 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Robustness to Open Set Inputs via Tempered Mixup
Sep 10, 2020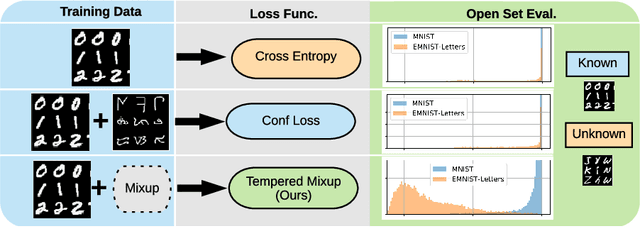
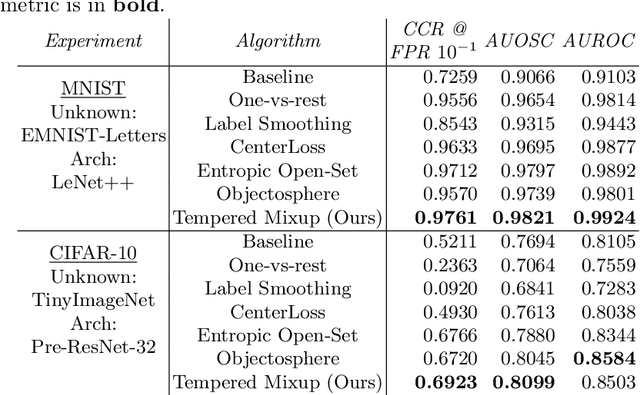
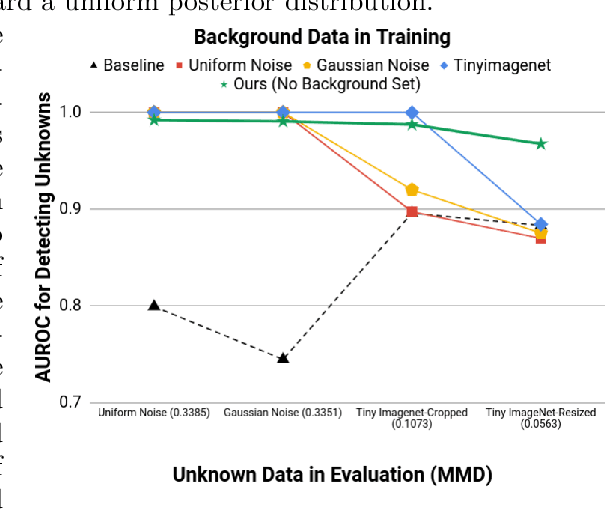
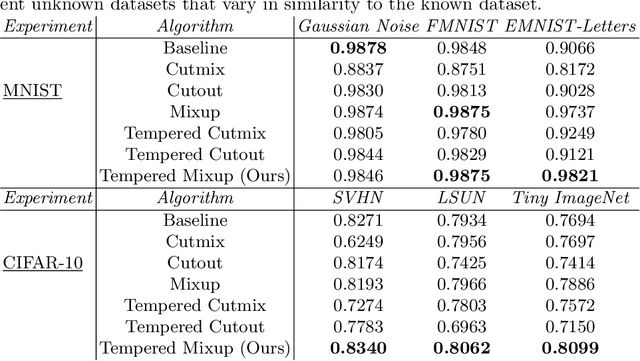
Supervised classification methods often assume that evaluation data is drawn from the same distribution as training data and that all classes are present for training. However, real-world classifiers must handle inputs that are far from the training distribution including samples from unknown classes. Open set robustness refers to the ability to properly label samples from previously unseen categories as novel and avoid high-confidence, incorrect predictions. Existing approaches have focused on either novel inference methods, unique training architectures, or supplementing the training data with additional background samples. Here, we propose a simple regularization technique easily applied to existing convolutional neural network architectures that improves open set robustness without a background dataset. Our method achieves state-of-the-art results on open set classification baselines and easily scales to large-scale open set classification problems.
Are Out-of-Distribution Detection Methods Effective on Large-Scale Datasets?
Oct 30, 2019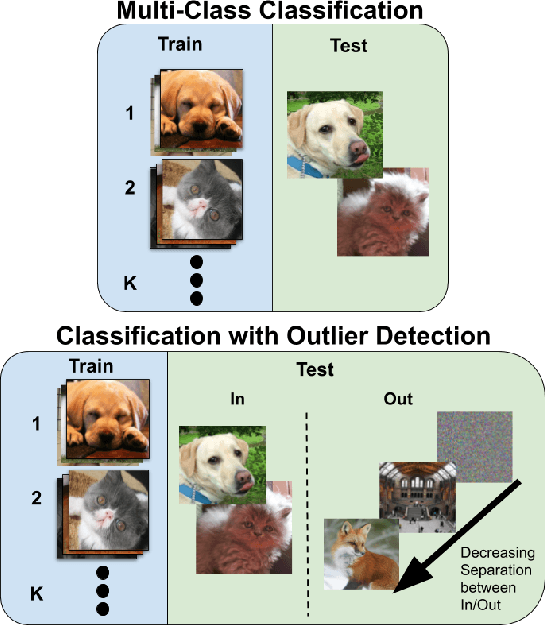

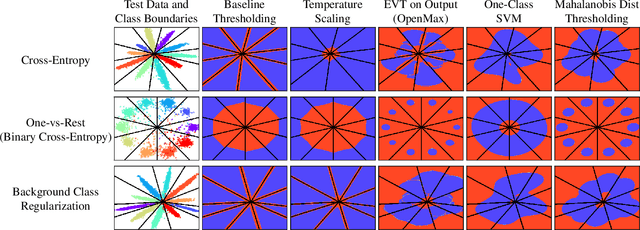
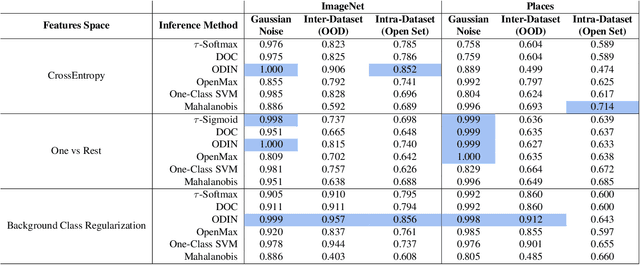
Supervised classification methods often assume the train and test data distributions are the same and that all classes in the test set are present in the training set. However, deployed classifiers often require the ability to recognize inputs from outside the training set as unknowns. This problem has been studied under multiple paradigms including out-of-distribution detection and open set recognition. For convolutional neural networks, there have been two major approaches: 1) inference methods to separate knowns from unknowns and 2) feature space regularization strategies to improve model robustness to outlier inputs. There has been little effort to explore the relationship between the two approaches and directly compare performance on anything other than small-scale datasets that have at most 100 categories. Using ImageNet-1K and Places-434, we identify novel combinations of regularization and specialized inference methods that perform best across multiple outlier detection problems of increasing difficulty level. We found that input perturbation and temperature scaling yield the best performance on large scale datasets regardless of the feature space regularization strategy. Improving the feature space by regularizing against a background class can be helpful if an appropriate background class can be found, but this is impractical for large scale image classification datasets.