 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHARP: Sleep-based Hierarchical Accelerated Replay for Long Range Non-Stationary Temporal Pattern Recognition
May 30, 2026Learning long-range non-stationary temporal patterns remains a core challenge for modern sequence models, particularly in strict streaming settings. In these settings, data arrive sequentially and must be processed in a single pass without simultaneously revisiting past observations. Standard architectures, including recurrent neural networks and transformers, are constrained by either truncated backpropagation through time horizon or explicit input window length for long range credit assignment. To address these limitations, we propose SHARP (Sleep-based Hierarchical Accelerated Replay), a framework that decomposes temporal learning into two complementary components: a memory module that accumulates a structured history of past inputs, and a pattern-recognition module that operates over this memory. This separation enables resource- and compute-efficient adaptation to non-stationary dynamics by eliminating the need for backpropagation through time across many steps for long-range credit assignment. Inspired by the accelerated replay observed in rodents during slow-wave sleep, SHARP incorporates offline (sleep) phases in which temporally structured memory traces are replayed in an accelerated form and integrated into higher-level memory representations, improving long-range context retention. Through controlled simulations and ablation studies, we characterize the key properties of the proposed framework. In benchmark datasets such as text8 and PG-19, we demonstrate that SHARP improves over recurrent baselines by retaining next-token predictive performance on previously seen data while continuing to learn from the current stream and generalizing to future unseen data. These gains are enabled by its hierarchical structure, which yields an exponentially increasing effective temporal context with only linear-time computational cost.
Modular Memory is the Key to Continual Learning Agents
Mar 02, 2026Foundation models have transformed machine learning through large-scale pretraining and increased test-time compute. Despite surpassing human performance in several domains, these models remain fundamentally limited in continuous operation, experience accumulation, and personalization, capabilities that are central to adaptive intelligence. While continual learning research has long targeted these goals, its historical focus on in-weight learning (IWL), i.e., updating a single model's parameters to absorb new knowledge, has rendered catastrophic forgetting a persistent challenge. Our position is that combining the strengths of In-Weight Learning (IWL) and the newly emerged capabilities of In-Context Learning (ICL) through the design of modular memory is the missing piece for continual adaptation at scale. We outline a conceptual framework for modular memory-centric architectures that leverage ICL for rapid adaptation and knowledge accumulation, and IWL for stable updates to model capabilities, charting a practical roadmap toward continually learning agents.
M2RU: Memristive Minion Recurrent Unit for On-Chip Continual Learning at the Edge
Dec 26, 2025Continual learning on edge platforms remains challenging because recurrent networks depend on energy-intensive training procedures and frequent data movement that are impractical for embedded deployments. This work introduces M2RU, a mixed-signal architecture that implements the minion recurrent unit for efficient temporal processing with on-chip continual learning. The architecture integrates weighted-bit streaming, which enables multi-bit digital inputs to be processed in crossbars without high-resolution conversion, and an experience replay mechanism that stabilizes learning under domain shifts. M2RU achieves 15 GOPS at 48.62 mW, corresponding to 312 GOPS per watt, and maintains accuracy within 5 percent of software baselines on sequential MNIST and CIFAR-10 tasks. Compared with a CMOS digital design, the accelerator provides 29X improvement in energy efficiency. Device-aware analysis shows an expected operational lifetime of 12.2 years under continual learning workloads. These results establish M2RU as a scalable and energy-efficient platform for real-time adaptation in edge-level temporal intelligence.
M2RU: Memristive Minion Recurrent Unit for Continual Learning at the Edge
Dec 19, 2025Continual learning on edge platforms remains challenging because recurrent networks depend on energy-intensive training procedures and frequent data movement that are impractical for embedded deployments. This work introduces M2RU, a mixed-signal architecture that implements the minion recurrent unit for efficient temporal processing with on-chip continual learning. The architecture integrates weighted-bit streaming, which enables multi-bit digital inputs to be processed in crossbars without high-resolution conversion, and an experience replay mechanism that stabilizes learning under domain shifts. M2RU achieves 15 GOPS at 48.62 mW, corresponding to 312 GOPS per watt, and maintains accuracy within 5 percent of software baselines on sequential MNIST and CIFAR-10 tasks. Compared with a CMOS digital design, the accelerator provides 29X improvement in energy efficiency. Device-aware analysis shows an expected operational lifetime of 12.2 years under continual learning workloads. These results establish M2RU as a scalable and energy-efficient platform for real-time adaptation in edge-level temporal intelligence.
