 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTENT: Efficient Quantization of Neural Networks on the tiny Edge with Tapered FixEd PoiNT
Apr 06, 2021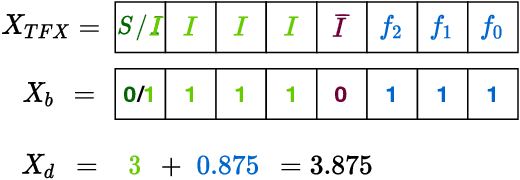
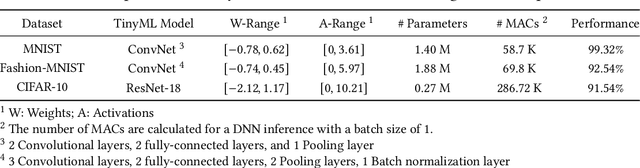
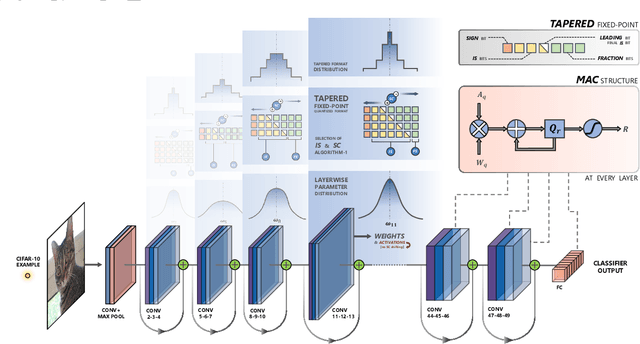
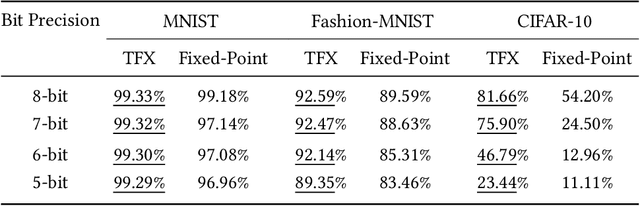
In this research, we propose a new low-precision framework, TENT, to leverage the benefits of a tapered fixed-point numerical format in TinyML models. We introduce a tapered fixed-point quantization algorithm that matches the numerical format's dynamic range and distribution to that of the deep neural network model's parameter distribution at each layer. An accelerator architecture for the tapered fixed-point with TENT framework is proposed. Results show that the accuracy on classification tasks improves up to ~31 % with an energy overhead of ~17-30 % as compared to fixed-point, for ConvNet and ResNet-18 models.
Cheetah: Mixed Low-Precision Hardware & Software Co-Design Framework for DNNs on the Edge
Aug 06, 2019Low-precision DNNs have been extensively explored in order to reduce the size of DNN models for edge devices. Recently, the posit numerical format has shown promise for DNN data representation and compute with ultra-low precision in [5..8]-bits. However, previous studies were limited to studying posit for DNN inference only. In this paper, we propose the Cheetah framework, which supports both DNN training and inference using posits, as well as other commonly used formats. Additionally, the framework is amenable for different quantization approaches and supports mixed-precision floating point and fixed-point numerical formats. Cheetah is evaluated on three datasets: MNIST, Fashion MNIST, and CIFAR-10. Results indicate that 16-bit posits outperform 16-bit floating point in DNN training. Furthermore, performing inference with [5..8]-bit posits improves the trade-off between performance and energy-delay-product over both [5..8]-bit float and fixed-point.
Deep Learning Training on the Edge with Low-Precision Posits
Jul 30, 2019
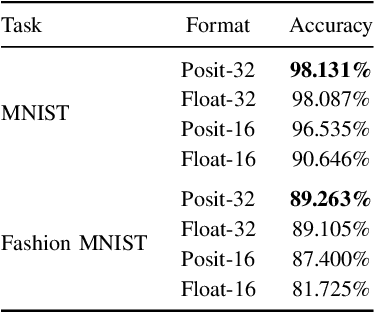

Recently, the posit numerical format has shown promise for DNN data representation and compute with ultra-low precision ([5..8]-bit). However, majority of studies focus only on DNN inference. In this work, we propose DNN training using posits and compare with the floating point training. We evaluate on both MNIST and Fashion MNIST corpuses, where 16-bit posits outperform 16-bit floating point for end-to-end DNN training.
Performance-Efficiency Trade-off of Low-Precision Numerical Formats in Deep Neural Networks
Mar 25, 2019Deep neural networks (DNNs) have been demonstrated as effective prognostic models across various domains, e.g. natural language processing, computer vision, and genomics. However, modern-day DNNs demand high compute and memory storage for executing any reasonably complex task. To optimize the inference time and alleviate the power consumption of these networks, DNN accelerators with low-precision representations of data and DNN parameters are being actively studied. An interesting research question is in how low-precision networks can be ported to edge-devices with similar performance as high-precision networks. In this work, we employ the fixed-point, floating point, and posit numerical formats at $\leq$8-bit precision within a DNN accelerator, Deep Positron, with exact multiply-and-accumulate (EMAC) units for inference. A unified analysis quantifies the trade-offs between overall network efficiency and performance across five classification tasks. Our results indicate that posits are a natural fit for DNN inference, outperforming at $\leq$8-bit precision, and can be realized with competitive resource requirements relative to those of floating point.
Deep Positron: A Deep Neural Network Using the Posit Number System
Jan 19, 2019



The recent surge of interest in Deep Neural Networks (DNNs) has led to increasingly complex networks that tax computational and memory resources. Many DNNs presently use 16-bit or 32-bit floating point operations. Significant performance and power gains can be obtained when DNN accelerators support low-precision numerical formats. Despite considerable research, there is still a knowledge gap on how low-precision operations can be realized for both DNN training and inference. In this work, we propose a DNN architecture, Deep Positron, with posit numerical format operating successfully at $\leq$8 bits for inference. We propose a precision-adaptable FPGA soft core for exact multiply-and-accumulate for uniform comparison across three numerical formats, fixed, floating-point and posit. Preliminary results demonstrate that 8-bit posit has better accuracy than 8-bit fixed or floating-point for three different low-dimensional datasets. Moreover, the accuracy is comparable to 32-bit floating-point on a Xilinx Virtex-7 FPGA device. The trade-offs between DNN performance and hardware resources, i.e. latency, power, and resource utilization, show that posit outperforms in accuracy and latency at 8-bit and below.