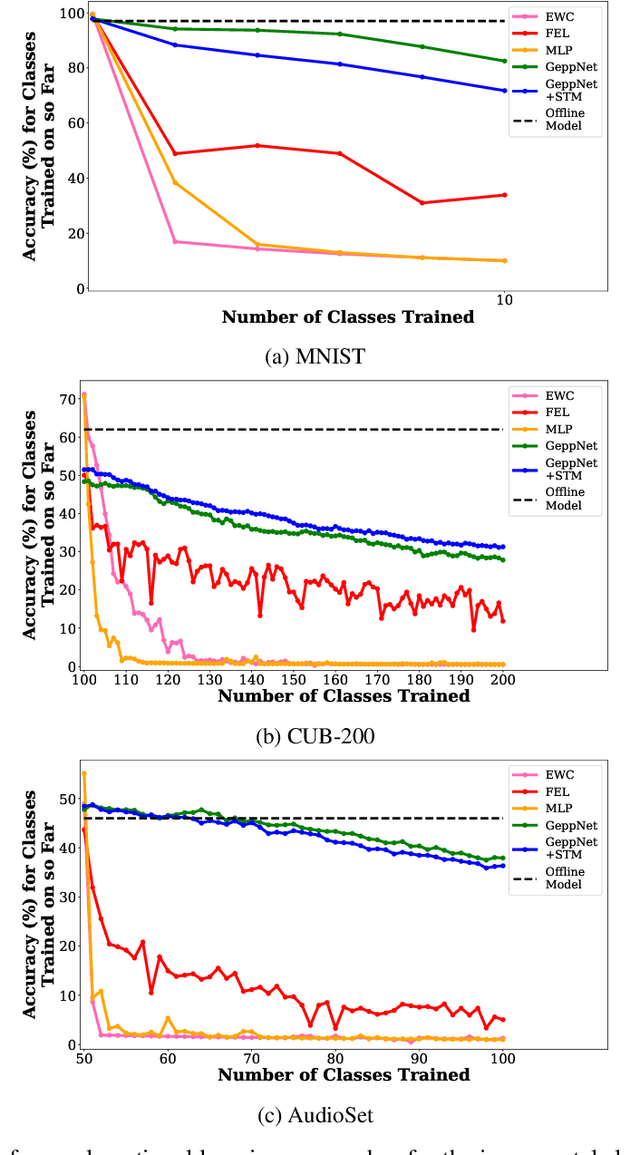
Incremental class learning involves sequentially learning classes in bursts of examples from the same class. This violates the assumptions that underlie methods for training standard deep neural networks, and will cause them to suffer from catastrophic forgetting. Arguably, the best method for incremental class learning is iCaRL, but it requires storing training examples for each class, making it challenging to scale. Here, we propose FearNet for incremental class learning. FearNet is a generative model that does not store previous examples, making it memory efficient. FearNet uses a brain-inspired dual-memory system in which new memories are consolidated from a network for recent memories inspired by the mammalian hippocampal complex to a network for long-term storage inspired by medial prefrontal cortex. Memory consolidation is inspired by mechanisms that occur during sleep. FearNet also uses a module inspired by the basolateral amygdala for determining which memory system to use for recall. FearNet achieves state-of-the-art performance at incremental class learning on image (CIFAR-100, CUB-200) and audio classification (AudioSet) benchmarks.