Minion Gated Recurrent Unit for Continual Learning
Mar 08, 2025The increasing demand for continual learning in sequential data processing has led to progressively complex training methodologies and larger recurrent network architectures. Consequently, this has widened the knowledge gap between continual learning with recurrent neural networks (RNNs) and their ability to operate on devices with limited memory and compute. To address this challenge, we investigate the effectiveness of simplifying RNN architectures, particularly gated recurrent unit (GRU), and its impact on both single-task and multitask sequential learning. We propose a new variant of GRU, namely the minion recurrent unit (MiRU). MiRU replaces conventional gating mechanisms with scaling coefficients to regulate dynamic updates of hidden states and historical context, reducing computational costs and memory requirements. Despite its simplified architecture, MiRU maintains performance comparable to the standard GRU while achieving 2.90x faster training and reducing parameter usage by 2.88x, as demonstrated through evaluations on sequential image classification and natural language processing benchmarks. The impact of model simplification on its learning capacity is also investigated by performing continual learning tasks with a rehearsal-based strategy and global inhibition. We find that MiRU demonstrates stable performance in multitask learning even when using only rehearsal, unlike the standard GRU and its variants. These features position MiRU as a promising candidate for edge-device applications.
Time-Series Forecasting and Sequence Learning Using Memristor-based Reservoir System
May 22, 2024Pushing the frontiers of time-series information processing in ever-growing edge devices with stringent resources has been impeded by the system's ability to process information and learn locally on the device. Local processing and learning typically demand intensive computations and massive storage as the process involves retrieving information and tuning hundreds of parameters back in time. In this work, we developed a memristor-based echo state network accelerator that features efficient temporal data processing and in-situ online learning. The proposed design is benchmarked using various datasets involving real-world tasks, such as forecasting the load energy consumption and weather conditions. The experimental results illustrate that the hardware model experiences a marginal degradation (~4.8%) in performance as compared to the software model. This is mainly attributed to the limited precision and dynamic range of network parameters when emulated using memristor devices. The proposed system is evaluated for lifespan, robustness, and energy-delay product. It is observed that the system demonstrates a reasonable robustness for device failure below 10%, which may occur due to stuck-at faults. Furthermore, 246X reduction in energy consumption is achieved when compared to a custom CMOS digital design implemented at the same technology node.
Watch Your Step: Optimal Retrieval for Continual Learning at Scale
Apr 16, 2024
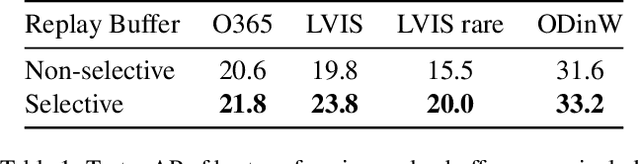
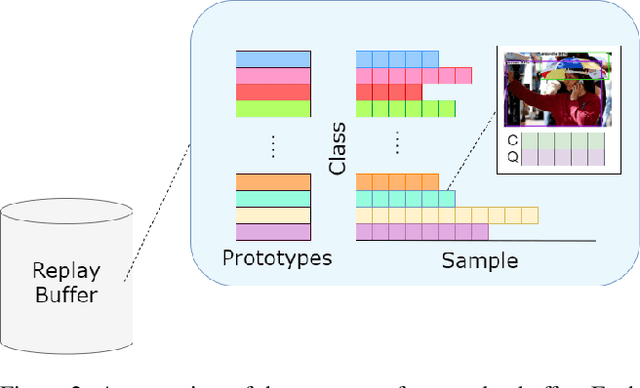
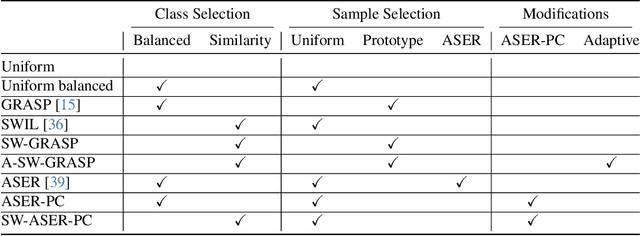
One of the most widely used approaches in continual learning is referred to as replay. Replay methods support interleaved learning by storing past experiences in a replay buffer. Although there are methods for selectively constructing the buffer and reprocessing its contents, there is limited exploration of the problem of selectively retrieving samples from the buffer. Current solutions have been tested in limited settings and, more importantly, in isolation. Existing work has also not explored the impact of duplicate replays on performance. In this work, we propose a framework for evaluating selective retrieval strategies, categorized by simple, independent class- and sample-selective primitives. We evaluated several combinations of existing strategies for selective retrieval and present their performances. Furthermore, we propose a set of strategies to prevent duplicate replays and explore whether new samples with low loss values can be learned without replay. In an effort to match our problem setting to a realistic continual learning pipeline, we restrict our experiments to a setting involving a large, pre-trained, open vocabulary object detection model, which is fully fine-tuned on a sequence of 15 datasets.
