Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTENT: Efficient Quantization of Neural Networks on the tiny Edge with Tapered FixEd PoiNT
Paper and Code
Apr 06, 2021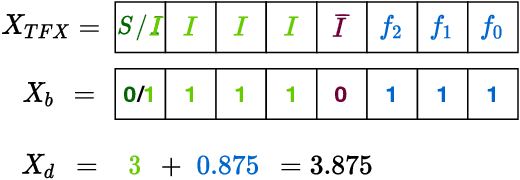
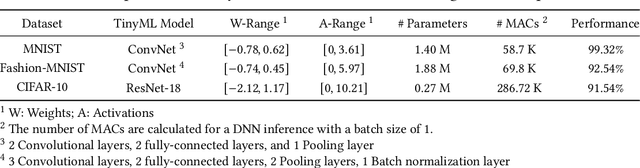
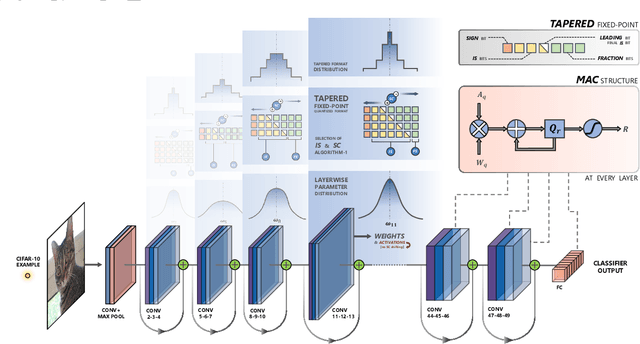
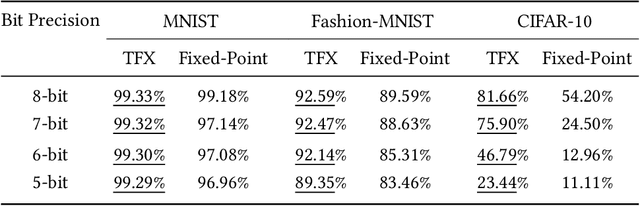
In this research, we propose a new low-precision framework, TENT, to leverage the benefits of a tapered fixed-point numerical format in TinyML models. We introduce a tapered fixed-point quantization algorithm that matches the numerical format's dynamic range and distribution to that of the deep neural network model's parameter distribution at each layer. An accelerator architecture for the tapered fixed-point with TENT framework is proposed. Results show that the accuracy on classification tasks improves up to ~31 % with an energy overhead of ~17-30 % as compared to fixed-point, for ConvNet and ResNet-18 models.
* poster presented at the first tinyML Research Symposium, March 26,
2021
View paper on
 OpenReview
OpenReview