Measuring Catastrophic Forgetting in Neural Networks
Nov 09, 2017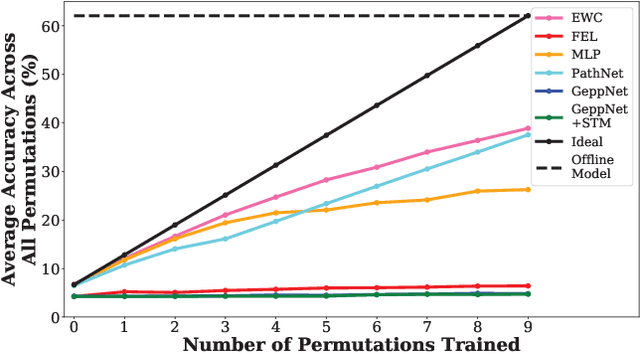
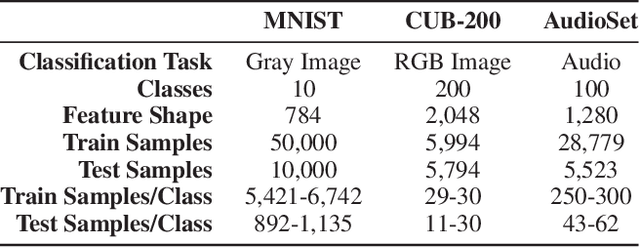
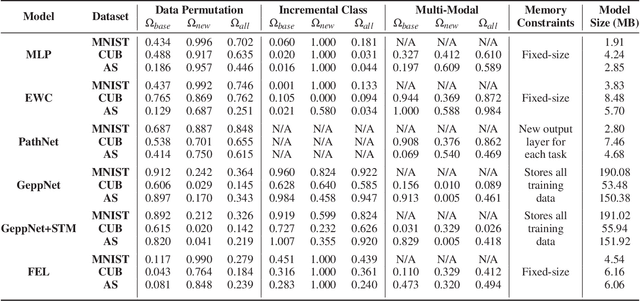
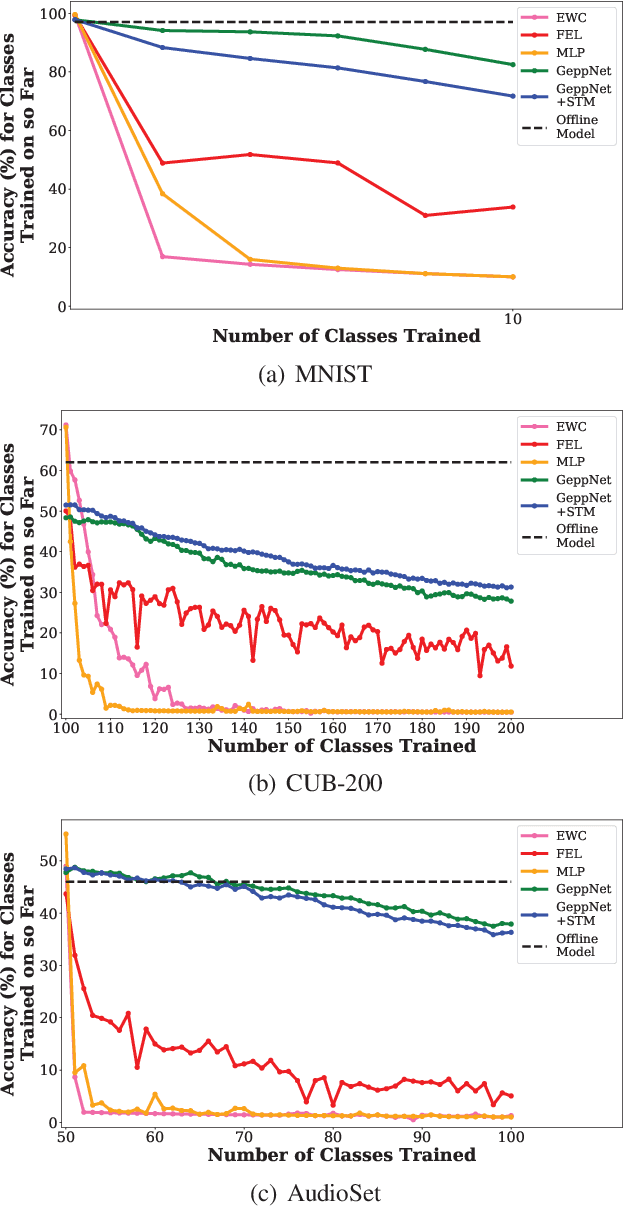
Deep neural networks are used in many state-of-the-art systems for machine perception. Once a network is trained to do a specific task, e.g., bird classification, it cannot easily be trained to do new tasks, e.g., incrementally learning to recognize additional bird species or learning an entirely different task such as flower recognition. When new tasks are added, typical deep neural networks are prone to catastrophically forgetting previous tasks. Networks that are capable of assimilating new information incrementally, much like how humans form new memories over time, will be more efficient than re-training the model from scratch each time a new task needs to be learned. There have been multiple attempts to develop schemes that mitigate catastrophic forgetting, but these methods have not been directly compared, the tests used to evaluate them vary considerably, and these methods have only been evaluated on small-scale problems (e.g., MNIST). In this paper, we introduce new metrics and benchmarks for directly comparing five different mechanisms designed to mitigate catastrophic forgetting in neural networks: regularization, ensembling, rehearsal, dual-memory, and sparse-coding. Our experiments on real-world images and sounds show that the mechanism(s) that are critical for optimal performance vary based on the incremental training paradigm and type of data being used, but they all demonstrate that the catastrophic forgetting problem has yet to be solved.