Continual Learning and Catastrophic Forgetting
Mar 08, 2024


This book chapter delves into the dynamics of continual learning, which is the process of incrementally learning from a non-stationary stream of data. Although continual learning is a natural skill for the human brain, it is very challenging for artificial neural networks. An important reason is that, when learning something new, these networks tend to quickly and drastically forget what they had learned before, a phenomenon known as catastrophic forgetting. Especially in the last decade, continual learning has become an extensively studied topic in deep learning. This book chapter reviews the insights that this field has generated.
Continual Learning: Applications and the Road Forward
Nov 21, 2023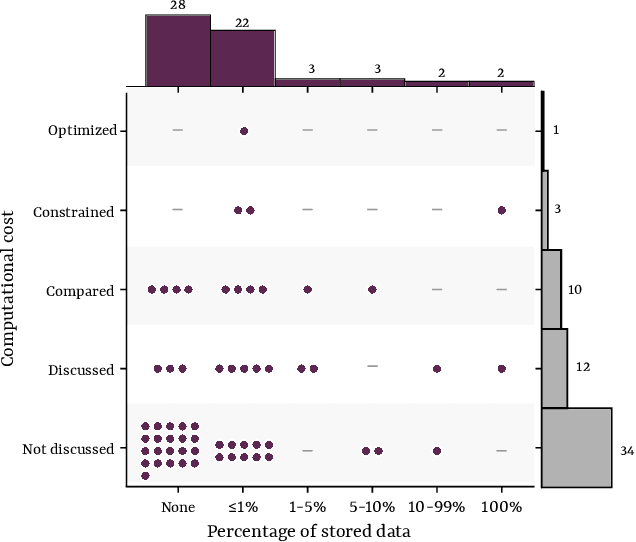
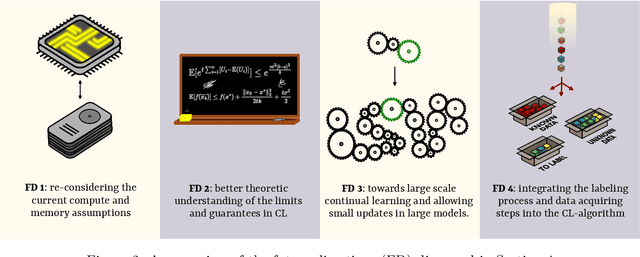
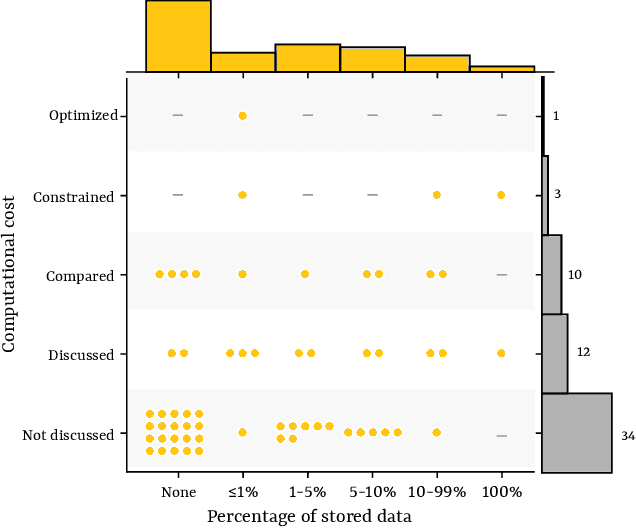
Continual learning is a sub-field of machine learning, which aims to allow machine learning models to continuously learn on new data, by accumulating knowledge without forgetting what was learned in the past. In this work, we take a step back, and ask: "Why should one care about continual learning in the first place?". We set the stage by surveying recent continual learning papers published at three major machine learning conferences, and show that memory-constrained settings dominate the field. Then, we discuss five open problems in machine learning, and even though they seem unrelated to continual learning at first sight, we show that continual learning will inevitably be part of their solution. These problems are model-editing, personalization, on-device learning, faster (re-)training and reinforcement learning. Finally, by comparing the desiderata from these unsolved problems and the current assumptions in continual learning, we highlight and discuss four future directions for continual learning research. We hope that this work offers an interesting perspective on the future of continual learning, while displaying its potential value and the paths we have to pursue in order to make it successful. This work is the result of the many discussions the authors had at the Dagstuhl seminar on Deep Continual Learning, in March 2023.
Design Principles for Lifelong Learning AI Accelerators
Oct 05, 2023Lifelong learning - an agent's ability to learn throughout its lifetime - is a hallmark of biological learning systems and a central challenge for artificial intelligence (AI). The development of lifelong learning algorithms could lead to a range of novel AI applications, but this will also require the development of appropriate hardware accelerators, particularly if the models are to be deployed on edge platforms, which have strict size, weight, and power constraints. Here, we explore the design of lifelong learning AI accelerators that are intended for deployment in untethered environments. We identify key desirable capabilities for lifelong learning accelerators and highlight metrics to evaluate such accelerators. We then discuss current edge AI accelerators and explore the future design of lifelong learning accelerators, considering the role that different emerging technologies could play.