 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Robustness to Open Set Inputs via Tempered Mixup
Paper and Code
Sep 10, 2020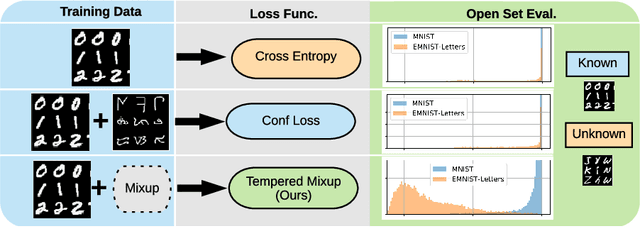
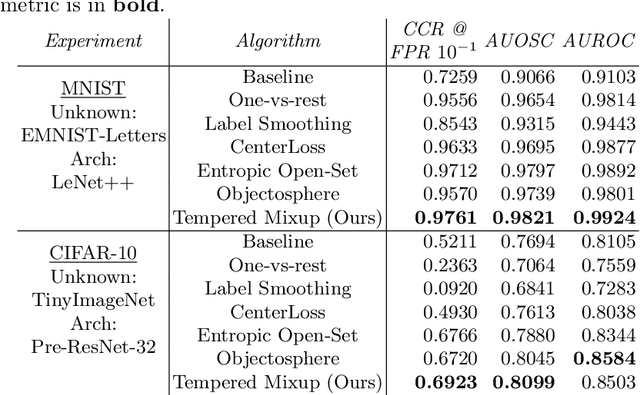
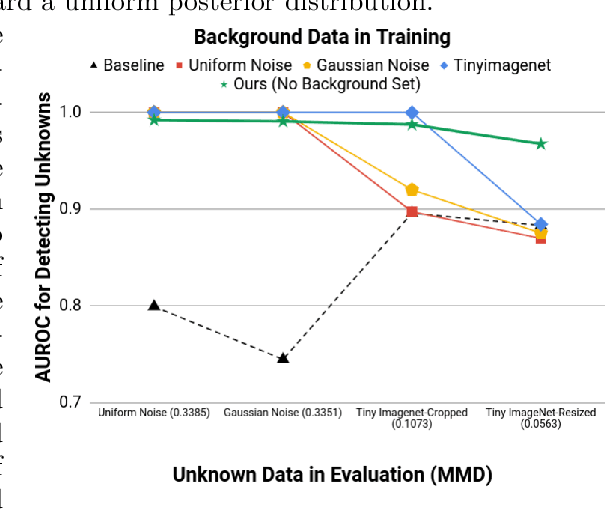
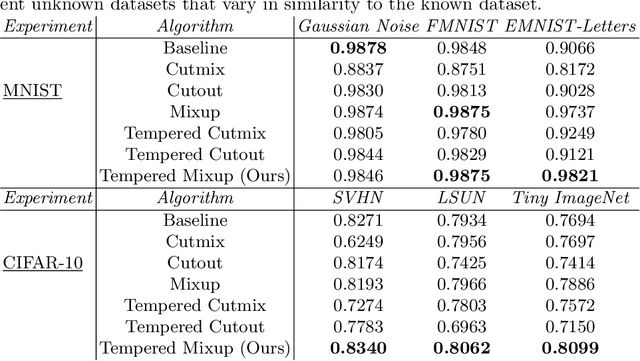
Supervised classification methods often assume that evaluation data is drawn from the same distribution as training data and that all classes are present for training. However, real-world classifiers must handle inputs that are far from the training distribution including samples from unknown classes. Open set robustness refers to the ability to properly label samples from previously unseen categories as novel and avoid high-confidence, incorrect predictions. Existing approaches have focused on either novel inference methods, unique training architectures, or supplementing the training data with additional background samples. Here, we propose a simple regularization technique easily applied to existing convolutional neural network architectures that improves open set robustness without a background dataset. Our method achieves state-of-the-art results on open set classification baselines and easily scales to large-scale open set classification problems.