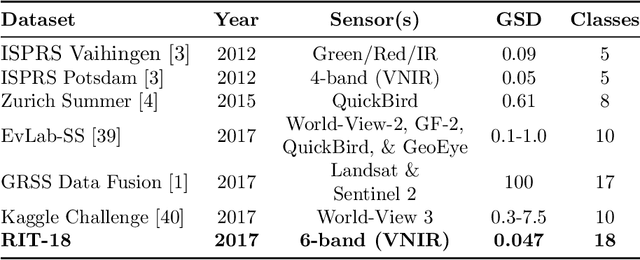
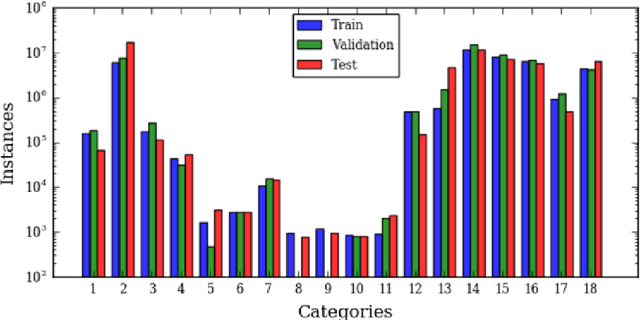
High-Resolution Multispectral Dataset for Semantic Segmentation
Mar 06, 2017
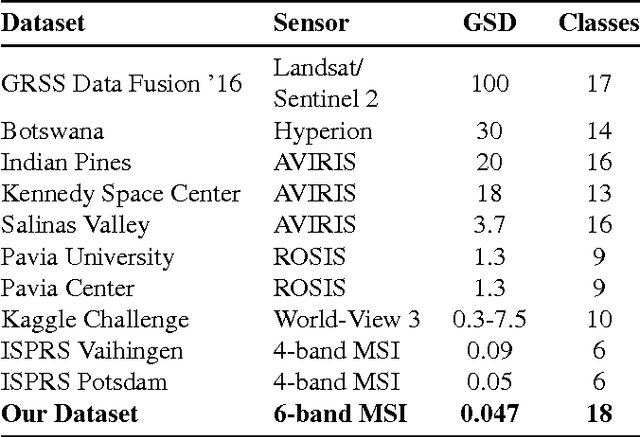


Unmanned aircraft have decreased the cost required to collect remote sensing imagery, which has enabled researchers to collect high-spatial resolution data from multiple sensor modalities more frequently and easily. The increase in data will push the need for semantic segmentation frameworks that are able to classify non-RGB imagery, but this type of algorithmic development requires an increase in publicly available benchmark datasets with class labels. In this paper, we introduce a high-resolution multispectral dataset with image labels. This new benchmark dataset has been pre-split into training/testing folds in order to standardize evaluation and continue to push state-of-the-art classification frameworks for non-RGB imagery.