 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTENT: Efficient Quantization of Neural Networks on the tiny Edge with Tapered FixEd PoiNT
Apr 06, 2021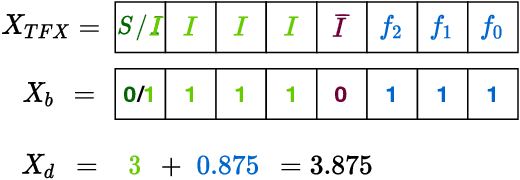
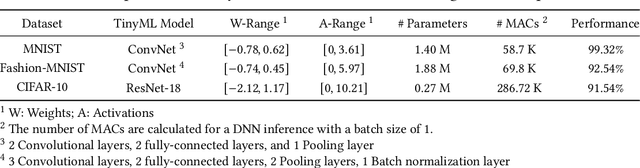
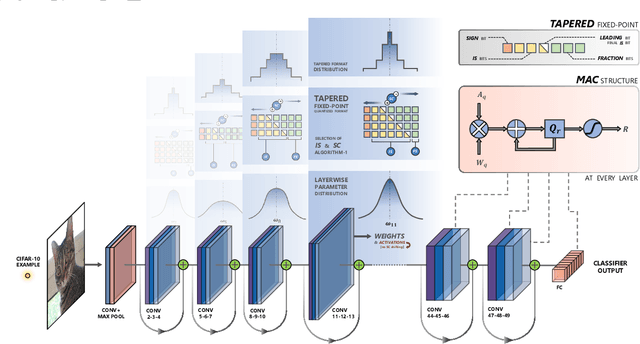
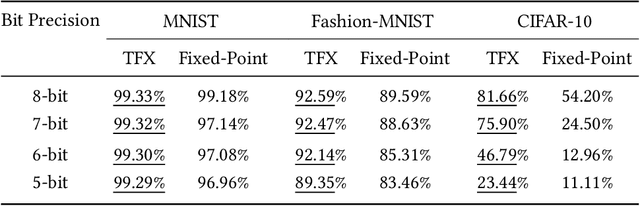
In this research, we propose a new low-precision framework, TENT, to leverage the benefits of a tapered fixed-point numerical format in TinyML models. We introduce a tapered fixed-point quantization algorithm that matches the numerical format's dynamic range and distribution to that of the deep neural network model's parameter distribution at each layer. An accelerator architecture for the tapered fixed-point with TENT framework is proposed. Results show that the accuracy on classification tasks improves up to ~31 % with an energy overhead of ~17-30 % as compared to fixed-point, for ConvNet and ResNet-18 models.
Deep Learning Inference on Embedded Devices: Fixed-Point vs Posit
May 22, 2018



Performing the inference step of deep learning in resource constrained environments, such as embedded devices, is challenging. Success requires optimization at both software and hardware levels. Low precision arithmetic and specifically low precision fixed-point number systems have become the standard for performing deep learning inference. However, representing non-uniform data and distributed parameters (e.g. weights) by using uniformly distributed fixed-point values is still a major drawback when using this number system. Recently, the posit number system was proposed, which represents numbers in a non-uniform manner. Therefore, in this paper we are motivated to explore using the posit number system to represent the weights of Deep Convolutional Neural Networks. However, we do not apply any quantization techniques and hence the network weights do not require re-training. The results of this exploration show that using the posit number system outperformed the fixed point number system in terms of accuracy and memory utilization.