Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning Training on the Edge with Low-Precision Posits
Paper and Code
Jul 30, 2019
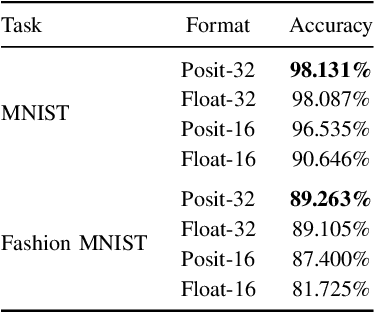

Recently, the posit numerical format has shown promise for DNN data representation and compute with ultra-low precision ([5..8]-bit). However, majority of studies focus only on DNN inference. In this work, we propose DNN training using posits and compare with the floating point training. We evaluate on both MNIST and Fashion MNIST corpuses, where 16-bit posits outperform 16-bit floating point for end-to-end DNN training.
View paper on