 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Learning and Catastrophic Forgetting
Mar 08, 2024


This book chapter delves into the dynamics of continual learning, which is the process of incrementally learning from a non-stationary stream of data. Although continual learning is a natural skill for the human brain, it is very challenging for artificial neural networks. An important reason is that, when learning something new, these networks tend to quickly and drastically forget what they had learned before, a phenomenon known as catastrophic forgetting. Especially in the last decade, continual learning has become an extensively studied topic in deep learning. This book chapter reviews the insights that this field has generated.
Design Principles for Lifelong Learning AI Accelerators
Oct 05, 2023Lifelong learning - an agent's ability to learn throughout its lifetime - is a hallmark of biological learning systems and a central challenge for artificial intelligence (AI). The development of lifelong learning algorithms could lead to a range of novel AI applications, but this will also require the development of appropriate hardware accelerators, particularly if the models are to be deployed on edge platforms, which have strict size, weight, and power constraints. Here, we explore the design of lifelong learning AI accelerators that are intended for deployment in untethered environments. We identify key desirable capabilities for lifelong learning accelerators and highlight metrics to evaluate such accelerators. We then discuss current edge AI accelerators and explore the future design of lifelong learning accelerators, considering the role that different emerging technologies could play.
Metaplasticity in Multistate Memristor Synaptic Networks
Feb 26, 2020

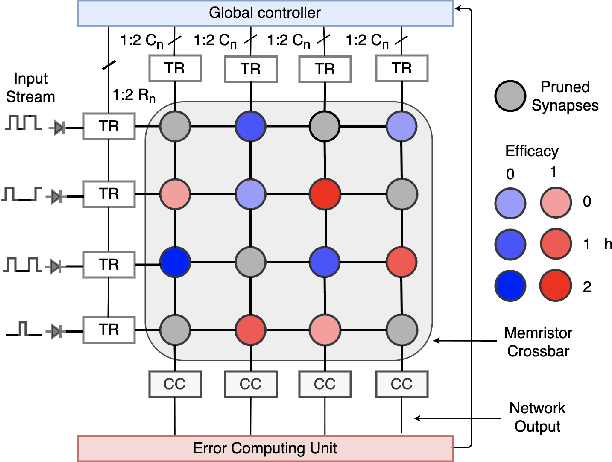
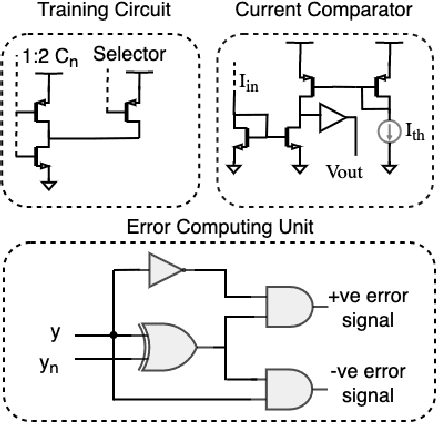
Recent studies have shown that metaplastic synapses can retain information longer than simple binary synapses and are beneficial for continual learning. In this paper, we explore the multistate metaplastic synapse characteristics in the context of high retention and reception of information. Inherent behavior of a memristor emulating the multistate synapse is employed to capture the metaplastic behavior. An integrated neural network study for learning and memory retention is performed by integrating the synapse in a $5\times3$ crossbar at the circuit level and $128\times128$ network at the architectural level. An on-device training circuitry ensures the dynamic learning in the network. In the $128\times128$ network, it is observed that the number of input patterns the multistate synapse can classify is $\simeq$ 2.1x that of a simple binary synapse model, at a mean accuracy of $\geq$ 75% .